 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Document Object Detection: Benchmark Suite and Method
Paper and Code

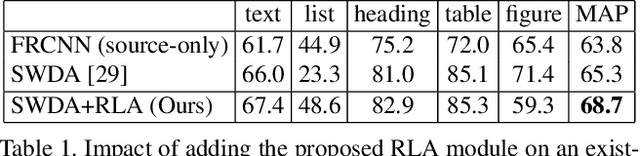
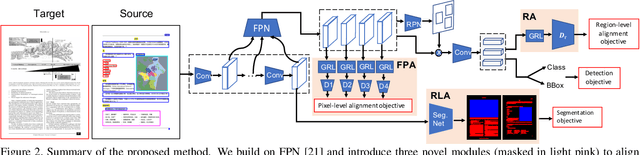
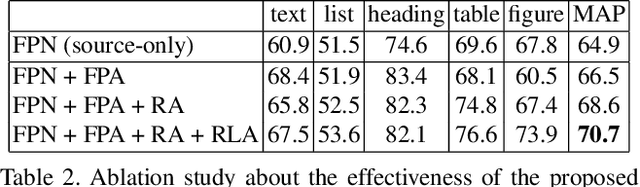
Decomposing images of document pages into high-level semantic regions (e.g., figures, tables, paragraphs), document object detection (DOD) is fundamental for downstream tasks like intelligent document editing and understanding. DOD remains a challenging problem as document objects vary significantly in layout, size, aspect ratio, texture, etc. An additional challenge arises in practice because large labeled training datasets are only available for domains that differ from the target domain. We investigate cross-domain DOD, where the goal is to learn a detector for the target domain using labeled data from the source domain and only unlabeled data from the target domain. Documents from the two domains may vary significantly in layout, language, and genre. We establish a benchmark suite consisting of different types of PDF document datasets that can be utilized for cross-domain DOD model training and evaluation. For each dataset, we provide the page images, bounding box annotations, PDF files, and the rendering layers extracted from the PDF files. Moreover, we propose a novel cross-domain DOD model which builds upon the standard detection model and addresses domain shifts by incorporating three novel alignment modules: Feature Pyramid Alignment (FPA) module, Region Alignment (RA) module and Rendering Layer alignment (RLA) module. Extensive experiments on the benchmark suite substantiate the efficacy of the three proposed modules and the proposed method significantly outperforms the baseline methods. The project page is at \url{https://github.com/kailigo/cddod}.