 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reinforcement Learning for Recommendation: A Prompt Perspective
Paper and Code
Jun 15, 2022
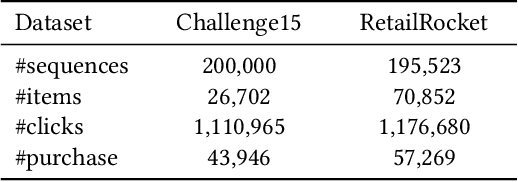

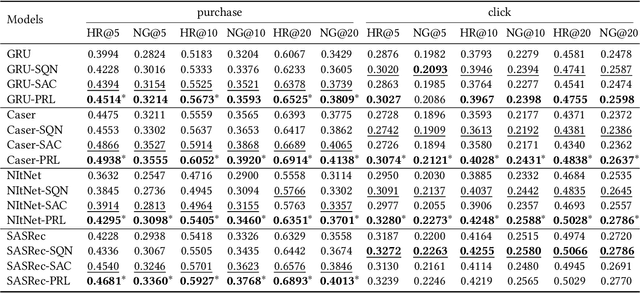
Modern recommender systems aim to improve user experience. As reinforcement learning (RL) naturally fits this objective -- maximizing an user's reward per session -- it has become an emerging topic in recommender systems. Developing RL-based recommendation methods, however, is not trivial due to the \emph{offline training challenge}. Specifically, the keystone of traditional RL is to train an agent with large amounts of online exploration making lots of `errors' in the process. In the recommendation setting, though, we cannot afford the price of making `errors' online. As a result, the agent needs to be trained through offline historical implicit feedback, collected under different recommendation policies; traditional RL algorithms may lead to sub-optimal policies under these offline training settings. Here we propose a new learning paradigm -- namely Prompt-Based Reinforcement Learning (PRL) -- for the offline training of RL-based recommendation agents. While traditional RL algorithms attempt to map state-action input pairs to their expected rewards (e.g., Q-values), PRL directly infers actions (i.e., recommended items) from state-reward inputs. In short, the agents are trained to predict a recommended item given the prior interactions and an observed reward value -- with simple supervised learning. At deployment time, this historical (training) data acts as a knowledge base, while the state-reward pairs are used as a prompt. The agents are thus used to answer the question: \emph{ Which item should be recommended given the prior interactions \& the prompted reward value}? We implement PRL with four notable recommendation models and conduct experiments on two real-world e-commerce datasets. Experimental results demonstrate the superior performance of our proposed methods.