 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents Thinking Fast and Slow: A Talker-Reasoner Architecture
Oct 10, 2024Large language models have enabled agents of all kinds to interact with users through natural conversation. Consequently, agents now have two jobs: conversing and planning/reasoning. Their conversational responses must be informed by all available information, and their actions must help to achieve goals. This dichotomy between conversing with the user and doing multi-step reasoning and planning can be seen as analogous to the human systems of "thinking fast and slow" as introduced by Kahneman. Our approach is comprised of a "Talker" agent (System 1) that is fast and intuitive, and tasked with synthesizing the conversational response; and a "Reasoner" agent (System 2) that is slower, more deliberative, and more logical, and is tasked with multi-step reasoning and planning, calling tools, performing actions in the world, and thereby producing the new agent state. We describe the new Talker-Reasoner architecture and discuss its advantages, including modularity and decreased latency. We ground the discussion in the context of a sleep coaching agent, in order to demonstrate real-world relevance.
Proving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021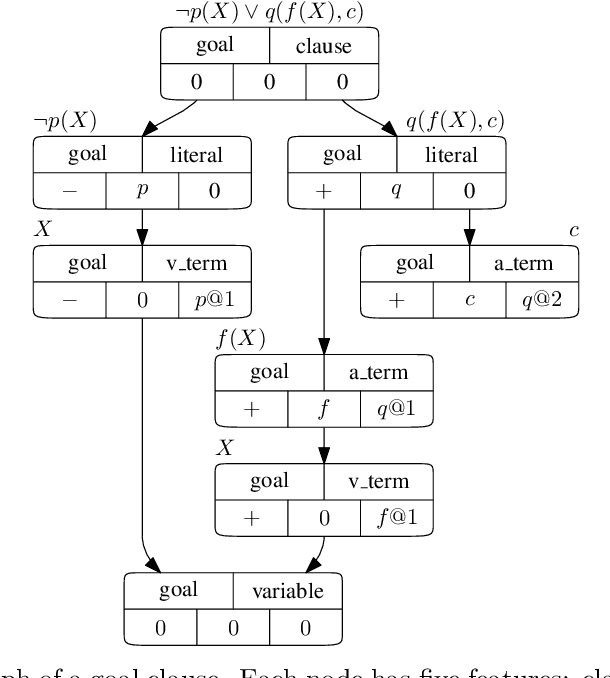
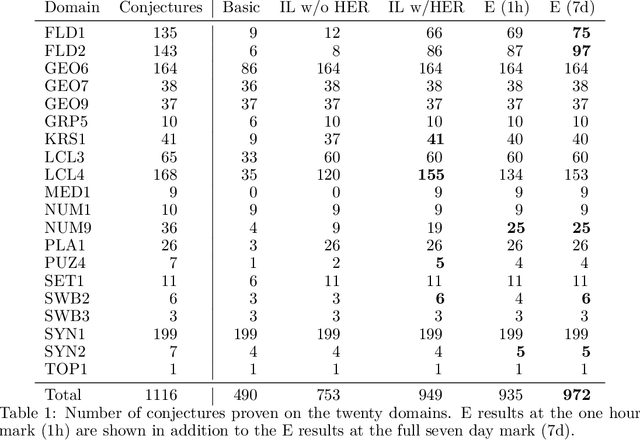
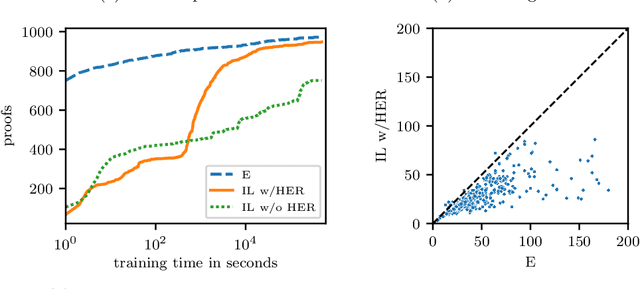
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021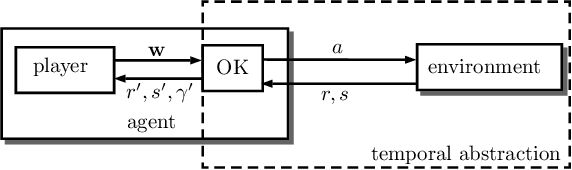
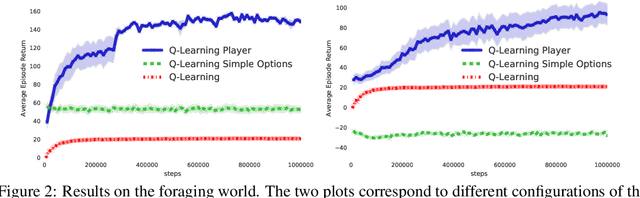
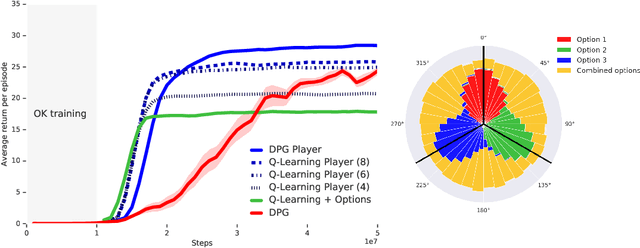
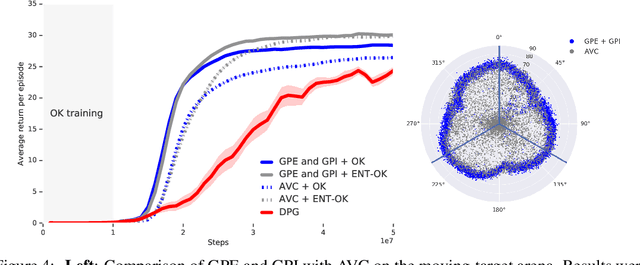
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
AndroidEnv: A Reinforcement Learning Platform for Android
May 27, 2021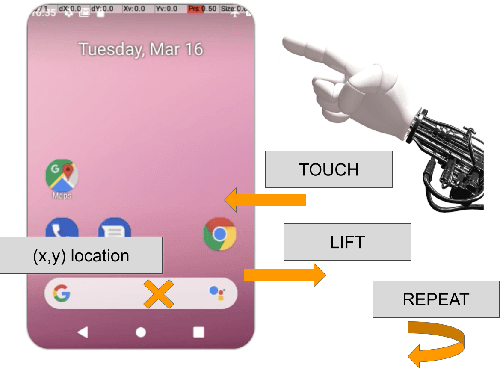
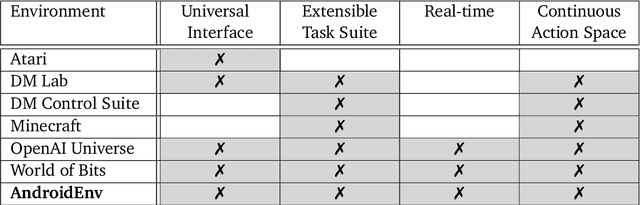
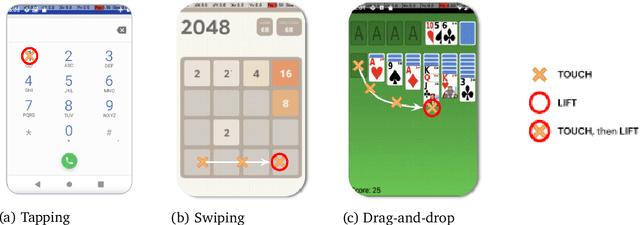
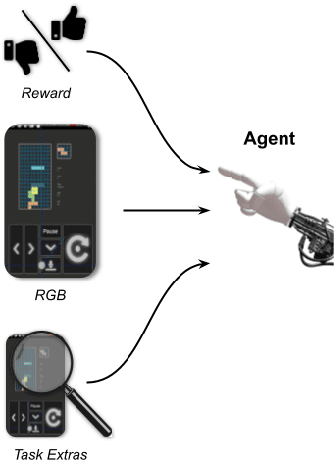
We introduce AndroidEnv, an open-source platform for Reinforcement Learning (RL) research built on top of the Android ecosystem. AndroidEnv allows RL agents to interact with a wide variety of apps and services commonly used by humans through a universal touchscreen interface. Since agents train on a realistic simulation of an Android device, they have the potential to be deployed on real devices. In this report, we give an overview of the environment, highlighting the significant features it provides for research, and we present an empirical evaluation of some popular reinforcement learning agents on a set of tasks built on this platform.
Training a First-Order Theorem Prover from Synthetic Data
Mar 05, 2021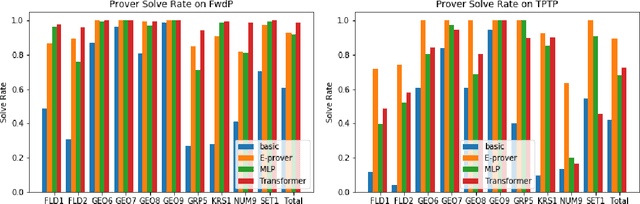
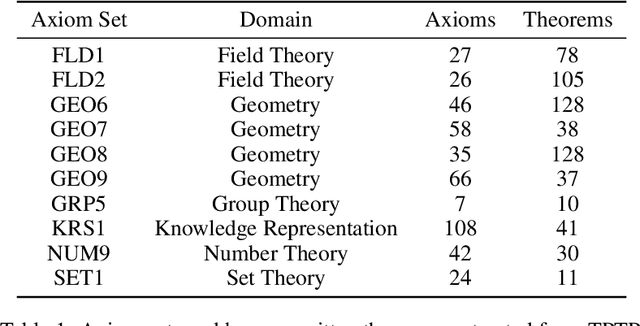
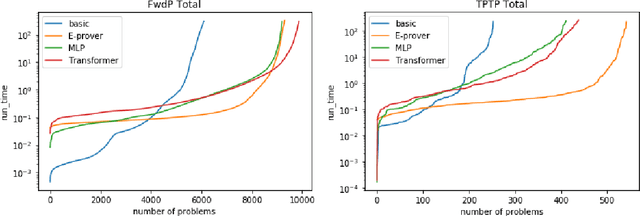
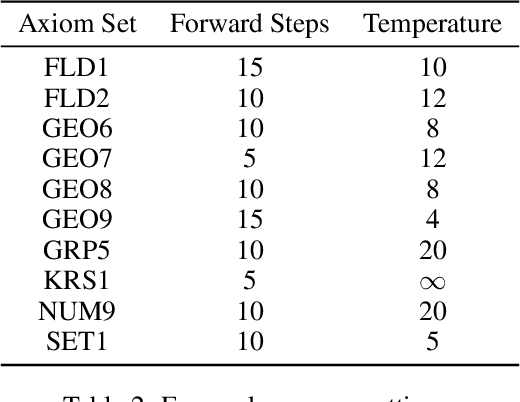
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training purely with synthetically generated theorems, without any human data aside from axioms. We use these theorems to train a neurally-guided saturation-based prover. Our neural prover outperforms the state-of-the-art E-prover on this synthetic data in both time and search steps, and shows significant transfer to the unseen human-written theorems from the TPTP library, where it solves 72\% of first-order problems without equality.
Learning to Prove from Synthetic Theorems
Jun 19, 2020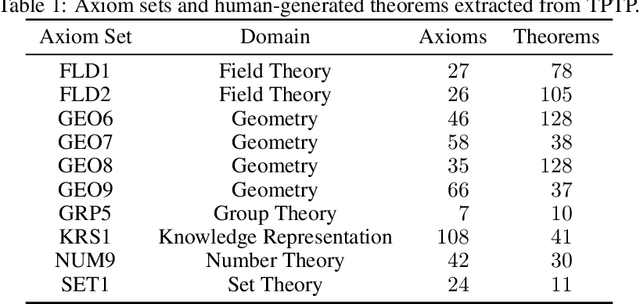
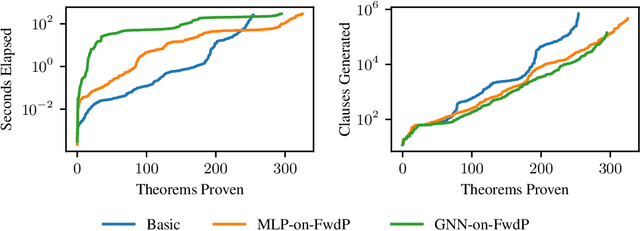
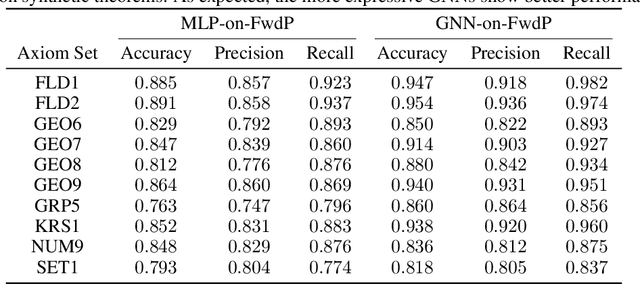
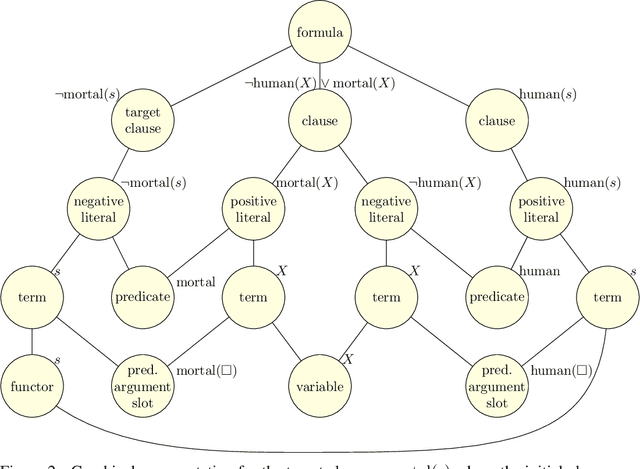
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.
Shaping representations through communication: community size effect in artificial learning systems
Dec 12, 2019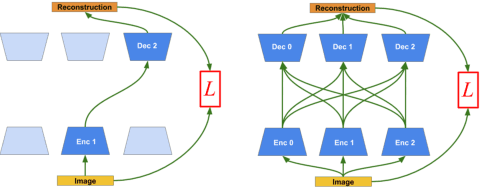
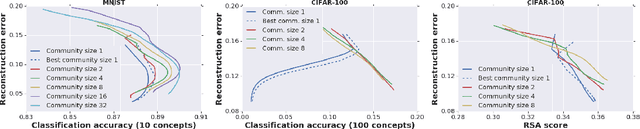

Motivated by theories of language and communication that explain why communities with large numbers of speakers have, on average, simpler languages with more regularity, we cast the representation learning problem in terms of learning to communicate. Our starting point sees the traditional autoencoder setup as a single encoder with a fixed decoder partner that must learn to communicate. Generalizing from there, we introduce community-based autoencoders in which multiple encoders and decoders collectively learn representations by being randomly paired up on successive training iterations. We find that increasing community sizes reduce idiosyncrasies in the learned codes, resulting in representations that better encode concept categories and correlate with human feature norms.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019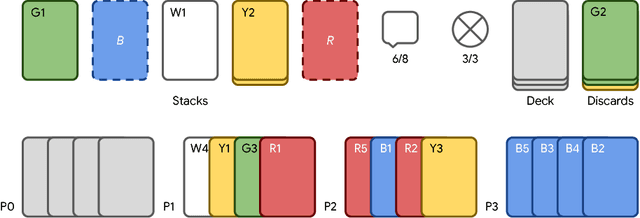
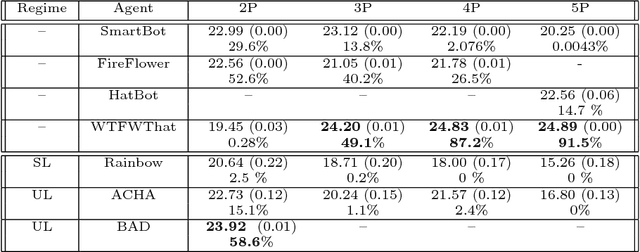
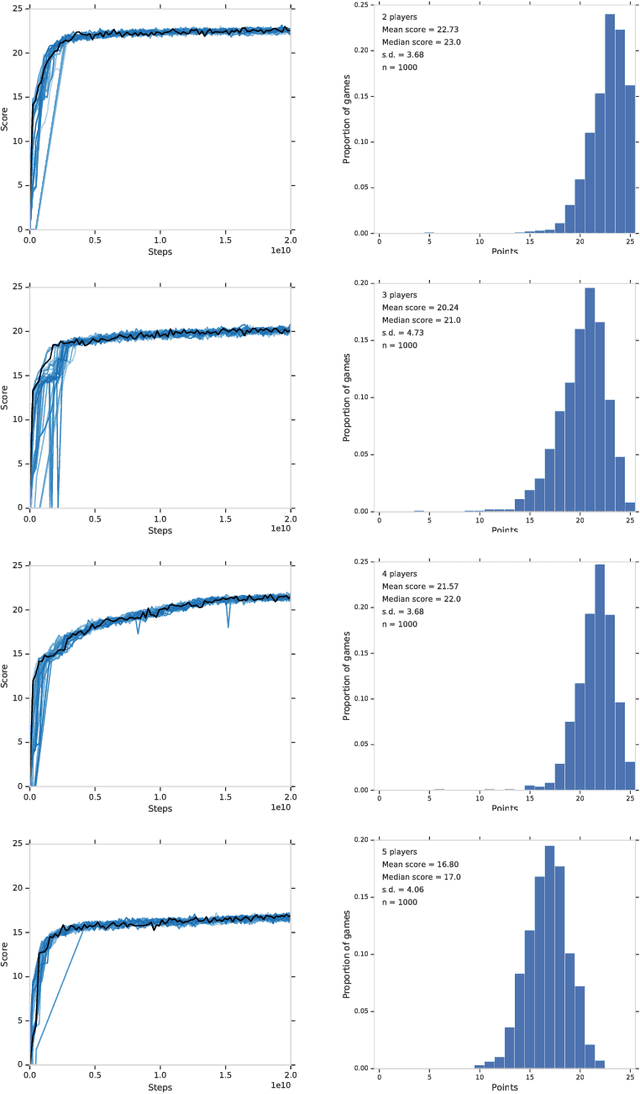
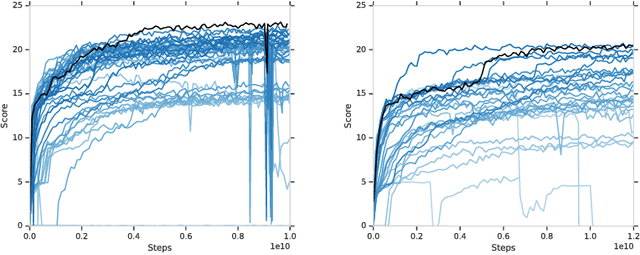
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
The Barbados 2018 List of Open Issues in Continual Learning
Nov 16, 2018We want to make progress toward artificial general intelligence, namely general-purpose agents that autonomously learn how to competently act in complex environments. The purpose of this report is to sketch a research outline, share some of the most important open issues we are facing, and stimulate further discussion in the community. The content is based on some of our discussions during a week-long workshop held in Barbados in February 2018.