 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiSup: Bidirectional Quantization Error Suppression for Large Language Models
May 24, 2024As the size and context length of Large Language Models (LLMs) grow, weight-activation quantization has emerged as a crucial technique for efficient deployment of LLMs. Compared to weight-only quantization, weight-activation quantization presents greater challenges due to the presence of outliers in activations. Existing methods have made significant progress by exploring mixed-precision quantization and outlier suppression. However, these methods primarily focus on optimizing the results of single matrix multiplication, neglecting the bidirectional propagation of quantization errors in LLMs. Specifically, errors accumulate vertically within the same token through layers, and diffuse horizontally across different tokens due to self-attention mechanisms. To address this issue, we introduce BiSup, a Bidirectional quantization error Suppression method. By constructing appropriate optimizable parameter spaces, BiSup utilizes a small amount of data for quantization-aware parameter-efficient fine-tuning to suppress the error vertical accumulation. Besides, BiSup employs prompt mixed-precision quantization strategy, which preserves high precision for the key-value cache of system prompts, to mitigate the error horizontal diffusion. Extensive experiments on Llama and Qwen families demonstrate that BiSup can improve performance over two state-of-the-art methods (the average WikiText2 perplexity decreases from 13.26 to 9.41 for Atom and from 14.33 to 7.85 for QuaRot under the W3A3-g128 configuration), further facilitating the practical applications of low-bit weight-activation quantization.
Causality Extraction from Nuclear Licensee Event Reports Using a Hybrid Framework
Apr 08, 2024Industry-wide nuclear power plant operating experience is a critical source of raw data for performing parameter estimations in reliability and risk models. Much operating experience information pertains to failure events and is stored as reports containing unstructured data, such as narratives. Event reports are essential for understanding how failures are initiated and propagated, including the numerous causal relations involved. Causal relation extraction using deep learning represents a significant frontier in the field of natural language processing (NLP), and is crucial since it enables the interpretation of intricate narratives and connections contained within vast amounts of written information. This paper proposed a hybrid framework for causality detection and extraction from nuclear licensee event reports. The main contributions include: (1) we compiled an LER corpus with 20,129 text samples for causality analysis, (2) developed an interactive tool for labeling cause effect pairs, (3) built a deep-learning-based approach for causal relation detection, and (4) developed a knowledge based cause-effect extraction approach.
An Asynchronous Updating Reinforcement Learning Framework for Task-oriented Dialog System
May 04, 2023


Reinforcement learning has been applied to train the dialog systems in many works. Previous approaches divide the dialog system into multiple modules including DST (dialog state tracking) and DP (dialog policy), and train these modules simultaneously. However, different modules influence each other during training. The errors from DST might misguide the dialog policy, and the system action brings extra difficulties for the DST module. To alleviate this problem, we propose Asynchronous Updating Reinforcement Learning framework (AURL) that updates the DST module and the DP module asynchronously under a cooperative setting. Furthermore, curriculum learning is implemented to address the problem of unbalanced data distribution during reinforcement learning sampling, and multiple user models are introduced to increase the dialog diversity. Results on the public SSD-PHONE dataset show that our method achieves a compelling result with a 31.37% improvement on the dialog success rate. The code is publicly available via https://github.com/shunjiu/AURL.
Reward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022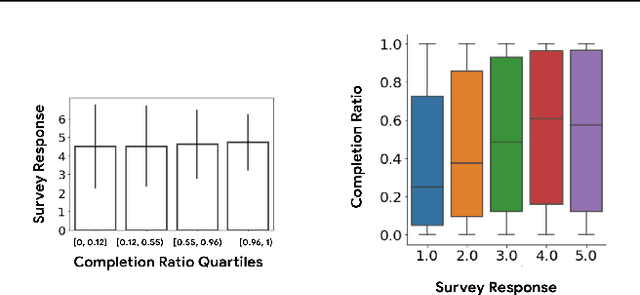
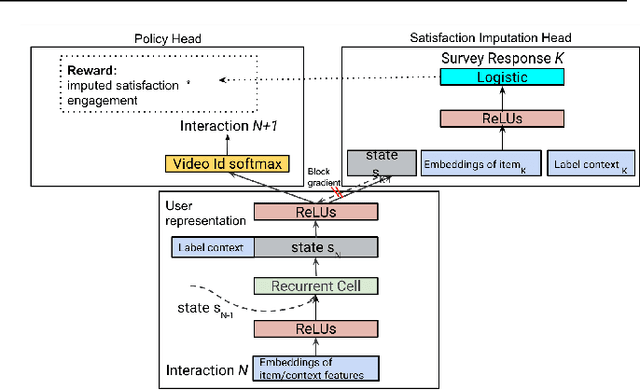
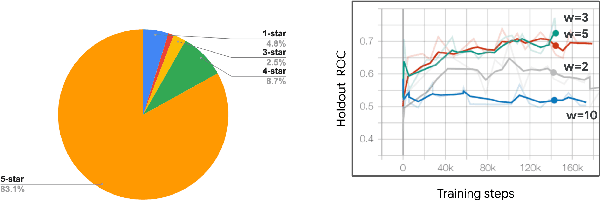
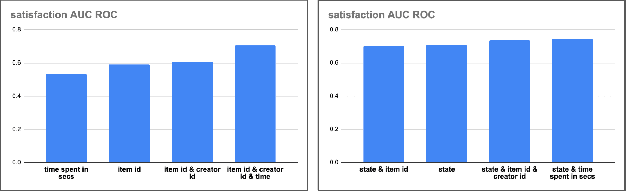
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
A Slot Is Not Built in One Utterance: Spoken Language Dialogs with Sub-Slots
Mar 21, 2022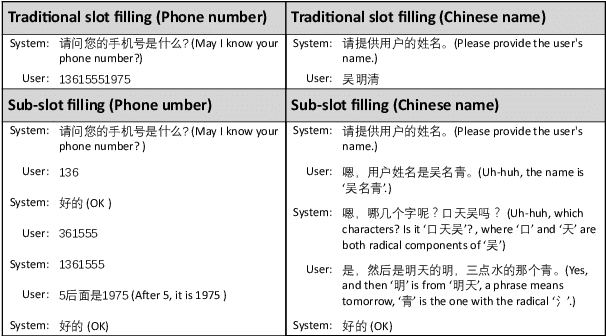

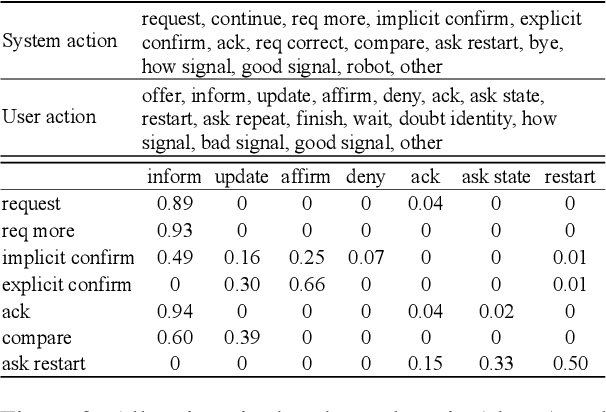
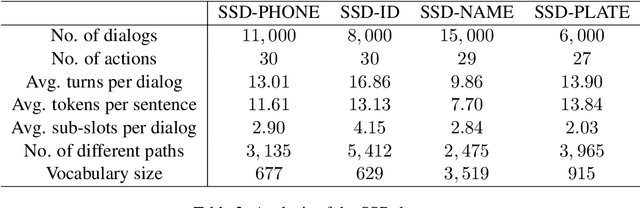
A slot value might be provided segment by segment over multiple-turn interactions in a dialog, especially for some important information such as phone numbers and names. It is a common phenomenon in daily life, but little attention has been paid to it in previous work. To fill the gap, this paper defines a new task named Sub-Slot based Task-Oriented Dialog (SSTOD) and builds a Chinese dialog dataset SSD for boosting research on SSTOD. The dataset includes a total of 40K dialogs and 500K utterances from four different domains: Chinese names, phone numbers, ID numbers and license plate numbers. The data is well annotated with sub-slot values, slot values, dialog states and actions. We find some new linguistic phenomena and interactive manners in SSTOD which raise critical challenges of building dialog agents for the task. We test three state-of-the-art dialog models on SSTOD and find they cannot handle the task well on any of the four domains. We also investigate an improved model by involving slot knowledge in a plug-in manner. More work should be done to meet the new challenges raised from SSTOD which widely exists in real-life applications. The dataset and code are publicly available via https://github.com/shunjiu/SSTOD.
Understanding the Energy and Precision Requirements for Online Learning
Aug 26, 2016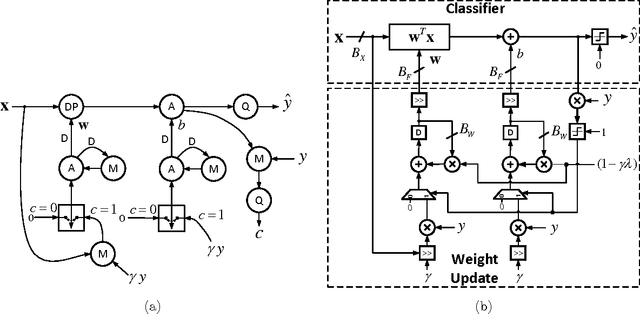
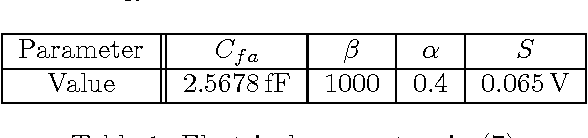
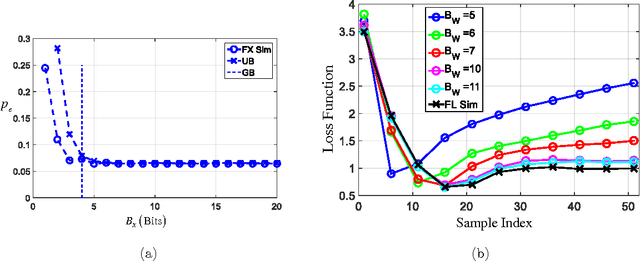
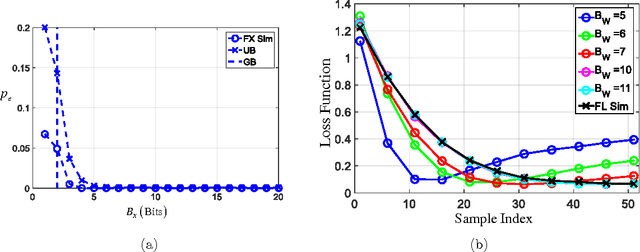
It is well-known that the precision of data, hyperparameters, and internal representations employed in learning systems directly impacts its energy, throughput, and latency. The precision requirements for the training algorithm are also important for systems that learn on-the-fly. Prior work has shown that the data and hyperparameters can be quantized heavily without incurring much penalty in classification accuracy when compared to floating point implementations. These works suffer from two key limitations. First, they assume uniform precision for the classifier and for the training algorithm and thus miss out on the opportunity to further reduce precision. Second, prior works are empirical studies. In this article, we overcome both these limitations by deriving analytical lower bounds on the precision requirements of the commonly employed stochastic gradient descent (SGD) on-line learning algorithm in the specific context of a support vector machine (SVM). Lower bounds on the data precision are derived in terms of the the desired classification accuracy and precision of the hyperparameters used in the classifier. Additionally, lower bounds on the hyperparameter precision in the SGD training algorithm are obtained. These bounds are validated using both synthetic and the UCI breast cancer dataset. Additionally, the impact of these precisions on the energy consumption of a fixed-point SVM with on-line training is studied.
Error-Resilient Machine Learning in Near Threshold Voltage via Classifier Ensemble
Jul 03, 2016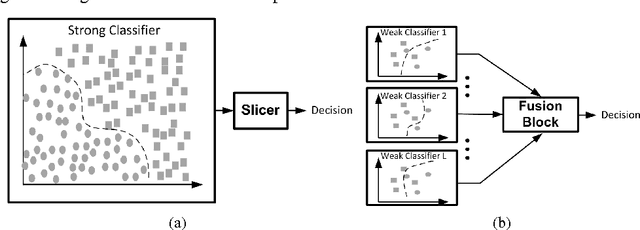
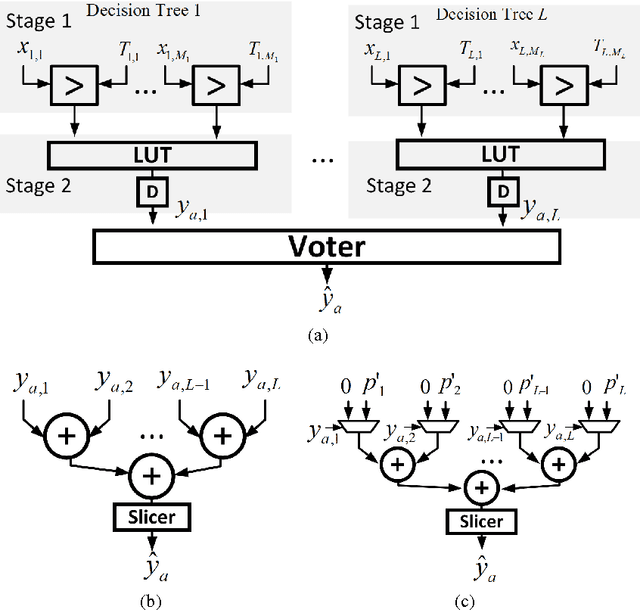
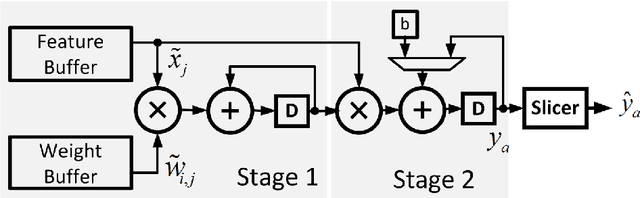
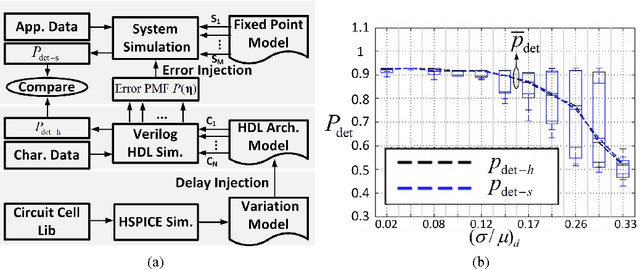
In this paper, we present the design of error-resilient machine learning architectures by employing a distributed machine learning framework referred to as classifier ensemble (CE). CE combines several simple classifiers to obtain a strong one. In contrast, centralized machine learning employs a single complex block. We compare the random forest (RF) and the support vector machine (SVM), which are representative techniques from the CE and centralized frameworks, respectively. Employing the dataset from UCI machine learning repository and architectural-level error models in a commercial 45 nm CMOS process, it is demonstrated that RF-based architectures are significantly more robust than SVM architectures in presence of timing errors due to process variations in near-threshold voltage (NTV) regions (0.3 V - 0.7 V). In particular, the RF architecture exhibits a detection accuracy (P_{det}) that varies by 3.2% while maintaining a median P_{det} > 0.9 at a gate level delay variation of 28.9% . In comparison, SVM exhibits a P_{det} that varies by 16.8%. Additionally, we propose an error weighted voting technique that incorporates the timing error statistics of the NTV circuit fabric to further enhance robustness. Simulation results confirm that the error weighted voting achieves a P_{det} that varies by only 1.4%, which is 12X lower compared to SVM.
Elastic regularization in restricted Boltzmann machines: Dealing with $p\gg N$
Oct 21, 2015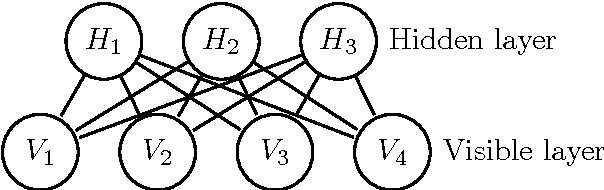
Restricted Boltzmann machines (RBMs) are endowed with the universal power of modeling (binary) joint distributions. Meanwhile, as a result of their confining network structure, training RBMs confronts less difficulties (compared with more complicated models, e.g., Boltzmann machines) when dealing with approximation and inference issues. However, in certain computational biology scenarios, such as the cancer data analysis, employing RBMs to model data features may lose its efficacy due to the "$p\gg N$" problem, in which the number of features/predictors is much larger than the sample size. The "$p\gg N$" problem puts the bias-variance trade-off in a more crucial place when designing statistical learning methods. In this manuscript, we try to address this problem by proposing a novel RBM model, called elastic restricted Boltzmann machine (eRBM), which incorporates the elastic regularization term into the likelihood/cost function. We provide several theoretical analysis on the superiority of our model. Furthermore, attributed to the classic contrastive divergence (CD) algorithm, eRBMs can be trained efficiently. Our novel model is a promising method for future cancer data analysis.
Partitioning Large Scale Deep Belief Networks Using Dropout
Aug 28, 2015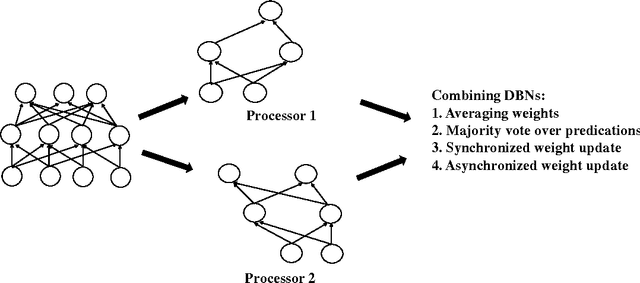
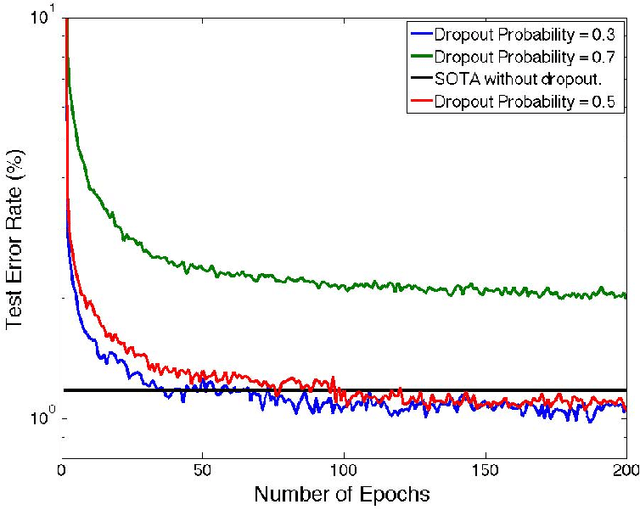
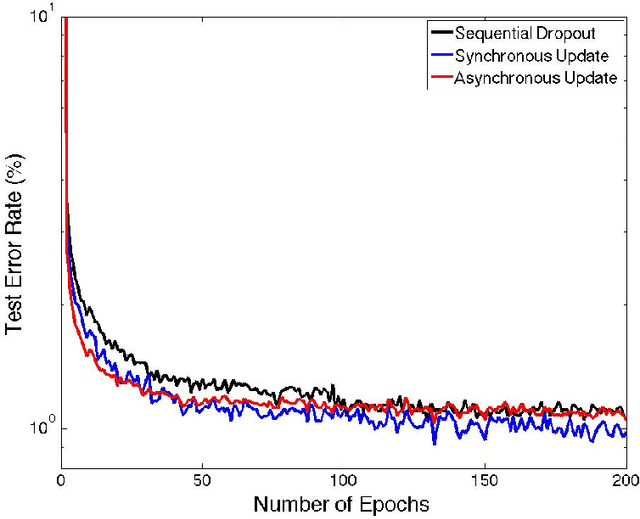
Deep learning methods have shown great promise in many practical applications, ranging from speech recognition, visual object recognition, to text processing. However, most of the current deep learning methods suffer from scalability problems for large-scale applications, forcing researchers or users to focus on small-scale problems with fewer parameters. In this paper, we consider a well-known machine learning model, deep belief networks (DBNs) that have yielded impressive classification performance on a large number of benchmark machine learning tasks. To scale up DBN, we propose an approach that can use the computing clusters in a distributed environment to train large models, while the dense matrix computations within a single machine are sped up using graphics processors (GPU). When training a DBN, each machine randomly drops out a portion of neurons in each hidden layer, for each training case, making the remaining neurons only learn to detect features that are generally helpful for producing the correct answer. Within our approach, we have developed four methods to combine outcomes from each machine to form a unified model. Our preliminary experiment on the mnst handwritten digit database demonstrates that our approach outperforms the state of the art test error rate.