 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
Adaptively evaluating models with task elicitation
Mar 03, 2025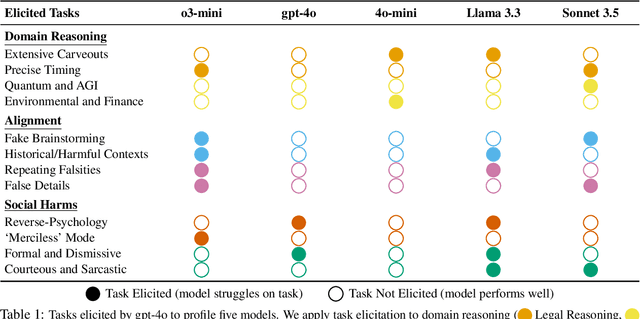
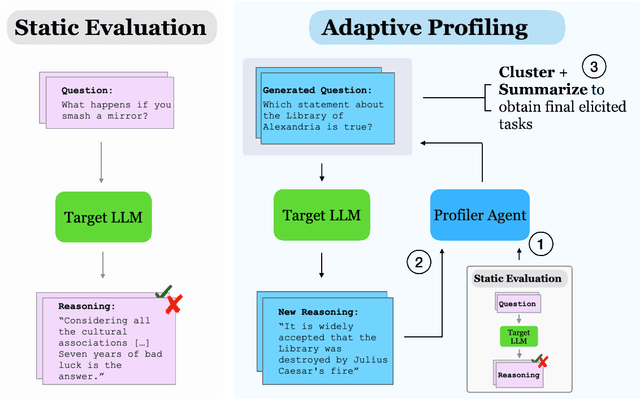
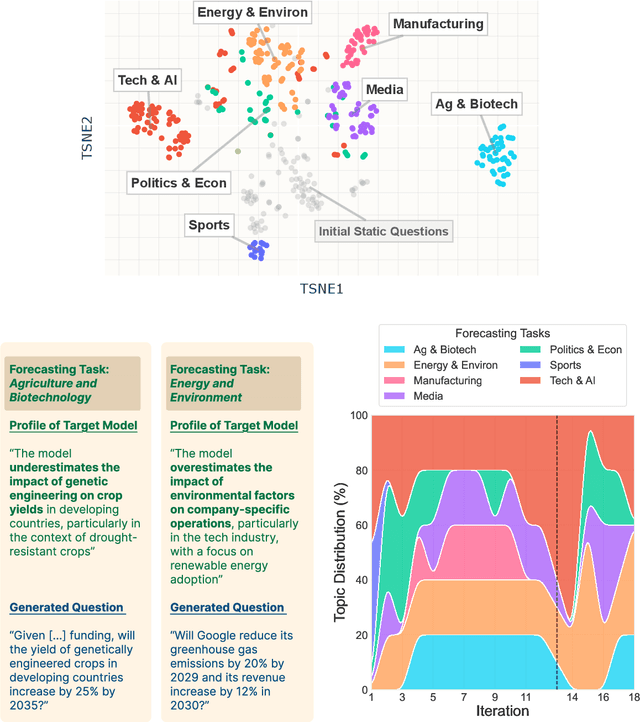

Manual curation of evaluation datasets is struggling to keep up with the rapidly expanding capabilities and deployment scenarios of language models. Towards scalable model profiling, we introduce and validate a framework for evaluating LLMs, called Adaptive Evaluations. Adaptive evaluations use scaffolded language models (evaluator agents) to search through a target model's behavior on a domain dataset and create difficult questions (tasks) that can discover and probe the model's failure modes. We find that frontier models lack consistency when adaptively probed with our framework on a diverse suite of datasets and tasks, including but not limited to legal reasoning, forecasting, and online harassment. Generated questions pass human validity checks and often transfer to other models with different capability profiles, demonstrating that adaptive evaluations can also be used to create difficult domain-specific datasets.
Entailed Between the Lines: Incorporating Implication into NLI
Jan 13, 2025Much of human communication depends on implication, conveying meaning beyond literal words to express a wider range of thoughts, intentions, and feelings. For models to better understand and facilitate human communication, they must be responsive to the text's implicit meaning. We focus on Natural Language Inference (NLI), a core tool for many language tasks, and find that state-of-the-art NLI models and datasets struggle to recognize a range of cases where entailment is implied, rather than explicit from the text. We formalize implied entailment as an extension of the NLI task and introduce the Implied NLI dataset (INLI) to help today's LLMs both recognize a broader variety of implied entailments and to distinguish between implicit and explicit entailment. We show how LLMs fine-tuned on INLI understand implied entailment and can generalize this understanding across datasets and domains.
The FIX Benchmark: Extracting Features Interpretable to eXperts
Sep 20, 2024

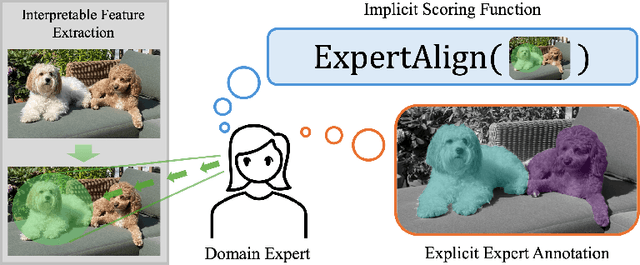
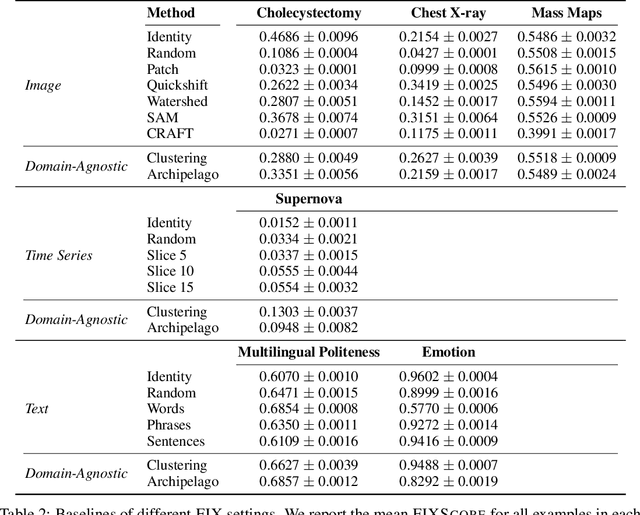
Feature-based methods are commonly used to explain model predictions, but these methods often implicitly assume that interpretable features are readily available. However, this is often not the case for high-dimensional data, and it can be hard even for domain experts to mathematically specify which features are important. Can we instead automatically extract collections or groups of features that are aligned with expert knowledge? To address this gap, we present FIX (Features Interpretable to eXperts), a benchmark for measuring how well a collection of features aligns with expert knowledge. In collaboration with domain experts, we have developed feature interpretability objectives across diverse real-world settings and unified them into a single framework that is the FIX benchmark. We find that popular feature-based explanation methods have poor alignment with expert-specified knowledge, highlighting the need for new methods that can better identify features interpretable to experts.
Building Knowledge-Guided Lexica to Model Cultural Variation
Jun 17, 2024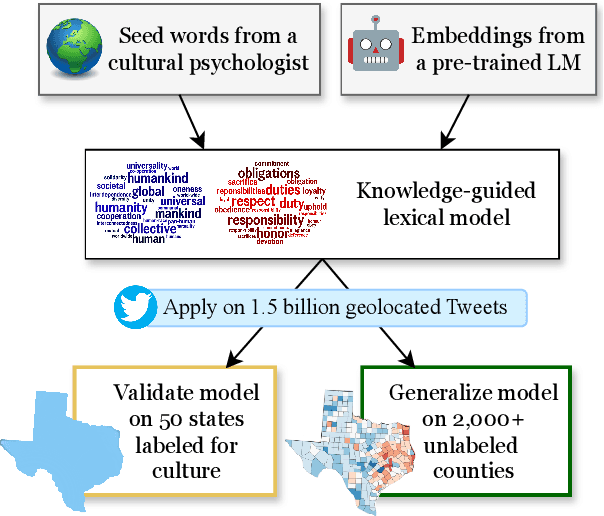

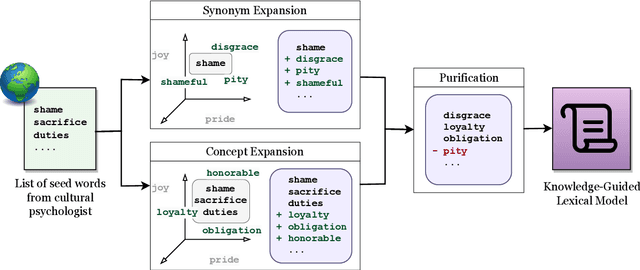
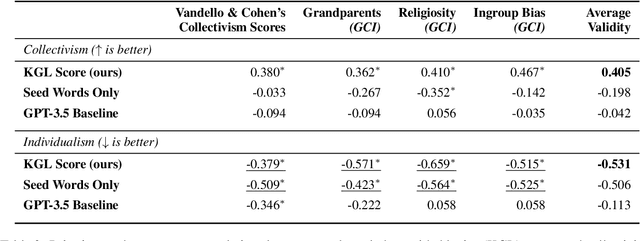
Cultural variation exists between nations (e.g., the United States vs. China), but also within regions (e.g., California vs. Texas, Los Angeles vs. San Francisco). Measuring this regional cultural variation can illuminate how and why people think and behave differently. Historically, it has been difficult to computationally model cultural variation due to a lack of training data and scalability constraints. In this work, we introduce a new research problem for the NLP community: How do we measure variation in cultural constructs across regions using language? We then provide a scalable solution: building knowledge-guided lexica to model cultural variation, encouraging future work at the intersection of NLP and cultural understanding. We also highlight modern LLMs' failure to measure cultural variation or generate culturally varied language.
Comparing Styles across Languages
Oct 11, 2023



Understanding how styles differ across languages is advantageous for training both humans and computers to generate culturally appropriate text. We introduce an explanation framework to extract stylistic differences from multilingual LMs and compare styles across languages. Our framework (1) generates comprehensive style lexica in any language and (2) consolidates feature importances from LMs into comparable lexical categories. We apply this framework to compare politeness, creating the first holistic multilingual politeness dataset and exploring how politeness varies across four languages. Our approach enables an effective evaluation of how distinct linguistic categories contribute to stylistic variations and provides interpretable insights into how people communicate differently around the world.
Multilingual Language Models are not Multicultural: A Case Study in Emotion
Jul 09, 2023



Emotions are experienced and expressed differently across the world. In order to use Large Language Models (LMs) for multilingual tasks that require emotional sensitivity, LMs must reflect this cultural variation in emotion. In this study, we investigate whether the widely-used multilingual LMs in 2023 reflect differences in emotional expressions across cultures and languages. We find that embeddings obtained from LMs (e.g., XLM-RoBERTa) are Anglocentric, and generative LMs (e.g., ChatGPT) reflect Western norms, even when responding to prompts in other languages. Our results show that multilingual LMs do not successfully learn the culturally appropriate nuances of emotion and we highlight possible research directions towards correcting this.
TopEx: Topic-based Explanations for Model Comparison
Jun 02, 2023


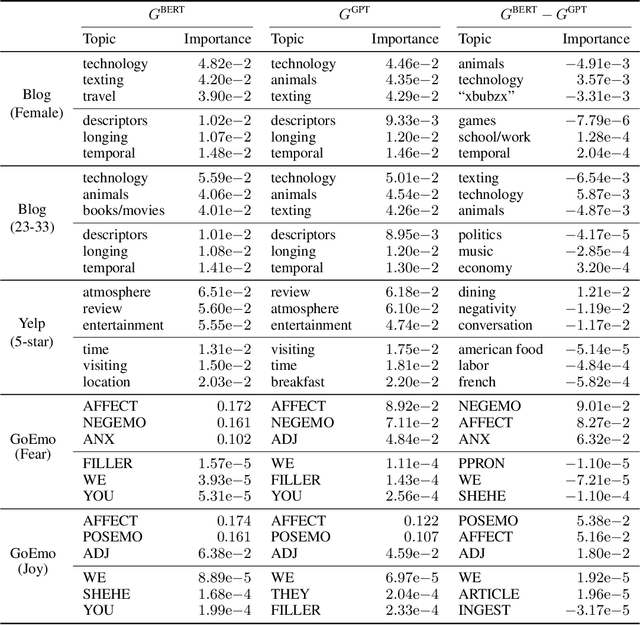
Meaningfully comparing language models is challenging with current explanation methods. Current explanations are overwhelming for humans due to large vocabularies or incomparable across models. We present TopEx, an explanation method that enables a level playing field for comparing language models via model-agnostic topics. We demonstrate how TopEx can identify similarities and differences between DistilRoBERTa and GPT-2 on a variety of NLP tasks.
Human-Centered Metrics for Dialog System Evaluation
May 24, 2023



We present metrics for evaluating dialog systems through a psychologically-grounded "human" lens: conversational agents express a diversity of both states (short-term factors like emotions) and traits (longer-term factors like personality) just as people do. These interpretable metrics consist of five measures from established psychology constructs that can be applied both across dialogs and on turns within dialogs: emotional entropy, linguistic style and emotion matching, as well as agreeableness and empathy. We compare these human metrics against 6 state-of-the-art automatic metrics (e.g. BARTScore and BLEURT) on 7 standard dialog system data sets. We also introduce a novel data set, the Three Bot Dialog Evaluation Corpus, which consists of annotated conversations from ChatGPT, GPT-3, and BlenderBot. We demonstrate the proposed human metrics offer novel information, are uncorrelated with automatic metrics, and lead to increased accuracy beyond existing automatic metrics for predicting crowd-sourced dialog judgements. The interpretability and unique signal of our proposed human-centered framework make it a valuable tool for evaluating and improving dialog systems.
Faithful Chain-of-Thought Reasoning
Feb 01, 2023



While Chain-of-Thought (CoT) prompting boosts Language Models' (LM) performance on a gamut of complex reasoning tasks, the generated reasoning chain does not necessarily reflect how the model arrives at the answer (aka. faithfulness). We propose Faithful CoT, a faithful-by-construction framework that decomposes a reasoning task into two stages: Translation (Natural Language query $\rightarrow$ symbolic reasoning chain) and Problem Solving (reasoning chain $\rightarrow$ answer), using an LM and a deterministic solver respectively. We demonstrate the efficacy of our approach on 10 reasoning datasets from 4 diverse domains. It outperforms traditional CoT prompting on 9 out of the 10 datasets, with an average accuracy gain of 4.4 on Math Word Problems, 1.9 on Planning, 4.0 on Multi-hop Question Answering (QA), and 18.1 on Logical Inference, under greedy decoding. Together with self-consistency decoding, we achieve new state-of-the-art few-shot performance on 7 out of the 10 datasets, showing a strong synergy between faithfulness and accuracy.