 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021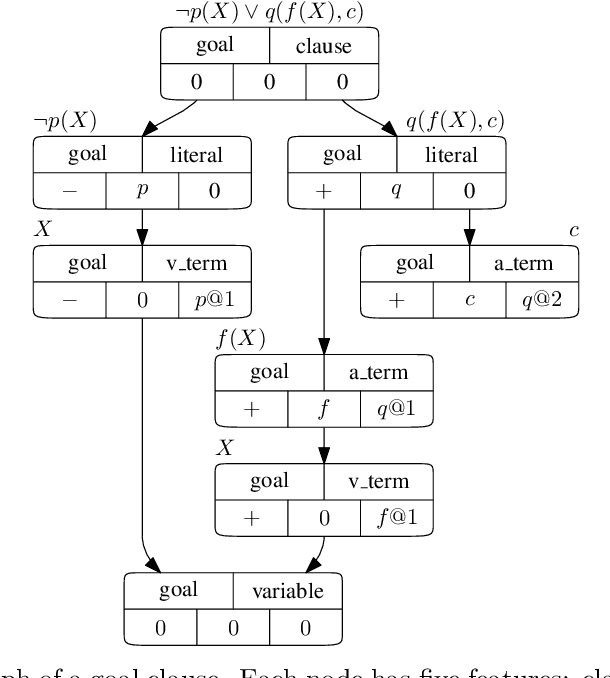
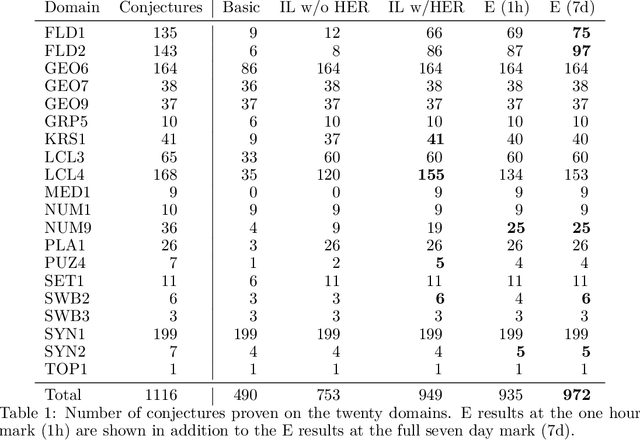
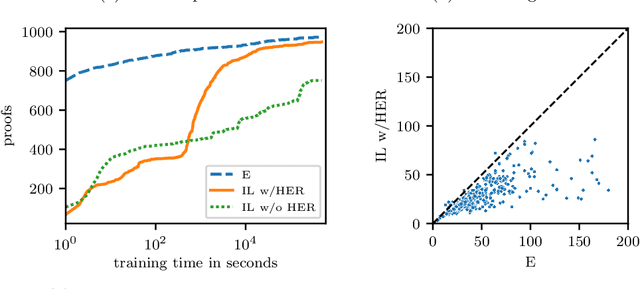
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021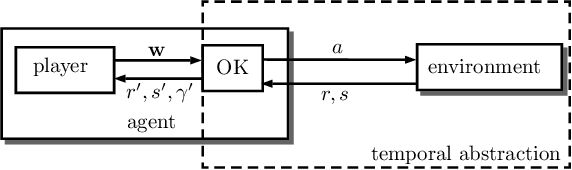
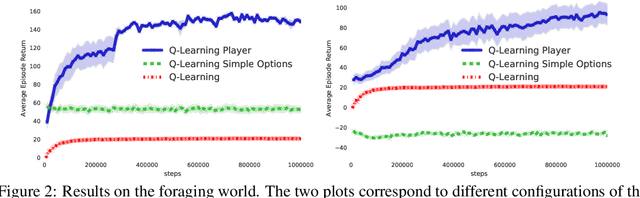
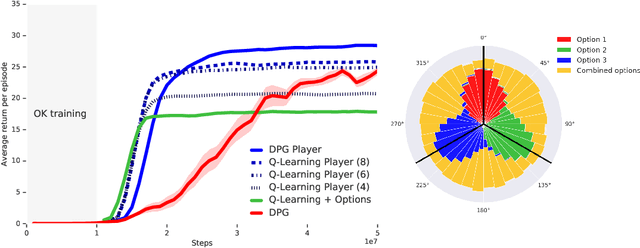
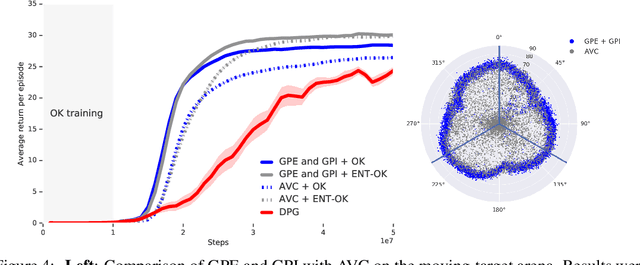
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
Learning to Prove from Synthetic Theorems
Jun 19, 2020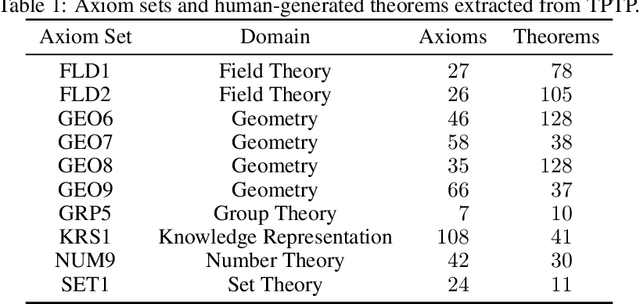
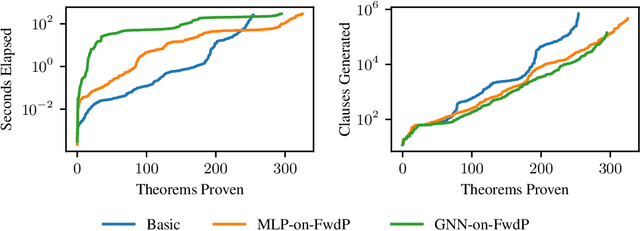
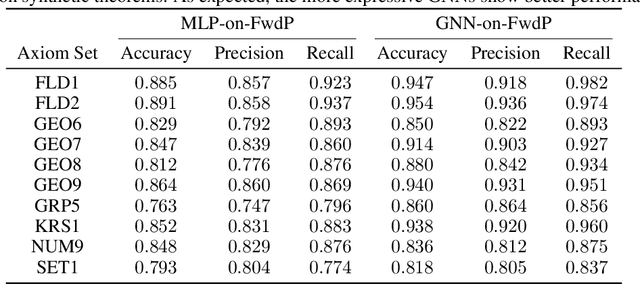
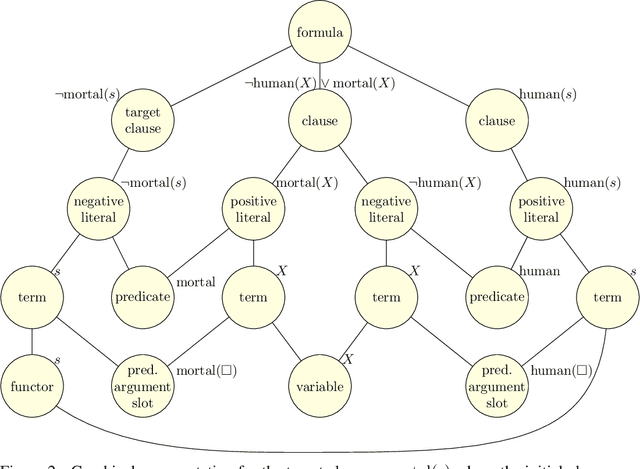
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.
Learning to cooperate: Emergent communication in multi-agent navigation
Apr 02, 2020



Emergent communication in artificial agents has been studied to understand language evolution, as well as to develop artificial systems that learn to communicate with humans. We show that agents performing a cooperative navigation task in various gridworld environments learn an interpretable communication protocol that enables them to efficiently, and in many cases, optimally, solve the task. An analysis of the agents' policies reveals that emergent signals spatially cluster the state space, with signals referring to specific locations and spatial directions such as "left", "up", or "upper left room". Using populations of agents, we show that the emergent protocol has basic compositional structure, thus exhibiting a core property of natural language.