 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Knowledge-Guided Lexica to Model Cultural Variation
Jun 17, 2024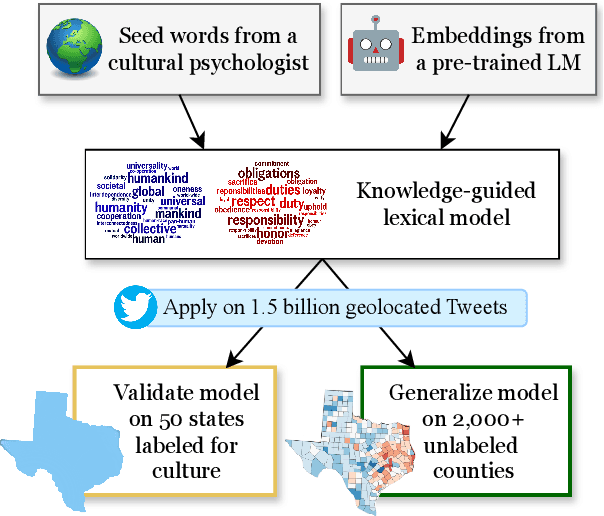

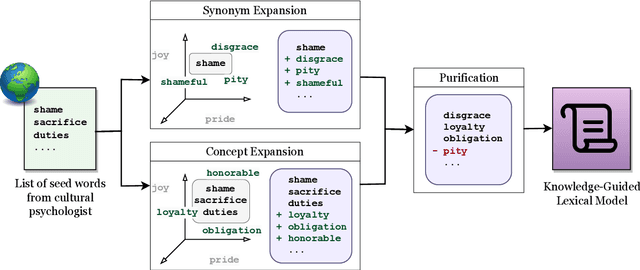
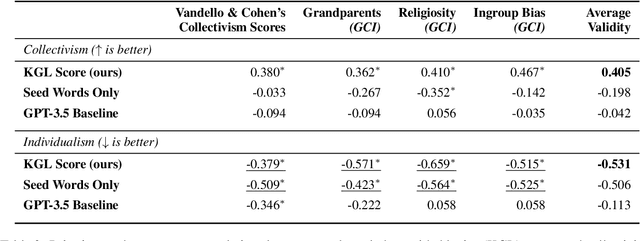
Cultural variation exists between nations (e.g., the United States vs. China), but also within regions (e.g., California vs. Texas, Los Angeles vs. San Francisco). Measuring this regional cultural variation can illuminate how and why people think and behave differently. Historically, it has been difficult to computationally model cultural variation due to a lack of training data and scalability constraints. In this work, we introduce a new research problem for the NLP community: How do we measure variation in cultural constructs across regions using language? We then provide a scalable solution: building knowledge-guided lexica to model cultural variation, encouraging future work at the intersection of NLP and cultural understanding. We also highlight modern LLMs' failure to measure cultural variation or generate culturally varied language.
Historical patterns of rice farming explain modern-day language use in China and Japan more than modernization and urbanization
Aug 29, 2023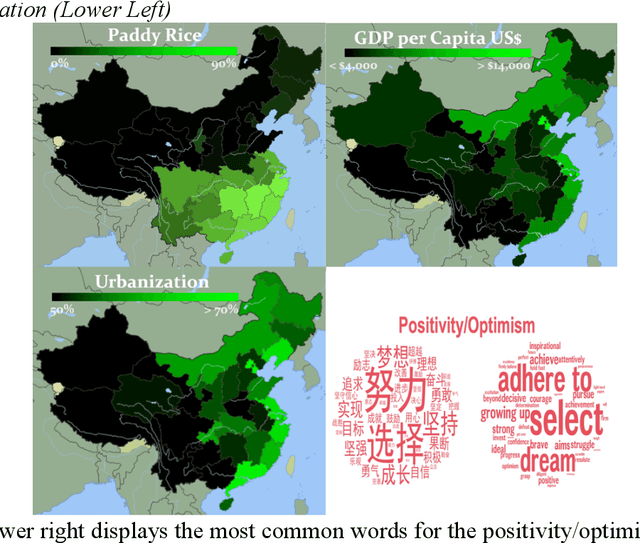


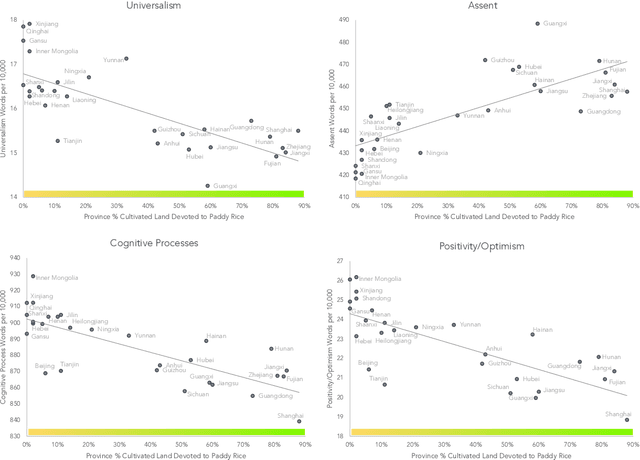
We used natural language processing to analyze a billion words to study cultural differences on Weibo, one of China's largest social media platforms. We compared predictions from two common explanations about cultural differences in China (economic development and urban-rural differences) against the less-obvious legacy of rice versus wheat farming. Rice farmers had to coordinate shared irrigation networks and exchange labor to cope with higher labor requirements. In contrast, wheat relied on rainfall and required half as much labor. We test whether this legacy made southern China more interdependent. Across all word categories, rice explained twice as much variance as economic development and urbanization. Rice areas used more words reflecting tight social ties, holistic thought, and a cautious, prevention orientation. We then used Twitter data comparing prefectures in Japan, which largely replicated the results from China. This provides crucial evidence of the rice theory in a different nation, language, and platform.