 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Conditioned Background Generation for Editable Multi-Layer Documents
Dec 19, 2025



We present a framework for document-centric background generation with multi-page editing and thematic continuity. To ensure text regions remain readable, we employ a \emph{latent masking} formulation that softly attenuates updates in the diffusion space, inspired by smooth barrier functions in physics and numerical optimization. In addition, we introduce \emph{Automated Readability Optimization (ARO)}, which automatically places semi-transparent, rounded backing shapes behind text regions. ARO determines the minimal opacity needed to satisfy perceptual contrast standards (WCAG 2.2) relative to the underlying background, ensuring readability while maintaining aesthetic harmony without human intervention. Multi-page consistency is maintained through a summarization-and-instruction process, where each page is distilled into a compact representation that recursively guides subsequent generations. This design reflects how humans build continuity by retaining prior context, ensuring that visual motifs evolve coherently across an entire document. Our method further treats a document as a structured composition in which text, figures, and backgrounds are preserved or regenerated as separate layers, allowing targeted background editing without compromising readability. Finally, user-provided prompts allow stylistic adjustments in color and texture, balancing automated consistency with flexible customization. Our training-free framework produces visually coherent, text-preserving, and thematically aligned documents, bridging generative modeling with natural design workflows.
DocumentCLIP: Linking Figures and Main Body Text in Reflowed Documents
Jun 09, 2023Vision-language pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding single image associated with a single piece of text, they often ignore the alignment at the intra-document level, consisting of multiple sentences with multiple images. In this work, we propose DocumentCLIP, a salience-aware contrastive learning framework to enforce vision-language pretraining models to comprehend the interaction between images and longer text within documents. Our model is beneficial for the real-world multimodal document understanding like news article, magazines, product descriptions, which contain linguistically and visually richer content. To the best of our knowledge, we are the first to explore multimodal intra-document links by contrastive learning. In addition, we collect a large Wikipedia dataset for pretraining, which provides various topics and structures. Experiments show DocumentCLIP not only outperforms the state-of-the-art baselines in the supervised setting, but also achieves the best zero-shot performance in the wild after human evaluation. Our code is available at https://github.com/FuxiaoLiu/DocumentCLIP.
MGDoc: Pre-training with Multi-granular Hierarchy for Document Image Understanding
Nov 27, 2022Document images are a ubiquitous source of data where the text is organized in a complex hierarchical structure ranging from fine granularity (e.g., words), medium granularity (e.g., regions such as paragraphs or figures), to coarse granularity (e.g., the whole page). The spatial hierarchical relationships between content at different levels of granularity are crucial for document image understanding tasks. Existing methods learn features from either word-level or region-level but fail to consider both simultaneously. Word-level models are restricted by the fact that they originate from pure-text language models, which only encode the word-level context. In contrast, region-level models attempt to encode regions corresponding to paragraphs or text blocks into a single embedding, but they perform worse with additional word-level features. To deal with these issues, we propose MGDoc, a new multi-modal multi-granular pre-training framework that encodes page-level, region-level, and word-level information at the same time. MGDoc uses a unified text-visual encoder to obtain multi-modal features across different granularities, which makes it possible to project the multi-granular features into the same hyperspace. To model the region-word correlation, we design a cross-granular attention mechanism and specific pre-training tasks for our model to reinforce the model of learning the hierarchy between regions and words. Experiments demonstrate that our proposed model can learn better features that perform well across granularities and lead to improvements in downstream tasks.
End-to-end Document Recognition and Understanding with Dessurt
Mar 30, 2022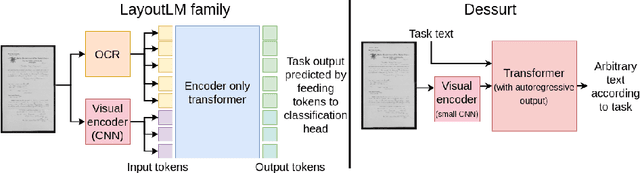


We introduce Dessurt, a relatively simple document understanding transformer capable of being fine-tuned on a greater variety of document tasks than prior methods. It receives a document image and task string as input and generates arbitrary text autoregressively as output. Because Dessurt is an end-to-end architecture that performs text recognition in addition to the document understanding, it does not require an external recognition model as prior methods do, making it easier to fine-tune to new visual domains. We show that this model is effective at 9 different dataset-task combinations.
LAFITE: Towards Language-Free Training for Text-to-Image Generation
Dec 13, 2021



One of the major challenges in training text-to-image generation models is the need of a large number of high-quality image-text pairs. While image samples are often easily accessible, the associated text descriptions typically require careful human captioning, which is particularly time- and cost-consuming. In this paper, we propose the first work to train text-to-image generation models without any text data. Our method leverages the well-aligned multi-modal semantic space of the powerful pre-trained CLIP model: the requirement of text-conditioning is seamlessly alleviated via generating text features from image features. Extensive experiments are conducted to illustrate the effectiveness of the proposed method. We obtain state-of-the-art results in the standard text-to-image generation tasks. Importantly, the proposed language-free model outperforms most existing models trained with full image-text pairs. Furthermore, our method can be applied in fine-tuning pre-trained models, which saves both training time and cost in training text-to-image generation models. Our pre-trained model obtains competitive results in zero-shot text-to-image generation on the MS-COCO dataset, yet with around only 1% of the model size and training data size relative to the recently proposed large DALL-E model.
RPCL: A Framework for Improving Cross-Domain Detection with Auxiliary Tasks
Apr 18, 2021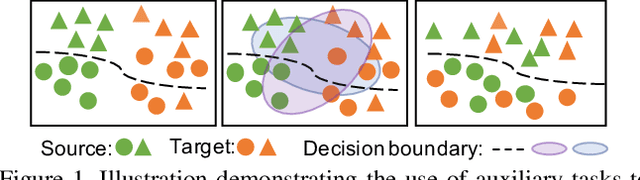
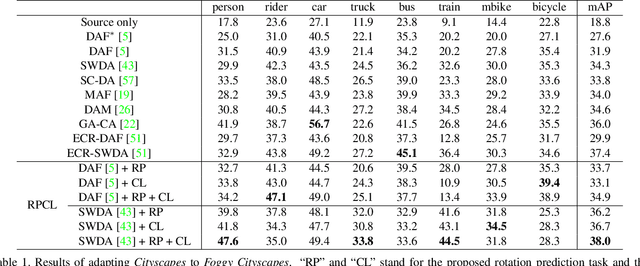
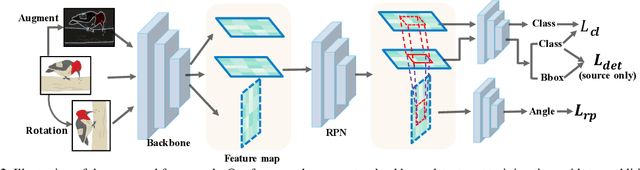
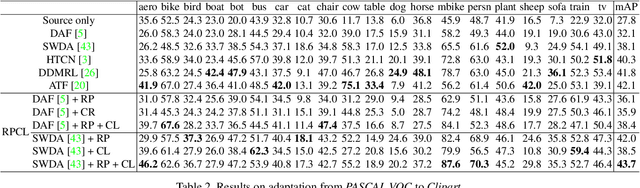
Cross-Domain Detection (XDD) aims to train an object detector using labeled image from a source domain but have good performance in the target domain with only unlabeled images. Existing approaches achieve this either by aligning the feature maps or the region proposals from the two domains, or by transferring the style of source images to that of target image. Contrasted with prior work, this paper provides a complementary solution to align domains by learning the same auxiliary tasks in both domains simultaneously. These auxiliary tasks push image from both domains towards shared spaces, which bridges the domain gap. Specifically, this paper proposes Rotation Prediction and Consistency Learning (PRCL), a framework complementing existing XDD methods for domain alignment by leveraging the two auxiliary tasks. The first one encourages the model to extract region proposals from foreground regions by rotating an image and predicting the rotation angle from the extracted region proposals. The second task encourages the model to be robust to changes in the image space by optimizing the model to make consistent class predictions for region proposals regardless of image perturbations. Experiments show the detection performance can be consistently and significantly enhanced by applying the two proposed tasks to existing XDD methods.
Text and Style Conditioned GAN for Generation of Offline Handwriting Lines
Sep 01, 2020
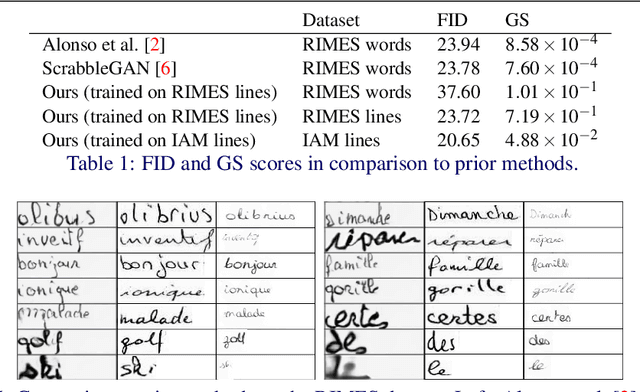
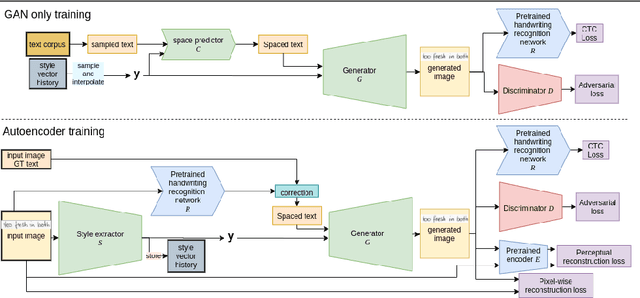
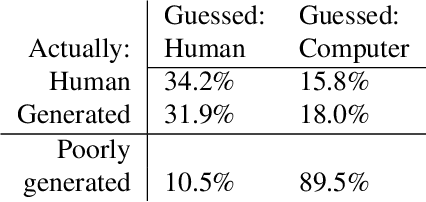
This paper presents a GAN for generating images of handwritten lines conditioned on arbitrary text and latent style vectors. Unlike prior work, which produce stroke points or single-word images, this model generates entire lines of offline handwriting. The model produces variable-sized images by using style vectors to determine character widths. A generator network is trained with GAN and autoencoder techniques to learn style, and uses a pre-trained handwriting recognition network to induce legibility. A study using human evaluators demonstrates that the model produces images that appear to be written by a human. After training, the encoder network can extract a style vector from an image, allowing images in a similar style to be generated, but with arbitrary text.
Cross-Domain Document Object Detection: Benchmark Suite and Method
Mar 30, 2020
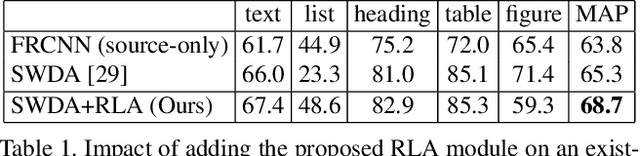
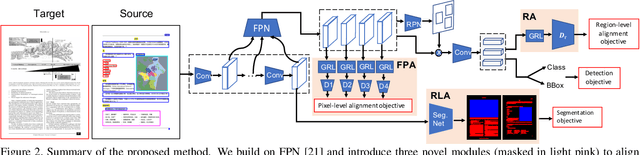
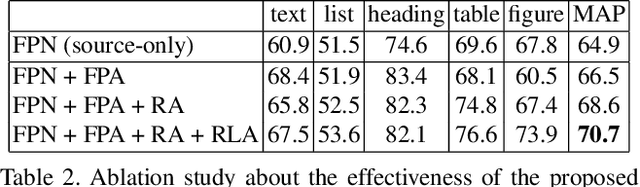
Decomposing images of document pages into high-level semantic regions (e.g., figures, tables, paragraphs), document object detection (DOD) is fundamental for downstream tasks like intelligent document editing and understanding. DOD remains a challenging problem as document objects vary significantly in layout, size, aspect ratio, texture, etc. An additional challenge arises in practice because large labeled training datasets are only available for domains that differ from the target domain. We investigate cross-domain DOD, where the goal is to learn a detector for the target domain using labeled data from the source domain and only unlabeled data from the target domain. Documents from the two domains may vary significantly in layout, language, and genre. We establish a benchmark suite consisting of different types of PDF document datasets that can be utilized for cross-domain DOD model training and evaluation. For each dataset, we provide the page images, bounding box annotations, PDF files, and the rendering layers extracted from the PDF files. Moreover, we propose a novel cross-domain DOD model which builds upon the standard detection model and addresses domain shifts by incorporating three novel alignment modules: Feature Pyramid Alignment (FPA) module, Region Alignment (RA) module and Rendering Layer alignment (RLA) module. Extensive experiments on the benchmark suite substantiate the efficacy of the three proposed modules and the proposed method significantly outperforms the baseline methods. The project page is at \url{https://github.com/kailigo/cddod}.
Deep Visual Template-Free Form Parsing
Sep 18, 2019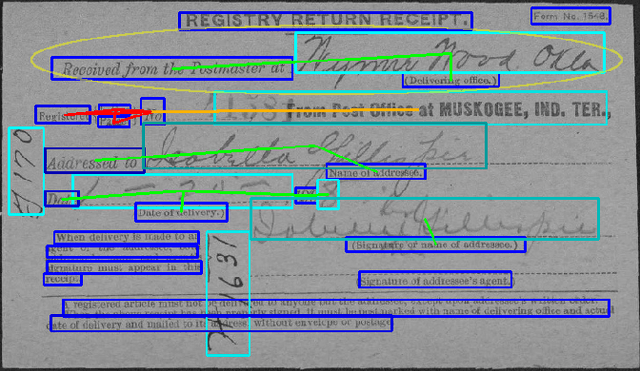


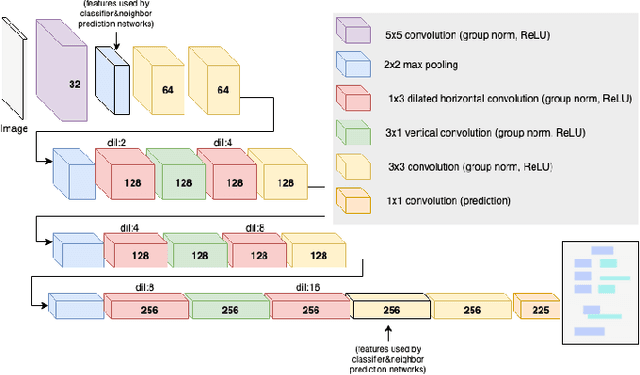
Automatic, template-free extraction of information from form images is challenging due to the variety of form layouts. This is even more challenging for historical forms due to noise and degradation. A crucial part of the extraction process is associating input text with pre-printed labels. We present a learned, template-free solution to detecting pre-printed text and input text/handwriting and predicting pair-wise relationships between them. While previous approaches to this problem have been focused on clean images and clear layouts, we show our approach is effective in the domain of noisy, degraded, and varied form images. We introduce a new dataset of historical form images (late 1800s, early 1900s) for training and validating our approach. Our method uses a convolutional network to detect pre-printed text and input text lines. We pool features from the detection network to classify possible relationships in a language-agnostic way. We show that our proposed pairing method outperforms heuristic rules and that visual features are critical to obtaining high accuracy.
Language Model Supervision for Handwriting Recognition Model Adaptation
Aug 04, 2018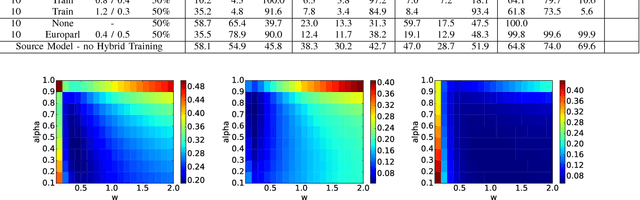
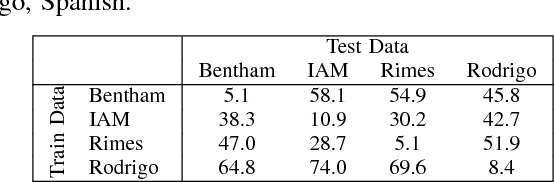
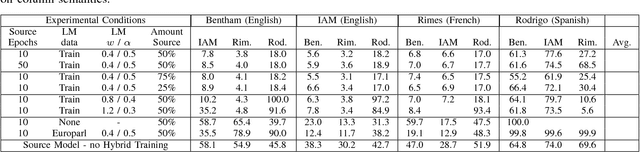
Training state-of-the-art offline handwriting recognition (HWR) models requires large labeled datasets, but unfortunately such datasets are not available in all languages and domains due to the high cost of manual labeling.We address this problem by showing how high resource languages can be leveraged to help train models for low resource languages.We propose a transfer learning methodology where we adapt HWR models trained on a source language to a target language that uses the same writing script.This methodology only requires labeled data in the source language, unlabeled data in the target language, and a language model of the target language. The language model is used in a bootstrapping fashion to refine predictions in the target language for use as ground truth in training the model.Using this approach we demonstrate improved transferability among French, English, and Spanish languages using both historical and modern handwriting datasets. In the best case, transferring with the proposed methodology results in character error rates nearly as good as full supervised training.