 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Being Difficult: Combining Human and AI Strengths to Find Adversarial Instances for Heuristics
Jan 23, 2026We demonstrate the power of human-LLM collaboration in tackling open problems in theoretical computer science. Focusing on combinatorial optimization, we refine outputs from the FunSearch algorithm [Romera-Paredes et al., Nature 2023] to derive state-of-the-art lower bounds for standard heuristics. Specifically, we target the generation of adversarial instances where these heuristics perform poorly. By iterating on FunSearch's outputs, we identify improved constructions for hierarchical $k$-median clustering, bin packing, the knapsack problem, and a generalization of Lovász's gasoline problem - some of these have not seen much improvement for over a decade, despite intermittent attention. These results illustrate how expert oversight can effectively extrapolate algorithmic insights from LLM-based evolutionary methods to break long-standing barriers. Our findings demonstrate that while LLMs provide critical initial patterns, human expertise is essential for transforming these patterns into mathematically rigorous and insightful constructions. This work highlights that LLMs are a strong collaborative tool in mathematics and computer science research.
Evaluating Gemini in an arena for learning
May 30, 2025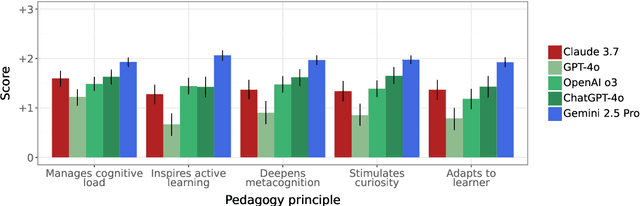

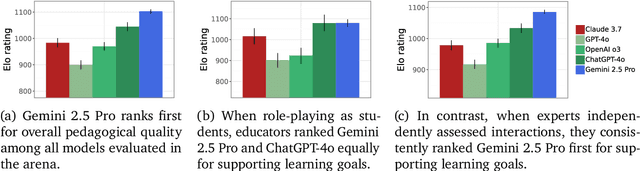
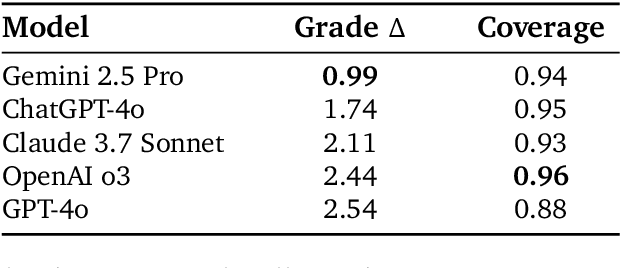
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
GRAIL: Graph Edit Distance and Node Alignment Using LLM-Generated Code
May 04, 2025Graph Edit Distance (GED) is a widely used metric for measuring similarity between two graphs. Computing the optimal GED is NP-hard, leading to the development of various neural and non-neural heuristics. While neural methods have achieved improved approximation quality compared to non-neural approaches, they face significant challenges: (1) They require large amounts of ground truth data, which is itself NP-hard to compute. (2) They operate as black boxes, offering limited interpretability. (3) They lack cross-domain generalization, necessitating expensive retraining for each new dataset. We address these limitations with GRAIL, introducing a paradigm shift in this domain. Instead of training a neural model to predict GED, GRAIL employs a novel combination of large language models (LLMs) and automated prompt tuning to generate a program that is used to compute GED. This shift from predicting GED to generating programs imparts various advantages, including end-to-end interpretability and an autonomous self-evolutionary learning mechanism without ground-truth supervision. Extensive experiments on seven datasets confirm that GRAIL not only surpasses state-of-the-art GED approximation methods in prediction quality but also achieves robust cross-domain generalization across diverse graph distributions.
Cracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning
Apr 24, 2025Agents that can autonomously navigate the web through a graphical user interface (GUI) using a unified action space (e.g., mouse and keyboard actions) can require very large amounts of domain-specific expert demonstrations to achieve good performance. Low sample efficiency is often exacerbated in sparse-reward and large-action-space environments, such as a web GUI, where only a few actions are relevant in any given situation. In this work, we consider the low-data regime, with limited or no access to expert behavior. To enable sample-efficient learning, we explore the effect of constraining the action space through $\textit{intent-based affordances}$ -- i.e., considering in any situation only the subset of actions that achieve a desired outcome. We propose $\textbf{Code as Generative Affordances}$ $(\textbf{$\texttt{CoGA}$})$, a method that leverages pre-trained vision-language models (VLMs) to generate code that determines affordable actions through implicit intent-completion functions and using a fully-automated program generation and verification pipeline. These programs are then used in-the-loop of a reinforcement learning agent to return a set of affordances given a pixel observation. By greatly reducing the number of actions that an agent must consider, we demonstrate on a wide range of tasks in the MiniWob++ benchmark that: $\textbf{1)}$ $\texttt{CoGA}$ is orders of magnitude more sample efficient than its RL agent, $\textbf{2)}$ $\texttt{CoGA}$'s programs can generalize within a family of tasks, and $\textbf{3)}$ $\texttt{CoGA}$ performs better or on par compared with behavior cloning when a small number of expert demonstrations is available.
LearnLM: Improving Gemini for Learning
Dec 21, 2024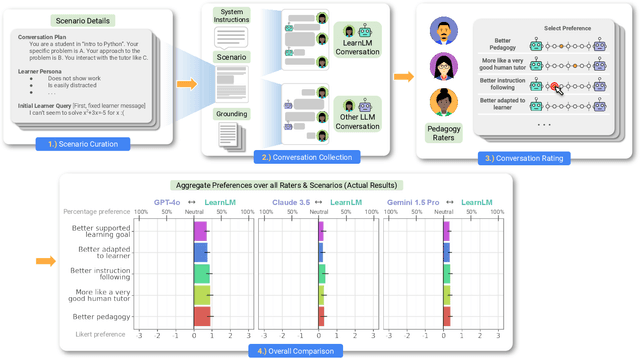
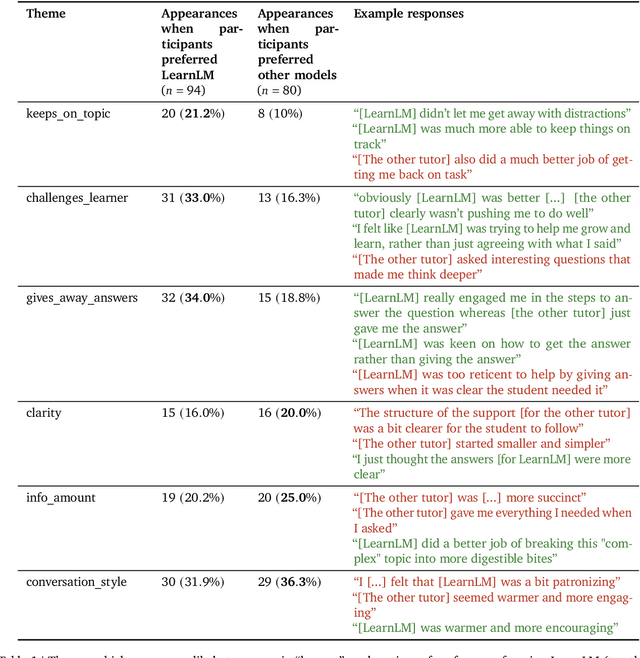
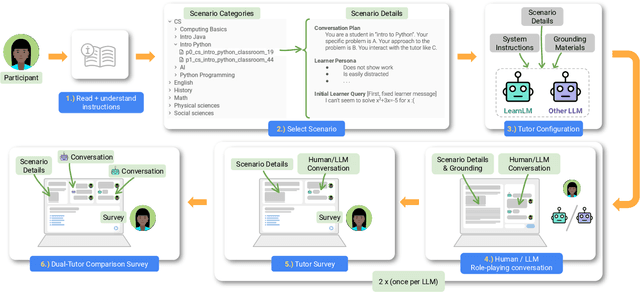
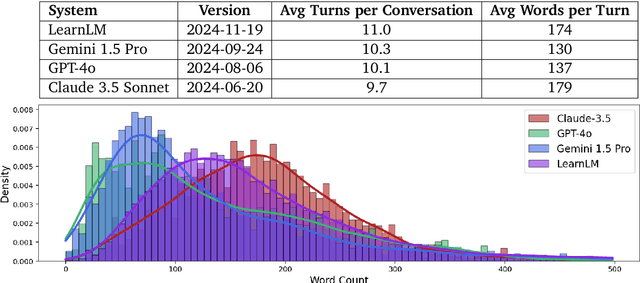
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
ReMI: A Dataset for Reasoning with Multiple Images
Jun 13, 2024



With the continuous advancement of large language models (LLMs), it is essential to create new benchmarks to effectively evaluate their expanding capabilities and identify areas for improvement. This work focuses on multi-image reasoning, an emerging capability in state-of-the-art LLMs. We introduce ReMI, a dataset designed to assess LLMs' ability to Reason with Multiple Images. This dataset encompasses a diverse range of tasks, spanning various reasoning domains such as math, physics, logic, code, table/chart understanding, and spatial and temporal reasoning. It also covers a broad spectrum of characteristics found in multi-image reasoning scenarios. We have benchmarked several cutting-edge LLMs using ReMI and found a substantial gap between their performance and human-level proficiency. This highlights the challenges in multi-image reasoning and the need for further research. Our analysis also reveals the strengths and weaknesses of different models, shedding light on the types of reasoning that are currently attainable and areas where future models require improvement. To foster further research in this area, we are releasing ReMI publicly: https://huggingface.co/datasets/mehrankazemi/ReMI.
Code as Reward: Empowering Reinforcement Learning with VLMs
Feb 07, 2024



Pre-trained Vision-Language Models (VLMs) are able to understand visual concepts, describe and decompose complex tasks into sub-tasks, and provide feedback on task completion. In this paper, we aim to leverage these capabilities to support the training of reinforcement learning (RL) agents. In principle, VLMs are well suited for this purpose, as they can naturally analyze image-based observations and provide feedback (reward) on learning progress. However, inference in VLMs is computationally expensive, so querying them frequently to compute rewards would significantly slowdown the training of an RL agent. To address this challenge, we propose a framework named Code as Reward (VLM-CaR). VLM-CaR produces dense reward functions from VLMs through code generation, thereby significantly reducing the computational burden of querying the VLM directly. We show that the dense rewards generated through our approach are very accurate across a diverse set of discrete and continuous environments, and can be more effective in training RL policies than the original sparse environment rewards.
Transfer Learning for the Prediction of Entity Modifiers in Clinical Text: Application to Opioid Use Disorder Case Detection
Feb 05, 2024Background: The semantics of entities extracted from a clinical text can be dramatically altered by modifiers, including entity negation, uncertainty, conditionality, severity, and subject. Existing models for determining modifiers of clinical entities involve regular expression or features weights that are trained independently for each modifier. Methods: We develop and evaluate a multi-task transformer architecture design where modifiers are learned and predicted jointly using the publicly available SemEval 2015 Task 14 corpus and a new Opioid Use Disorder (OUD) data set that contains modifiers shared with SemEval as well as novel modifiers specific for OUD. We evaluate the effectiveness of our multi-task learning approach versus previously published systems and assess the feasibility of transfer learning for clinical entity modifiers when only a portion of clinical modifiers are shared. Results: Our approach achieved state-of-the-art results on the ShARe corpus from SemEval 2015 Task 14, showing an increase of 1.1% on weighted accuracy, 1.7% on unweighted accuracy, and 10% on micro F1 scores. Conclusions: We show that learned weights from our shared model can be effectively transferred to a new partially matched data set, validating the use of transfer learning for clinical text modifiers
GeomVerse: A Systematic Evaluation of Large Models for Geometric Reasoning
Dec 19, 2023Large language models have shown impressive results for multi-hop mathematical reasoning when the input question is only textual. Many mathematical reasoning problems, however, contain both text and image. With the ever-increasing adoption of vision language models (VLMs), understanding their reasoning abilities for such problems is crucial. In this paper, we evaluate the reasoning capabilities of VLMs along various axes through the lens of geometry problems. We procedurally create a synthetic dataset of geometry questions with controllable difficulty levels along multiple axes, thus enabling a systematic evaluation. The empirical results obtained using our benchmark for state-of-the-art VLMs indicate that these models are not as capable in subjects like geometry (and, by generalization, other topics requiring similar reasoning) as suggested by previous benchmarks. This is made especially clear by the construction of our benchmark at various depth levels, since solving higher-depth problems requires long chains of reasoning rather than additional memorized knowledge. We release the dataset for further research in this area.
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search
Nov 06, 2023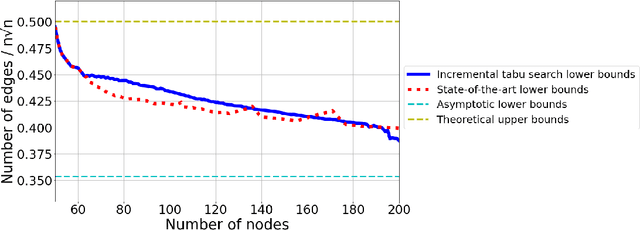
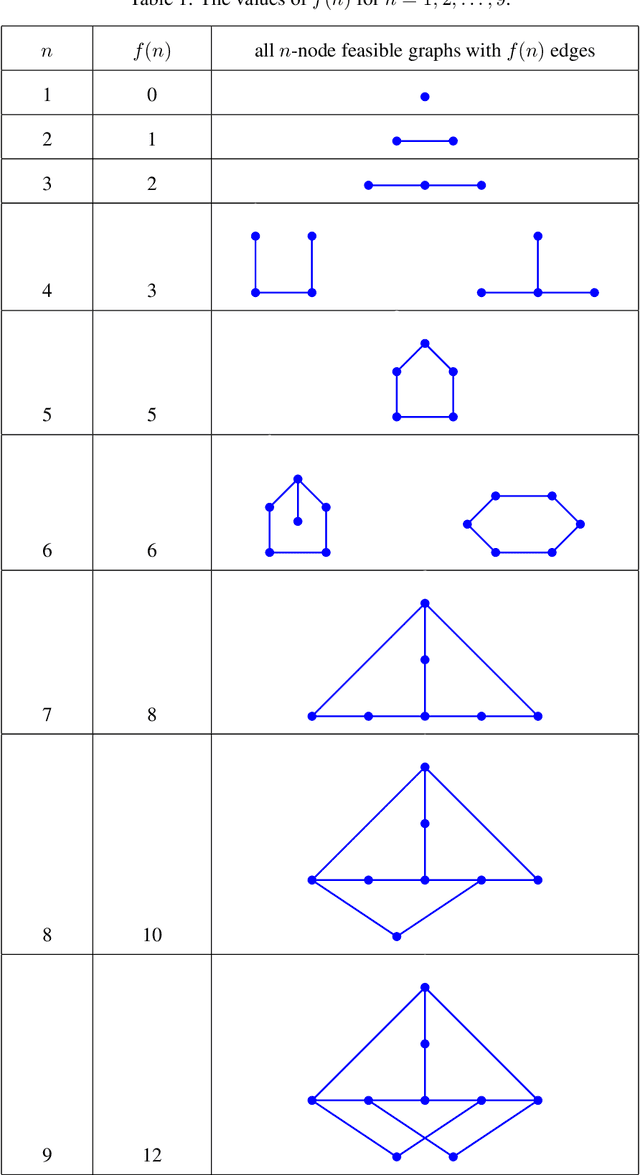
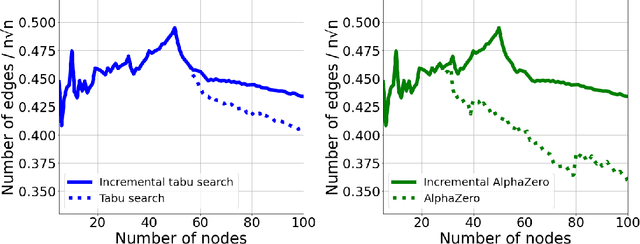

This work studies a central extremal graph theory problem inspired by a 1975 conjecture of Erd\H{o}s, which aims to find graphs with a given size (number of nodes) that maximize the number of edges without having 3- or 4-cycles. We formulate this problem as a sequential decision-making problem and compare AlphaZero, a neural network-guided tree search, with tabu search, a heuristic local search method. Using either method, by introducing a curriculum -- jump-starting the search for larger graphs using good graphs found at smaller sizes -- we improve the state-of-the-art lower bounds for several sizes. We also propose a flexible graph-generation environment and a permutation-invariant network architecture for learning to search in the space of graphs.