 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Planning for Personal Plans
Feb 26, 2025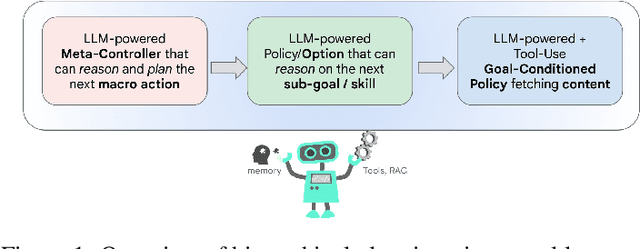
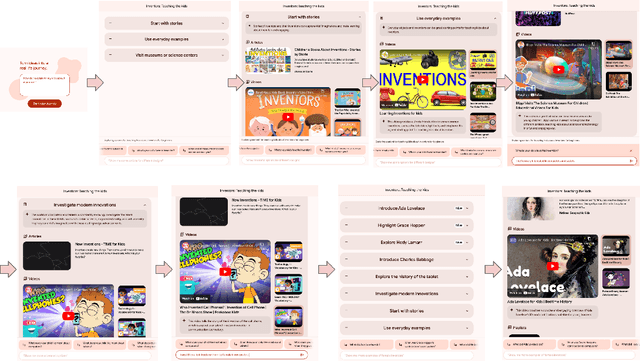
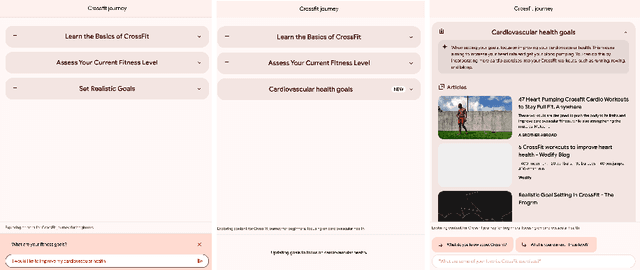
The language generation and reasoning capabilities of large language models (LLMs) have enabled conversational systems with impressive performance in a variety of tasks, from code generation, to composing essays, to passing STEM and legal exams, to a new paradigm for knowledge search. Besides those short-term use applications, LLMs are increasingly used to help with real-life goals or tasks that take a long time to complete, involving multiple sessions across days, weeks, months, or even years. Thus to enable conversational systems for long term interactions and tasks, we need language-based agents that can plan for long horizons. Traditionally, such capabilities were addressed by reinforcement learning agents with hierarchical planning capabilities. In this work, we explore a novel architecture where the LLM acts as the meta-controller deciding the agent's next macro-action, and tool use augmented LLM-based option policies execute the selected macro-action. We instantiate this framework for a specific set of macro-actions enabling adaptive planning for users' personal plans through conversation and follow-up questions collecting user feedback. We show how this paradigm can be applicable in scenarios ranging from tutoring for academic and non-academic tasks to conversational coaching for personal health plans.
Agents Thinking Fast and Slow: A Talker-Reasoner Architecture
Oct 10, 2024Large language models have enabled agents of all kinds to interact with users through natural conversation. Consequently, agents now have two jobs: conversing and planning/reasoning. Their conversational responses must be informed by all available information, and their actions must help to achieve goals. This dichotomy between conversing with the user and doing multi-step reasoning and planning can be seen as analogous to the human systems of "thinking fast and slow" as introduced by Kahneman. Our approach is comprised of a "Talker" agent (System 1) that is fast and intuitive, and tasked with synthesizing the conversational response; and a "Reasoner" agent (System 2) that is slower, more deliberative, and more logical, and is tasked with multi-step reasoning and planning, calling tools, performing actions in the world, and thereby producing the new agent state. We describe the new Talker-Reasoner architecture and discuss its advantages, including modularity and decreased latency. We ground the discussion in the context of a sleep coaching agent, in order to demonstrate real-world relevance.
Large Language Models for User Interest Journeys
May 24, 2023



Large language models (LLMs) have shown impressive capabilities in natural language understanding and generation. Their potential for deeper user understanding and improved personalized user experience on recommendation platforms is, however, largely untapped. This paper aims to address this gap. Recommender systems today capture users' interests through encoding their historical activities on the platforms. The generated user representations are hard to examine or interpret. On the other hand, if we were to ask people about interests they pursue in their life, they might talk about their hobbies, like I just started learning the ukulele, or their relaxation routines, e.g., I like to watch Saturday Night Live, or I want to plant a vertical garden. We argue, and demonstrate through extensive experiments, that LLMs as foundation models can reason through user activities, and describe their interests in nuanced and interesting ways, similar to how a human would. We define interest journeys as the persistent and overarching user interests, in other words, the non-transient ones. These are the interests that we believe will benefit most from the nuanced and personalized descriptions. We introduce a framework in which we first perform personalized extraction of interest journeys, and then summarize the extracted journeys via LLMs, using techniques like few-shot prompting, prompt-tuning and fine-tuning. Together, our results in prompting LLMs to name extracted user journeys in a large-scale industrial platform demonstrate great potential of these models in providing deeper, more interpretable, and controllable user understanding. We believe LLM powered user understanding can be a stepping stone to entirely new user experiences on recommendation platforms that are journey-aware, assistive, and enabling frictionless conversation down the line.
Reward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022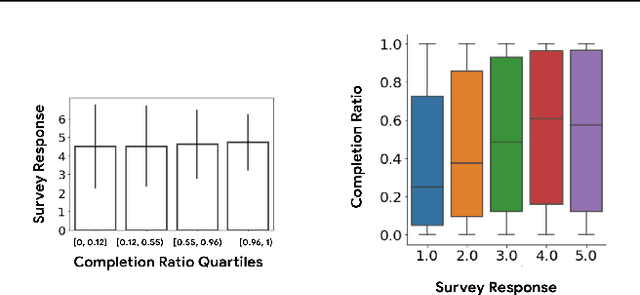
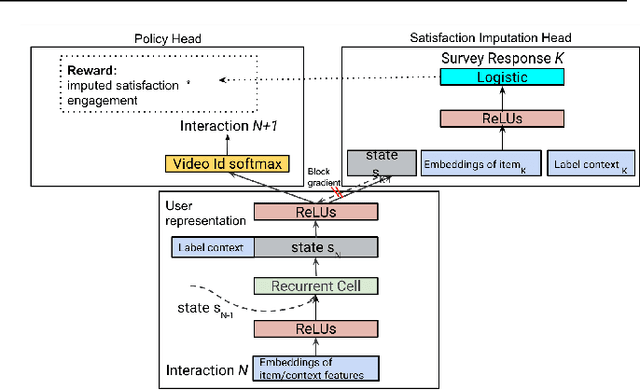
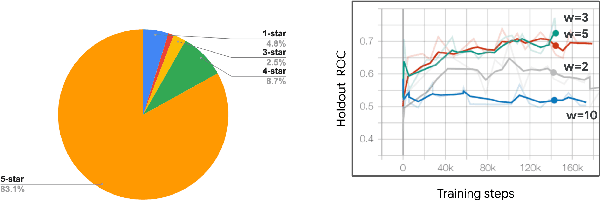
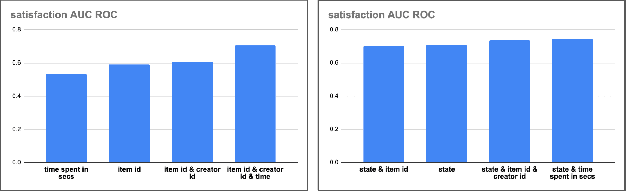
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
Rethinking Reinforcement Learning for Recommendation: A Prompt Perspective
Jun 15, 2022
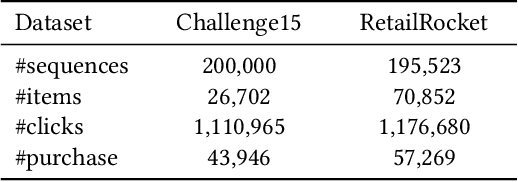

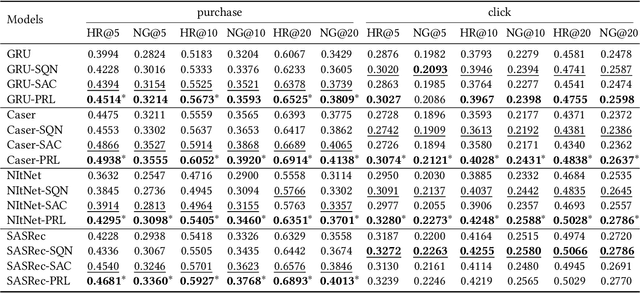
Modern recommender systems aim to improve user experience. As reinforcement learning (RL) naturally fits this objective -- maximizing an user's reward per session -- it has become an emerging topic in recommender systems. Developing RL-based recommendation methods, however, is not trivial due to the \emph{offline training challenge}. Specifically, the keystone of traditional RL is to train an agent with large amounts of online exploration making lots of `errors' in the process. In the recommendation setting, though, we cannot afford the price of making `errors' online. As a result, the agent needs to be trained through offline historical implicit feedback, collected under different recommendation policies; traditional RL algorithms may lead to sub-optimal policies under these offline training settings. Here we propose a new learning paradigm -- namely Prompt-Based Reinforcement Learning (PRL) -- for the offline training of RL-based recommendation agents. While traditional RL algorithms attempt to map state-action input pairs to their expected rewards (e.g., Q-values), PRL directly infers actions (i.e., recommended items) from state-reward inputs. In short, the agents are trained to predict a recommended item given the prior interactions and an observed reward value -- with simple supervised learning. At deployment time, this historical (training) data acts as a knowledge base, while the state-reward pairs are used as a prompt. The agents are thus used to answer the question: \emph{ Which item should be recommended given the prior interactions \& the prompted reward value}? We implement PRL with four notable recommendation models and conduct experiments on two real-world e-commerce datasets. Experimental results demonstrate the superior performance of our proposed methods.
Towards Content Provider Aware Recommender Systems: A Simulation Study on the Interplay between User and Provider Utilities
May 06, 2021
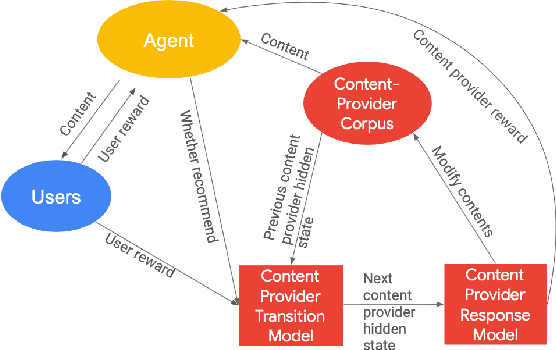
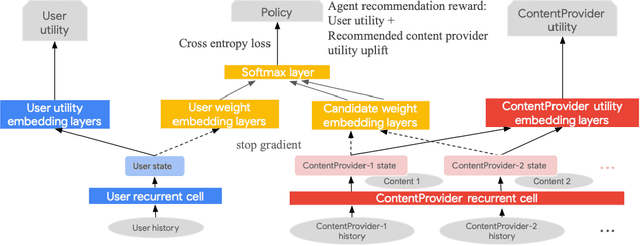
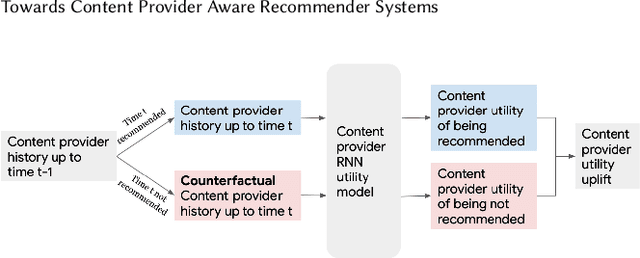
Most existing recommender systems focus primarily on matching users to content which maximizes user satisfaction on the platform. It is increasingly obvious, however, that content providers have a critical influence on user satisfaction through content creation, largely determining the content pool available for recommendation. A natural question thus arises: can we design recommenders taking into account the long-term utility of both users and content providers? By doing so, we hope to sustain more providers and a more diverse content pool for long-term user satisfaction. Understanding the full impact of recommendations on both user and provider groups is challenging. This paper aims to serve as a research investigation of one approach toward building a provider-aware recommender, and evaluating its impact in a simulated setup. To characterize the user-recommender-provider interdependence, we complement user modeling by formalizing provider dynamics as well. The resulting joint dynamical system gives rise to a weakly-coupled partially observable Markov decision process driven by recommender actions and user feedback to providers. We then build a REINFORCE recommender agent, coined EcoAgent, to optimize a joint objective of user utility and the counterfactual utility lift of the provider associated with the recommended content, which we show to be equivalent to maximizing overall user utility and the utilities of all providers on the platform under some mild assumptions. To evaluate our approach, we introduce a simulation environment capturing the key interactions among users, providers, and the recommender. We offer a number of simulated experiments that shed light on both the benefits and the limitations of our approach. These results help understand how and when a provider-aware recommender agent is of benefit in building multi-stakeholder recommender systems.
Adversarial Recommendation: Attack of the Learned Fake Users
Sep 21, 2018

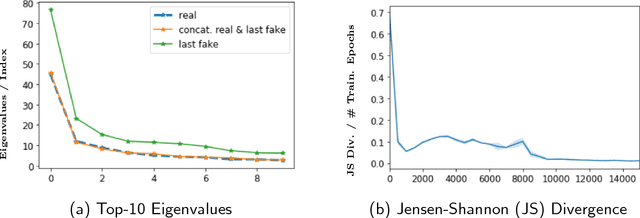
Can machine learning models for recommendation be easily fooled? While the question has been answered for hand-engineered fake user profiles, it has not been explored for machine learned adversarial attacks. This paper attempts to close this gap. We propose a framework for generating fake user profiles which, when incorporated in the training of a recommendation system, can achieve an adversarial intent, while remaining indistinguishable from real user profiles. We formulate this procedure as a repeated general-sum game between two players: an oblivious recommendation system $R$ and an adversarial fake user generator $A$ with two goals: (G1) the rating distribution of the fake users needs to be close to the real users, and (G2) some objective $f_A$ encoding the attack intent, such as targeting the top-K recommendation quality of $R$ for a subset of users, needs to be optimized. We propose a learning framework to achieve both goals, and offer extensive experiments considering multiple types of attacks highlighting the vulnerability of recommendation systems.
Glass-Box Program Synthesis: A Machine Learning Approach
Sep 25, 2017

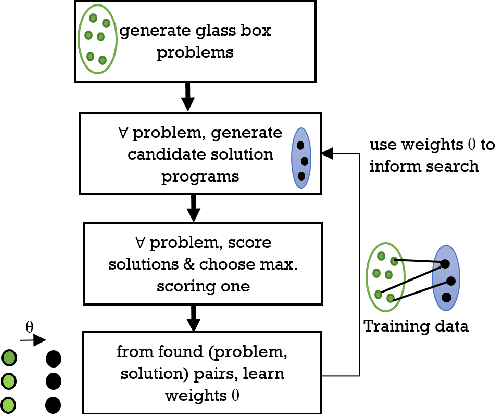
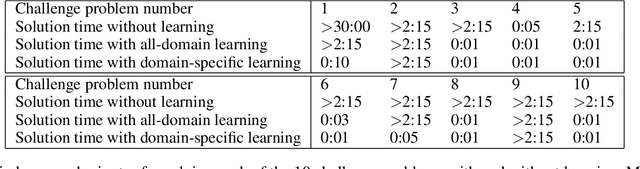
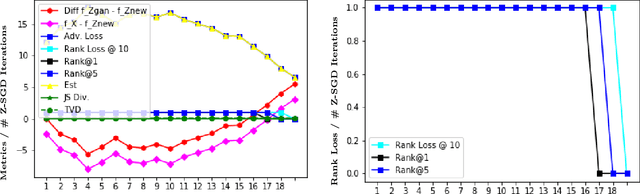
Recently proposed models which learn to write computer programs from data use either input/output examples or rich execution traces. Instead, we argue that a novel alternative is to use a glass-box loss function, given as a program itself that can be directly inspected. Glass-box optimization covers a wide range of problems, from computing the greatest common divisor of two integers, to learning-to-learn problems. In this paper, we present an intelligent search system which learns, given the partial program and the glass-box problem, the probabilities over the space of programs. We empirically demonstrate that our informed search procedure leads to significant improvements compared to brute-force program search, both in terms of accuracy and time. For our experiments we use rich context free grammars inspired by number theory, text processing, and algebra. Our results show that (i) performing 4 rounds of our framework typically solves about 70% of the target problems, (ii) our framework can improve itself even in domain agnostic scenarios, and (iii) it can solve problems that would be otherwise too slow to solve with brute-force search.
Recommendation under Capacity Constraints
Mar 12, 2017
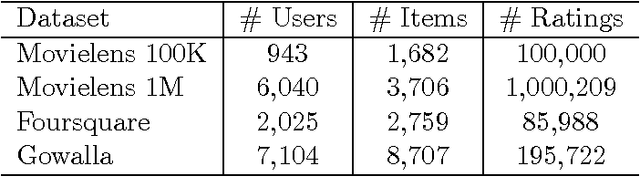
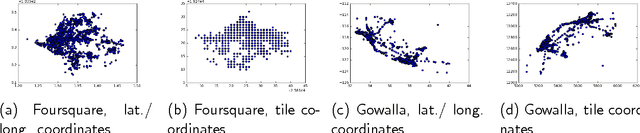
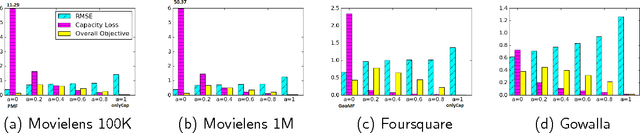
In this paper, we investigate the common scenario where every candidate item for recommendation is characterized by a maximum capacity, i.e., number of seats in a Point-of-Interest (POI) or size of an item's inventory. Despite the prevalence of the task of recommending items under capacity constraints in a variety of settings, to the best of our knowledge, none of the known recommender methods is designed to respect capacity constraints. To close this gap, we extend three state-of-the art latent factor recommendation approaches: probabilistic matrix factorization (PMF), geographical matrix factorization (GeoMF), and bayesian personalized ranking (BPR), to optimize for both recommendation accuracy and expected item usage that respects the capacity constraints. We introduce the useful concepts of user propensity to listen and item capacity. Our experimental results in real-world datasets, both for the domain of item recommendation and POI recommendation, highlight the benefit of our method for the setting of recommendation under capacity constraints.