 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Energy and Precision Requirements for Online Learning
Paper and Code
Aug 26, 2016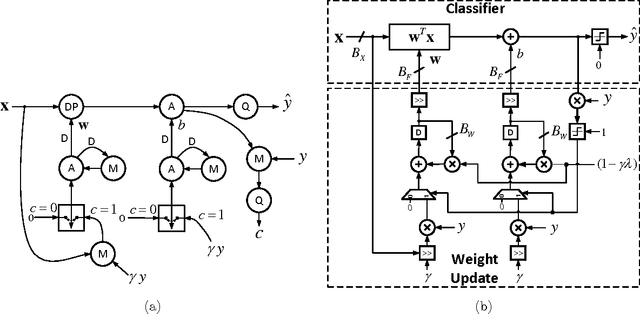
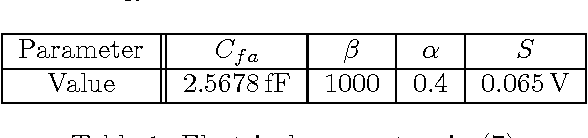
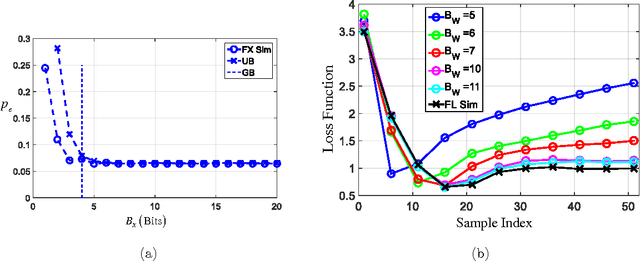
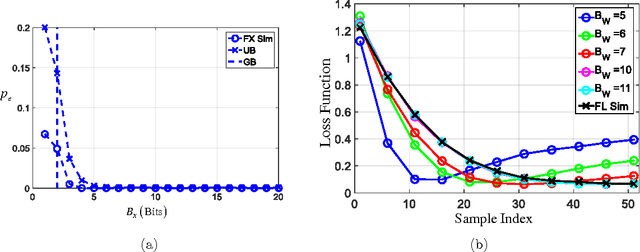
It is well-known that the precision of data, hyperparameters, and internal representations employed in learning systems directly impacts its energy, throughput, and latency. The precision requirements for the training algorithm are also important for systems that learn on-the-fly. Prior work has shown that the data and hyperparameters can be quantized heavily without incurring much penalty in classification accuracy when compared to floating point implementations. These works suffer from two key limitations. First, they assume uniform precision for the classifier and for the training algorithm and thus miss out on the opportunity to further reduce precision. Second, prior works are empirical studies. In this article, we overcome both these limitations by deriving analytical lower bounds on the precision requirements of the commonly employed stochastic gradient descent (SGD) on-line learning algorithm in the specific context of a support vector machine (SVM). Lower bounds on the data precision are derived in terms of the the desired classification accuracy and precision of the hyperparameters used in the classifier. Additionally, lower bounds on the hyperparameter precision in the SGD training algorithm are obtained. These bounds are validated using both synthetic and the UCI breast cancer dataset. Additionally, the impact of these precisions on the energy consumption of a fixed-point SVM with on-line training is studied.