 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntailed Between the Lines: Incorporating Implication into NLI
Jan 13, 2025Much of human communication depends on implication, conveying meaning beyond literal words to express a wider range of thoughts, intentions, and feelings. For models to better understand and facilitate human communication, they must be responsive to the text's implicit meaning. We focus on Natural Language Inference (NLI), a core tool for many language tasks, and find that state-of-the-art NLI models and datasets struggle to recognize a range of cases where entailment is implied, rather than explicit from the text. We formalize implied entailment as an extension of the NLI task and introduce the Implied NLI dataset (INLI) to help today's LLMs both recognize a broader variety of implied entailments and to distinguish between implicit and explicit entailment. We show how LLMs fine-tuned on INLI understand implied entailment and can generalize this understanding across datasets and domains.
Towards Realistic Synthetic User-Generated Content: A Scaffolding Approach to Generating Online Discussions
Aug 15, 2024

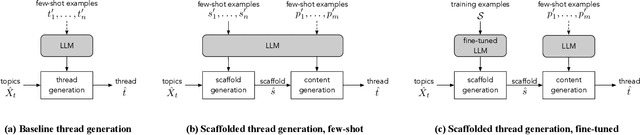

The emergence of synthetic data represents a pivotal shift in modern machine learning, offering a solution to satisfy the need for large volumes of data in domains where real data is scarce, highly private, or difficult to obtain. We investigate the feasibility of creating realistic, large-scale synthetic datasets of user-generated content, noting that such content is increasingly prevalent and a source of frequently sought information. Large language models (LLMs) offer a starting point for generating synthetic social media discussion threads, due to their ability to produce diverse responses that typify online interactions. However, as we demonstrate, straightforward application of LLMs yields limited success in capturing the complex structure of online discussions, and standard prompting mechanisms lack sufficient control. We therefore propose a multi-step generation process, predicated on the idea of creating compact representations of discussion threads, referred to as scaffolds. Our framework is generic yet adaptable to the unique characteristics of specific social media platforms. We demonstrate its feasibility using data from two distinct online discussion platforms. To address the fundamental challenge of ensuring the representativeness and realism of synthetic data, we propose a portfolio of evaluation measures to compare various instantiations of our framework.
SocialQuotes: Learning Contextual Roles of Social Media Quotes on the Web
Jul 22, 2024Web authors frequently embed social media to support and enrich their content, creating the potential to derive web-based, cross-platform social media representations that can enable more effective social media retrieval systems and richer scientific analyses. As step toward such capabilities, we introduce a novel language modeling framework that enables automatic annotation of roles that social media entities play in their embedded web context. Using related communication theory, we liken social media embeddings to quotes, formalize the page context as structured natural language signals, and identify a taxonomy of roles for quotes within the page context. We release SocialQuotes, a new data set built from the Common Crawl of over 32 million social quotes, 8.3k of them with crowdsourced quote annotations. Using SocialQuotes and the accompanying annotations, we provide a role classification case study, showing reasonable performance with modern-day LLMs, and exposing explainable aspects of our framework via page content ablations. We also classify a large batch of un-annotated quotes, revealing interesting cross-domain, cross-platform role distributions on the web.
GeomVerse: A Systematic Evaluation of Large Models for Geometric Reasoning
Dec 19, 2023Large language models have shown impressive results for multi-hop mathematical reasoning when the input question is only textual. Many mathematical reasoning problems, however, contain both text and image. With the ever-increasing adoption of vision language models (VLMs), understanding their reasoning abilities for such problems is crucial. In this paper, we evaluate the reasoning capabilities of VLMs along various axes through the lens of geometry problems. We procedurally create a synthetic dataset of geometry questions with controllable difficulty levels along multiple axes, thus enabling a systematic evaluation. The empirical results obtained using our benchmark for state-of-the-art VLMs indicate that these models are not as capable in subjects like geometry (and, by generalization, other topics requiring similar reasoning) as suggested by previous benchmarks. This is made especially clear by the construction of our benchmark at various depth levels, since solving higher-depth problems requires long chains of reasoning rather than additional memorized knowledge. We release the dataset for further research in this area.
Mitigating Bias in Online Microfinance Platforms: A Case Study on Kiva.org
Jun 20, 2020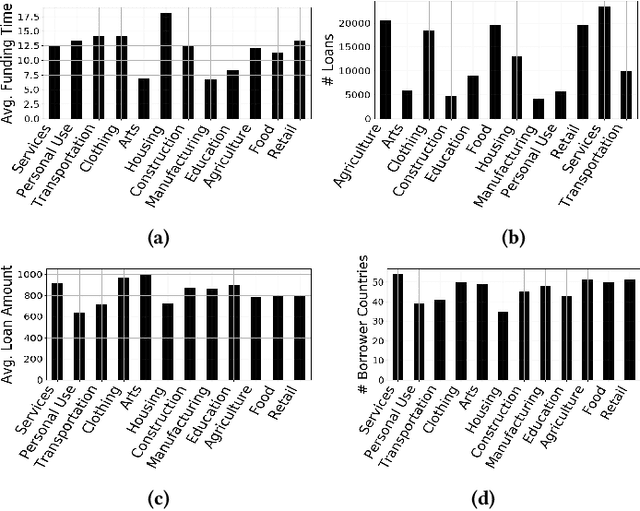

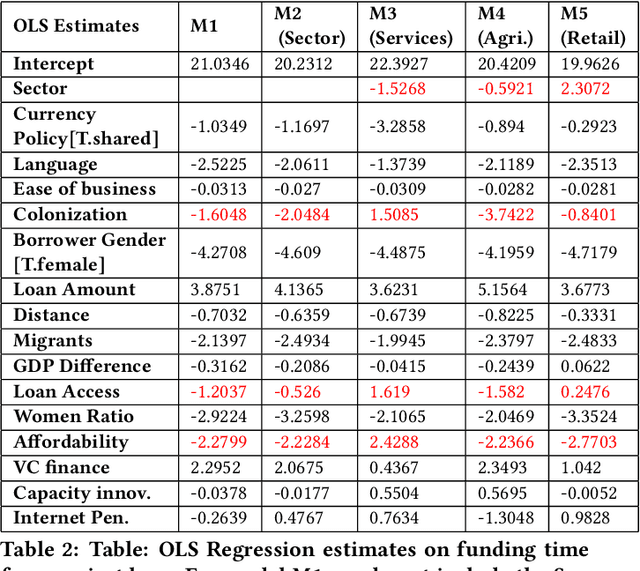
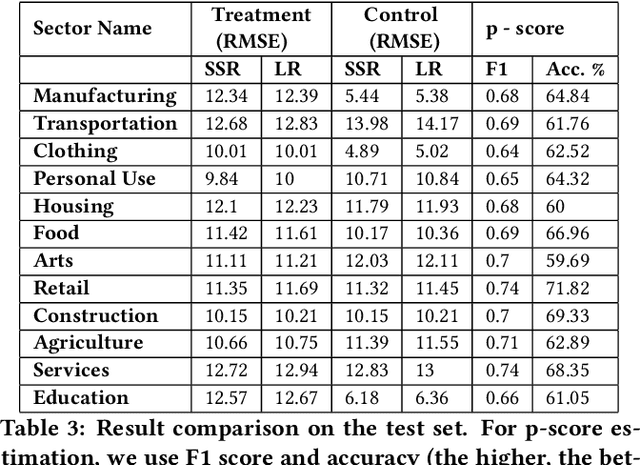
Over the last couple of decades in the lending industry, financial disintermediation has occurred on a global scale. Traditionally, even for small supply of funds, banks would act as the conduit between the funds and the borrowers. It has now been possible to overcome some of the obstacles associated with such supply of funds with the advent of online platforms like Kiva, Prosper, LendingClub. Kiva for example, works with Micro Finance Institutions (MFIs) in developing countries to build Internet profiles of borrowers with a brief biography, loan requested, loan term, and purpose. Kiva, in particular, allows lenders to fund projects in different sectors through group or individual funding. Traditional research studies have investigated various factors behind lender preferences purely from the perspective of loan attributes and only until recently have some cross-country cultural preferences been investigated. In this paper, we investigate lender perceptions of economic factors of the borrower countries in relation to their preferences towards loans associated with different sectors. We find that the influence from economic factors and loan attributes can have substantially different roles to play for different sectors in achieving faster funding. We formally investigate and quantify the hidden biases prevalent in different loan sectors using recent tools from causal inference and regression models that rely on Bayesian variable selection methods. We then extend these models to incorporate fairness constraints based on our empirical analysis and find that such models can still achieve near comparable results with respect to baseline regression models.
An End-to-End Framework to Identify Pathogenic Social Media Accounts on Twitter
May 04, 2019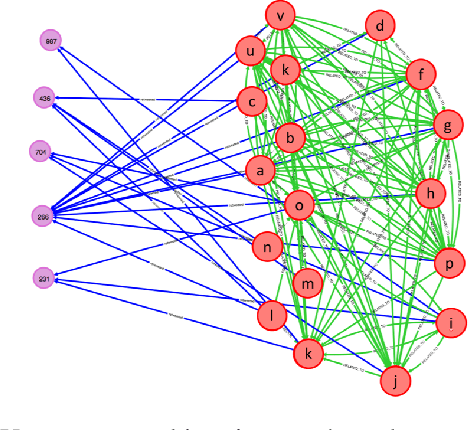
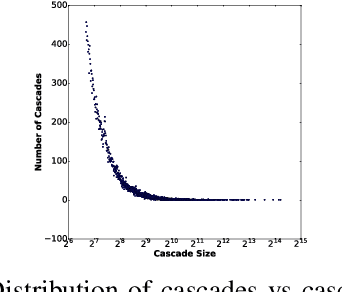

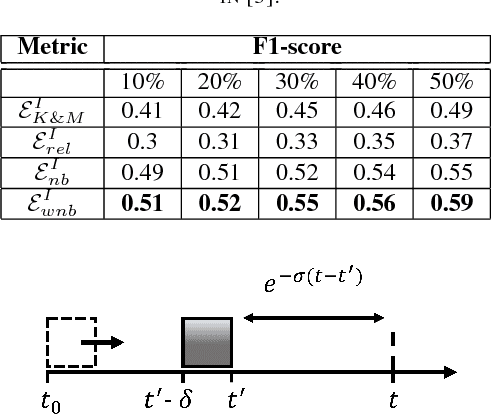
Pathogenic Social Media (PSM) accounts such as terrorist supporter accounts and fake news writers have the capability of spreading disinformation to viral proportions. Early detection of PSM accounts is crucial as they are likely to be key users to make malicious information "viral". In this paper, we adopt the causal inference framework along with graph-based metrics in order to distinguish PSMs from normal users within a short time of their activities. We propose both supervised and semi-supervised approaches without taking the network information and content into account. Results on a real-world dataset from Twitter accentuates the advantage of our proposed frameworks. We show our approach achieves 0.28 improvement in F1 score over existing approaches with the precision of 0.90 and F1 score of 0.63.
Early Identification of Pathogenic Social Media Accounts
Sep 26, 2018


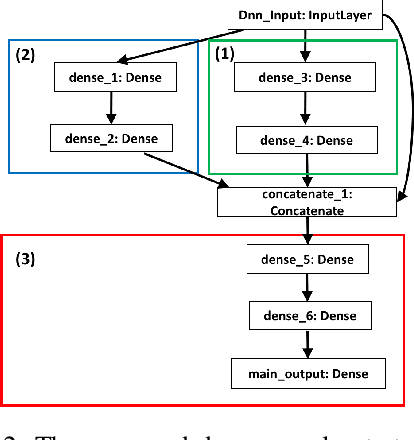
Pathogenic Social Media (PSM) accounts such as terrorist supporters exploit large communities of supporters for conducting attacks on social media. Early detection of these accounts is crucial as they are high likely to be key users in making a harmful message "viral". In this paper, we make the first attempt on utilizing causal inference to identify PSMs within a short time frame around their activity. We propose a time-decay causality metric and incorporate it into a causal community detection-based algorithm. The proposed algorithm is applied to groups of accounts sharing similar causality features and is followed by a classification algorithm to classify accounts as PSM or not. Unlike existing techniques that take significant time to collect information such as network, cascade path, or content, our scheme relies solely on action log of users. Results on a real-world dataset from Twitter demonstrate effectiveness and efficiency of our approach. We achieved precision of 0.84 for detecting PSMs only based on their first 10 days of activity; the misclassified accounts were then detected 10 days later.
Causal Inference for Early Detection of Pathogenic Social Media Accounts
Aug 03, 2018Pathogenic social media accounts such as terrorist supporters exploit communities of supporters for conducting attacks on social media. Early detection of PSM accounts is crucial as they are likely to be key users in making a harmful message "viral". This paper overviews my recent doctoral work on utilizing causal inference to identify PSM accounts within a short time frame around their activity. The proposed scheme (1) assigns time-decay causality scores to users, (2) applies a community detection-based algorithm to group of users sharing similar causality scores and finally (3) deploys a classification algorithm to classify accounts. Unlike existing techniques that require network structure, cascade path, or content, our scheme relies solely on action log of users.
Strongly Hierarchical Factorization Machines and ANOVA Kernel Regression
Jan 05, 2018
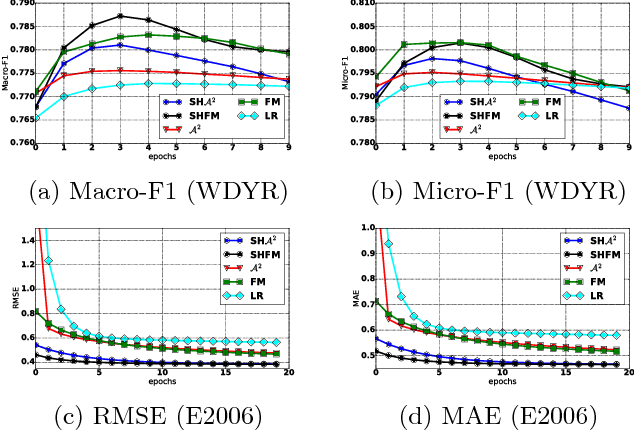
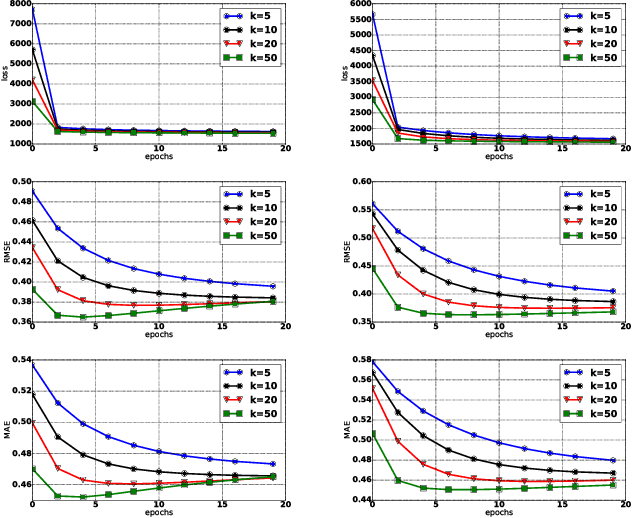
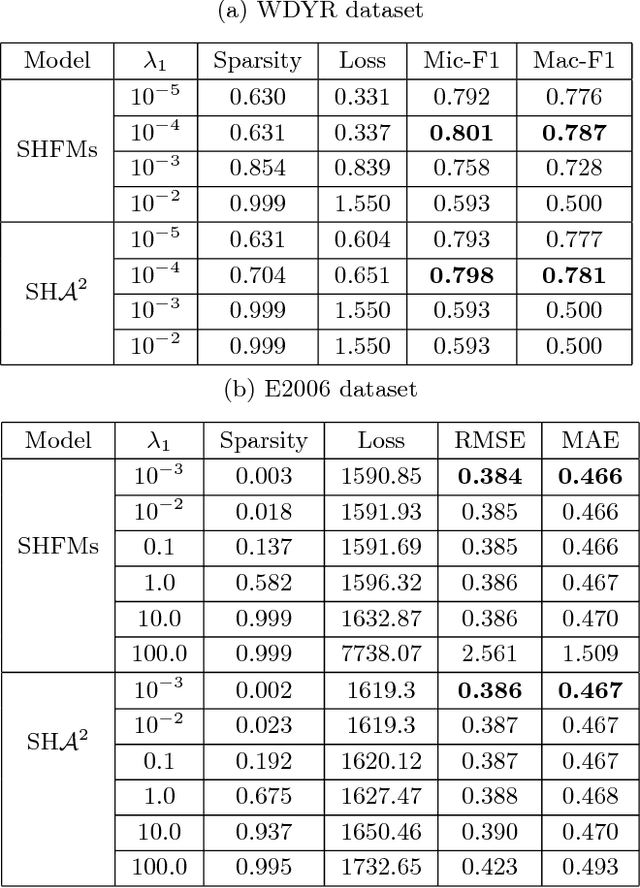
High-order parametric models that include terms for feature interactions are applied to various data mining tasks, where ground truth depends on interactions of features. However, with sparse data, the high- dimensional parameters for feature interactions often face three issues: expensive computation, difficulty in parameter estimation and lack of structure. Previous work has proposed approaches which can partially re- solve the three issues. In particular, models with factorized parameters (e.g. Factorization Machines) and sparse learning algorithms (e.g. FTRL-Proximal) can tackle the first two issues but fail to address the third. Regarding to unstructured parameters, constraints or complicated regularization terms are applied such that hierarchical structures can be imposed. However, these methods make the optimization problem more challenging. In this work, we propose Strongly Hierarchical Factorization Machines and ANOVA kernel regression where all the three issues can be addressed without making the optimization problem more difficult. Experimental results show the proposed models significantly outperform the state-of-the-art in two data mining tasks: cold-start user response time prediction and stock volatility prediction.
Semi-Supervised Learning for Detecting Human Trafficking
May 30, 2017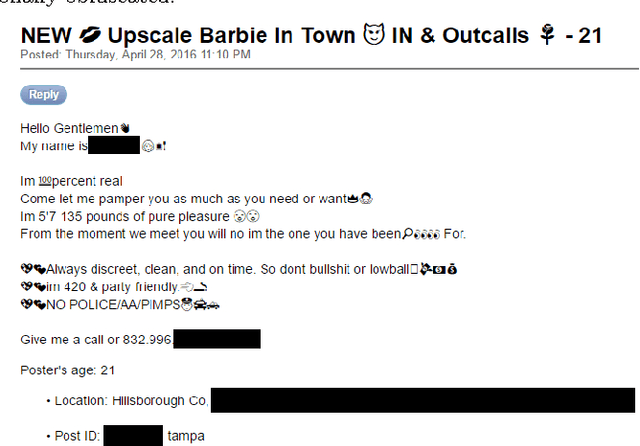
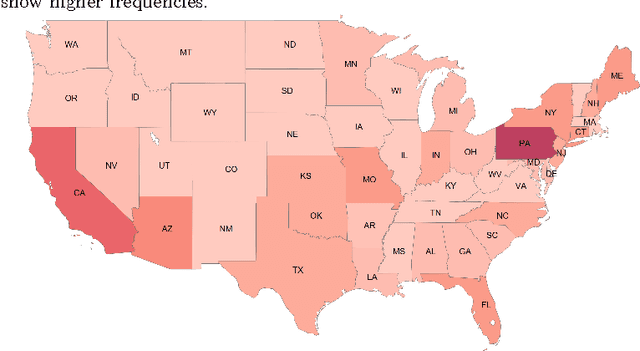
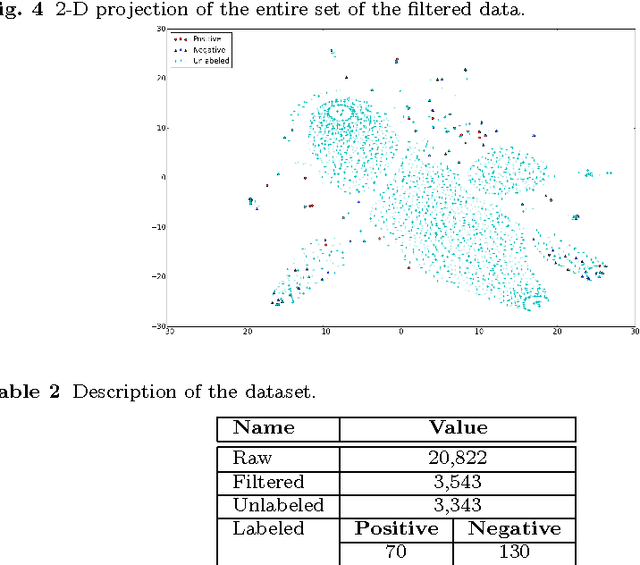
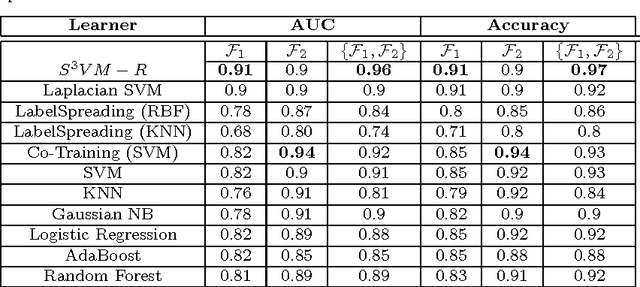
Human trafficking is one of the most atrocious crimes and among the challenging problems facing law enforcement which demands attention of global magnitude. In this study, we leverage textual data from the website "Backpage"- used for classified advertisement- to discern potential patterns of human trafficking activities which manifest online and identify advertisements of high interest to law enforcement. Due to the lack of ground truth, we rely on a human analyst from law enforcement, for hand-labeling a small portion of the crawled data. We extend the existing Laplacian SVM and present S3VM-R, by adding a regularization term to exploit exogenous information embedded in our feature space in favor of the task at hand. We train the proposed method using labeled and unlabeled data and evaluate it on a fraction of the unlabeled data, herein referred to as unseen data, with our expert's further verification. Results from comparisons between our method and other semi-supervised and supervised approaches on the labeled data demonstrate that our learner is effective in identifying advertisements of high interest to law enforcement