 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Mechanistic Circuits for Extractive Question-Answering
Feb 12, 2025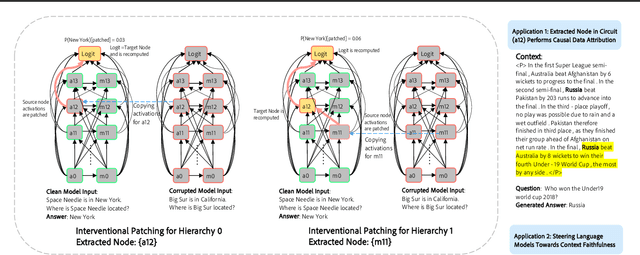
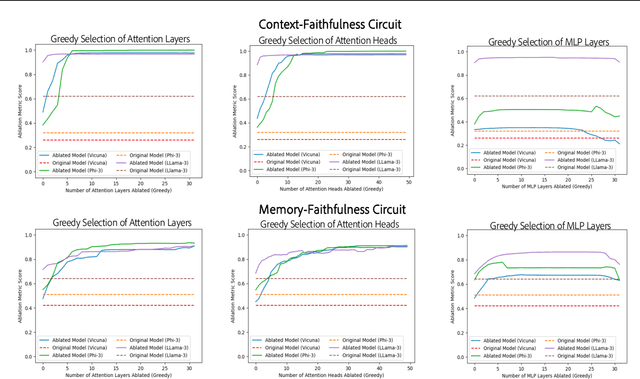
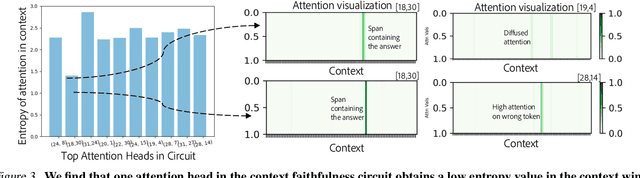
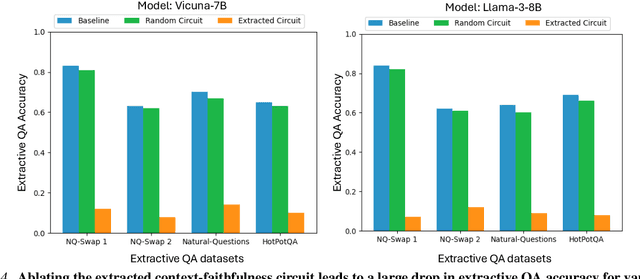
Large language models are increasingly used to process documents and facilitate question-answering on them. In our paper, we extract mechanistic circuits for this real-world language modeling task: context-augmented language modeling for extractive question-answering (QA) tasks and understand the potential benefits of circuits towards downstream applications such as data attribution to context information. We extract circuits as a function of internal model components (e.g., attention heads, MLPs) using causal mediation analysis techniques. Leveraging the extracted circuits, we first understand the interplay between the model's usage of parametric memory and retrieved context towards a better mechanistic understanding of context-augmented language models. We then identify a small set of attention heads in our circuit which performs reliable data attribution by default, thereby obtaining attribution for free in just the model's forward pass. Using this insight, we then introduce ATTNATTRIB, a fast data attribution algorithm which obtains state-of-the-art attribution results across various extractive QA benchmarks. Finally, we show the possibility to steer the language model towards answering from the context, instead of the parametric memory by using the attribution from ATTNATTRIB as an additional signal during the forward pass. Beyond mechanistic understanding, our paper provides tangible applications of circuits in the form of reliable data attribution and model steering.
On Mechanistic Knowledge Localization in Text-to-Image Generative Models
May 02, 2024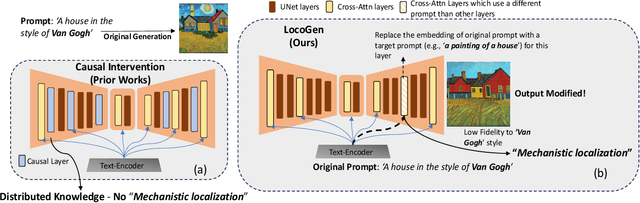
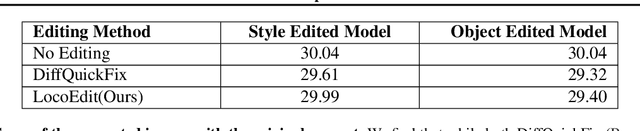
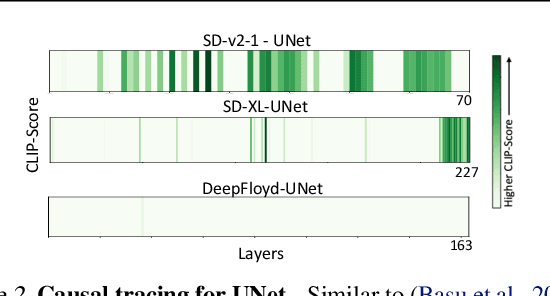
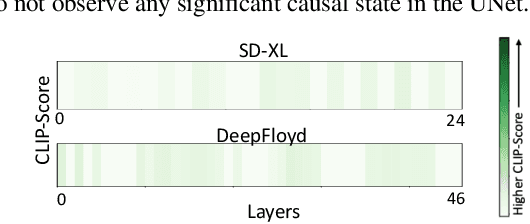
Identifying layers within text-to-image models which control visual attributes can facilitate efficient model editing through closed-form updates. Recent work, leveraging causal tracing show that early Stable-Diffusion variants confine knowledge primarily to the first layer of the CLIP text-encoder, while it diffuses throughout the UNet.Extending this framework, we observe that for recent models (e.g., SD-XL, DeepFloyd), causal tracing fails in pinpointing localized knowledge, highlighting challenges in model editing. To address this issue, we introduce the concept of Mechanistic Localization in text-to-image models, where knowledge about various visual attributes (e.g., ``style", ``objects", ``facts") can be mechanistically localized to a small fraction of layers in the UNet, thus facilitating efficient model editing. We localize knowledge using our method LocoGen which measures the direct effect of intermediate layers to output generation by performing interventions in the cross-attention layers of the UNet. We then employ LocoEdit, a fast closed-form editing method across popular open-source text-to-image models (including the latest SD-XL)and explore the possibilities of neuron-level model editing. Using Mechanistic Localization, our work offers a better view of successes and failures in localization-based text-to-image model editing. Code will be available at \href{https://github.com/samyadeepbasu/LocoGen}{https://github.com/samyadeepbasu/LocoGen}.
Localizing and Editing Knowledge in Text-to-Image Generative Models
Oct 20, 2023Text-to-Image Diffusion Models such as Stable-Diffusion and Imagen have achieved unprecedented quality of photorealism with state-of-the-art FID scores on MS-COCO and other generation benchmarks. Given a caption, image generation requires fine-grained knowledge about attributes such as object structure, style, and viewpoint amongst others. Where does this information reside in text-to-image generative models? In our paper, we tackle this question and understand how knowledge corresponding to distinct visual attributes is stored in large-scale text-to-image diffusion models. We adapt Causal Mediation Analysis for text-to-image models and trace knowledge about distinct visual attributes to various (causal) components in the (i) UNet and (ii) text-encoder of the diffusion model. In particular, we show that unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes. Remarkably, we find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers. Based on this observation of only one causal state in the text-encoder, we introduce a fast, data-free model editing method Diff-QuickFix which can effectively edit concepts in text-to-image models. DiffQuickFix can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning based editing methods.
End-to-end Document Recognition and Understanding with Dessurt
Mar 30, 2022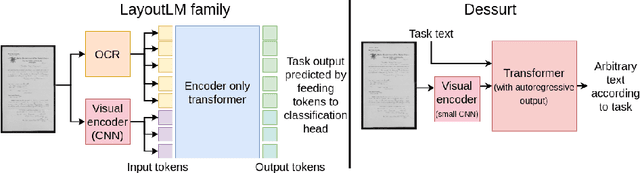


We introduce Dessurt, a relatively simple document understanding transformer capable of being fine-tuned on a greater variety of document tasks than prior methods. It receives a document image and task string as input and generates arbitrary text autoregressively as output. Because Dessurt is an end-to-end architecture that performs text recognition in addition to the document understanding, it does not require an external recognition model as prior methods do, making it easier to fine-tune to new visual domains. We show that this model is effective at 9 different dataset-task combinations.
IGA : An Intent-Guided Authoring Assistant
Apr 14, 2021
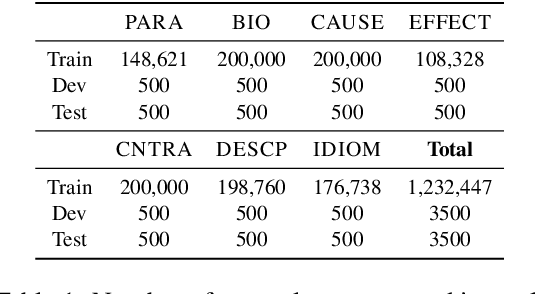


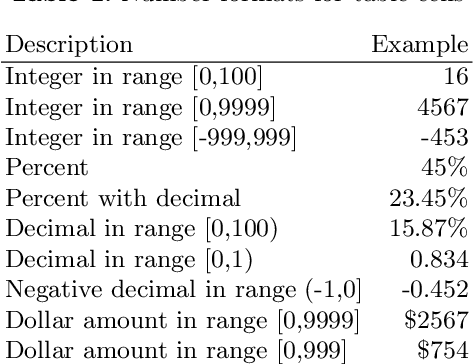
While large-scale pretrained language models have significantly improved writing assistance functionalities such as autocomplete, more complex and controllable writing assistants have yet to be explored. We leverage advances in language modeling to build an interactive writing assistant that generates and rephrases text according to fine-grained author specifications. Users provide input to our Intent-Guided Assistant (IGA) in the form of text interspersed with tags that correspond to specific rhetorical directives (e.g., adding description or contrast, or rephrasing a particular sentence). We fine-tune a language model on a dataset heuristically-labeled with author intent, which allows IGA to fill in these tags with generated text that users can subsequently edit to their liking. A series of automatic and crowdsourced evaluations confirm the quality of IGA's generated outputs, while a small-scale user study demonstrates author preference for IGA over baseline methods in a creative writing task. We release our dataset, code, and demo to spur further research into AI-assisted writing.