 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021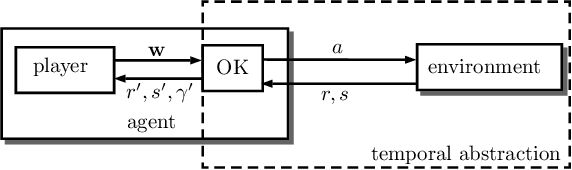
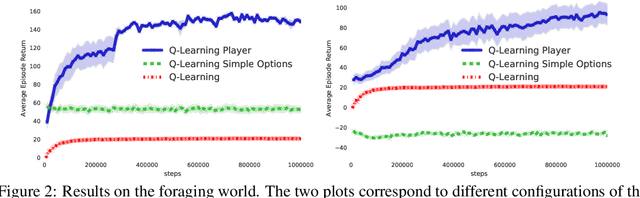
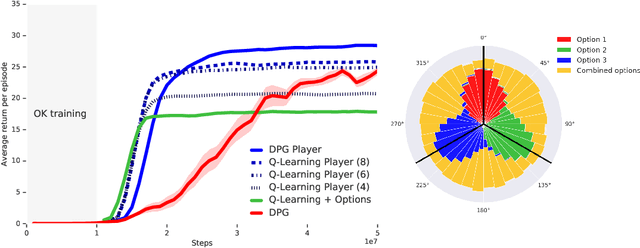
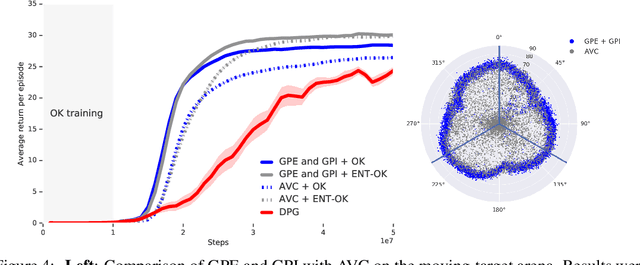
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
Deep Reinforcement Learning in Large Discrete Action Spaces
Apr 04, 2016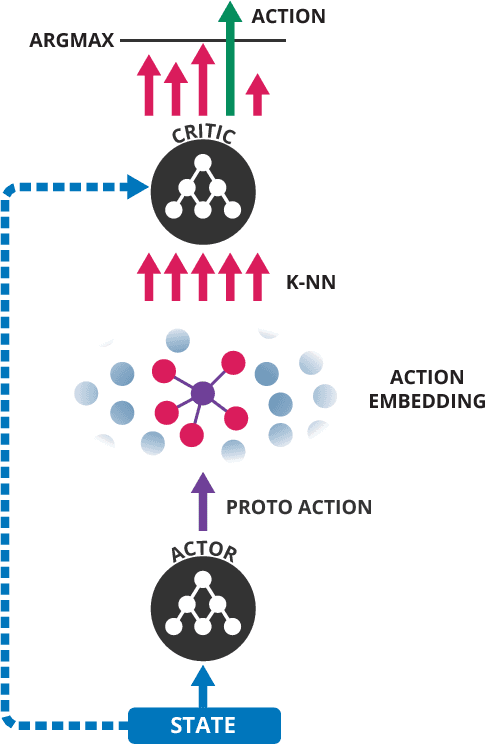

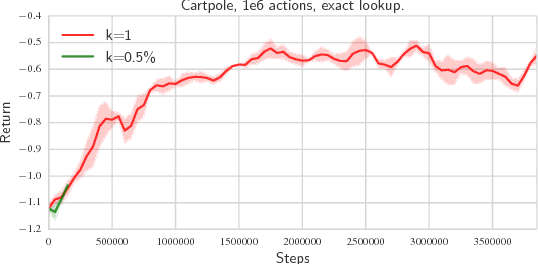
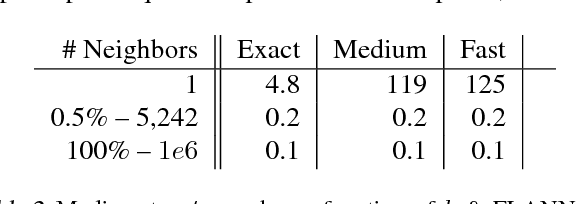
Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks involving large numbers of discrete actions for which current methods are difficult or even often impossible to apply. An ability to generalize over the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motivates the work in this paper. Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can generalize. Additionally, approximate nearest-neighbor methods allow for logarithmic-time lookup complexity relative to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learning methods to be applied to large-scale learning problems previously intractable with current methods. We demonstrate our algorithm's abilities on a series of tasks having up to one million actions.