 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
The FIX Benchmark: Extracting Features Interpretable to eXperts
Sep 20, 2024

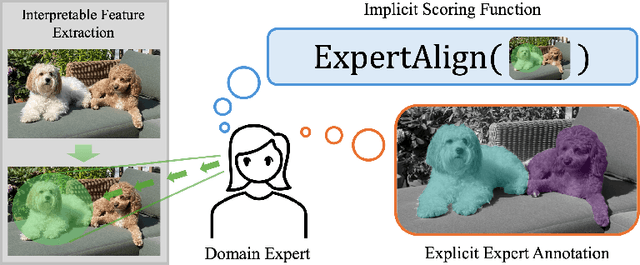
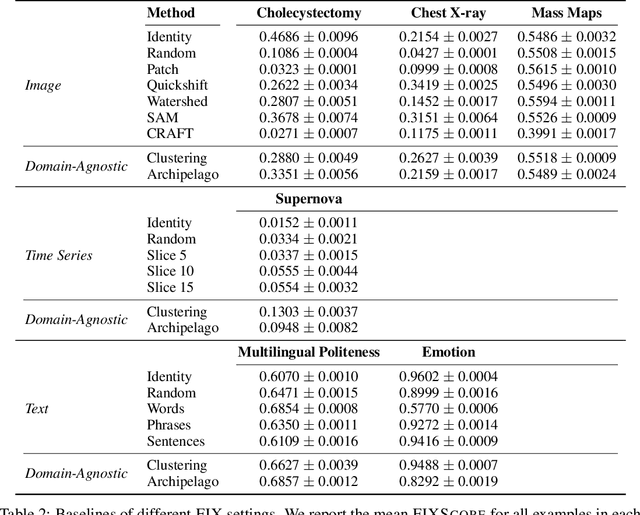
Feature-based methods are commonly used to explain model predictions, but these methods often implicitly assume that interpretable features are readily available. However, this is often not the case for high-dimensional data, and it can be hard even for domain experts to mathematically specify which features are important. Can we instead automatically extract collections or groups of features that are aligned with expert knowledge? To address this gap, we present FIX (Features Interpretable to eXperts), a benchmark for measuring how well a collection of features aligns with expert knowledge. In collaboration with domain experts, we have developed feature interpretability objectives across diverse real-world settings and unified them into a single framework that is the FIX benchmark. We find that popular feature-based explanation methods have poor alignment with expert-specified knowledge, highlighting the need for new methods that can better identify features interpretable to experts.
At First Sight: Zero-Shot Classification of Astronomical Images with Large Multimodal Models
Jun 24, 2024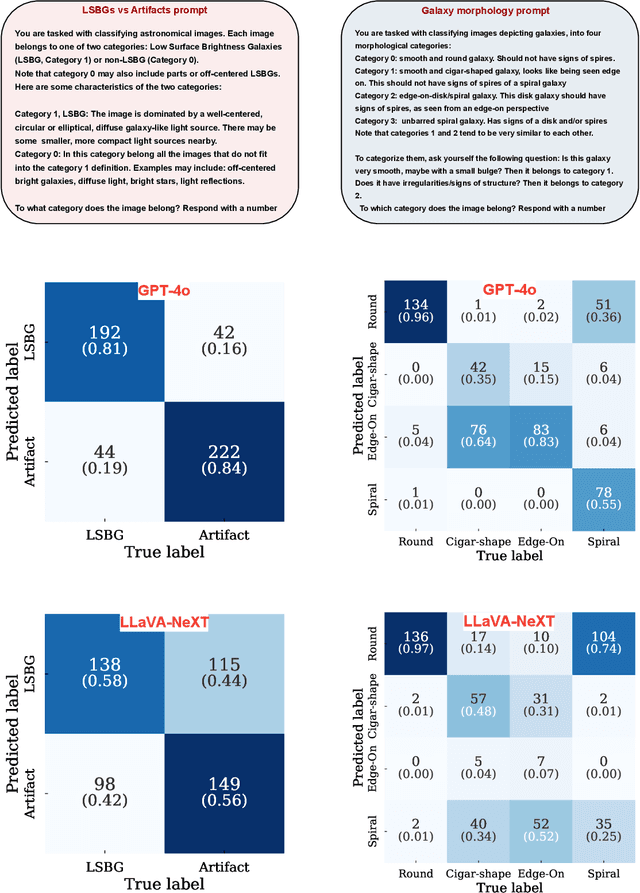


Vision-Language multimodal Models (VLMs) offer the possibility for zero-shot classification in astronomy: i.e. classification via natural language prompts, with no training. We investigate two models, GPT-4o and LLaVA-NeXT, for zero-shot classification of low-surface brightness galaxies and artifacts, as well as morphological classification of galaxies. We show that with natural language prompts these models achieved significant accuracy (above 80 percent typically) without additional training/fine tuning. We discuss areas that require improvement, especially for LLaVA-NeXT, which is an open source model. Our findings aim to motivate the astronomical community to consider VLMs as a powerful tool for both research and pedagogy, with the prospect that future custom-built or fine-tuned models could perform better.
Sum-of-Parts Models: Faithful Attributions for Groups of Features
Oct 25, 2023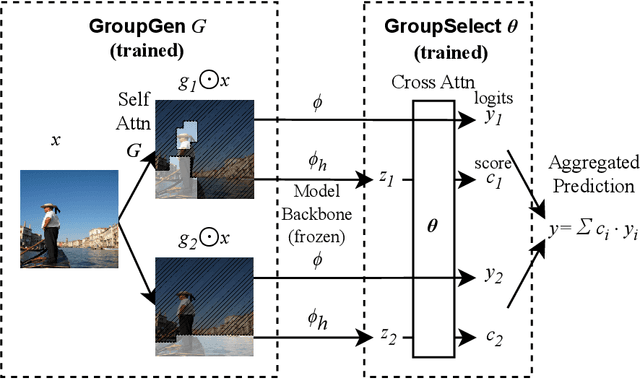
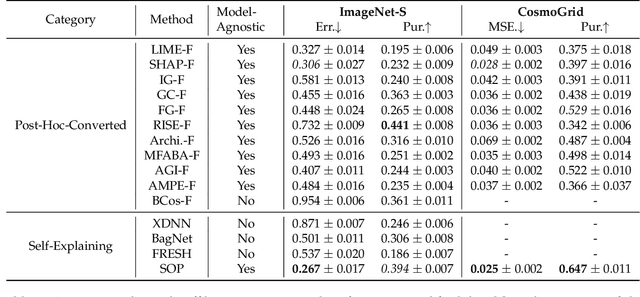

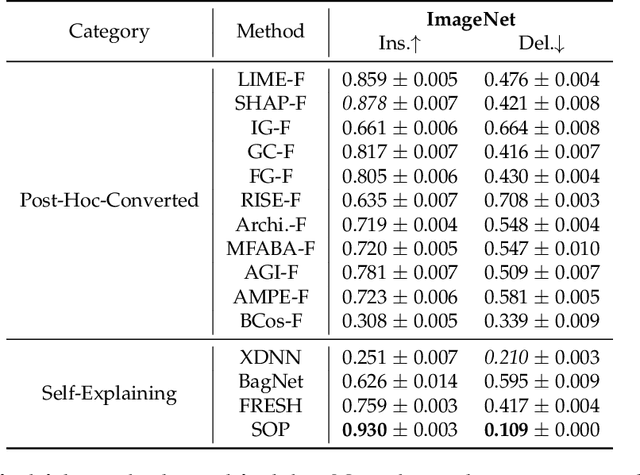
An explanation of a machine learning model is considered "faithful" if it accurately reflects the model's decision-making process. However, explanations such as feature attributions for deep learning are not guaranteed to be faithful, and can produce potentially misleading interpretations. In this work, we develop Sum-of-Parts (SOP), a class of models whose predictions come with grouped feature attributions that are faithful-by-construction. This model decomposes a prediction into an interpretable sum of scores, each of which is directly attributable to a sparse group of features. We evaluate SOP on benchmarks with standard interpretability metrics, and in a case study, we use the faithful explanations from SOP to help astrophysicists discover new knowledge about galaxy formation.
Transformers for scientific data: a pedagogical review for astronomers
Oct 19, 2023The deep learning architecture associated with ChatGPT and related generative AI products is known as transformers. Initially applied to Natural Language Processing, transformers and the self-attention mechanism they exploit have gained widespread interest across the natural sciences. The goal of this pedagogical and informal review is to introduce transformers to scientists. The review includes the mathematics underlying the attention mechanism, a description of the original transformer architecture, and a section on applications to time series and imaging data in astronomy. We include a Frequently Asked Questions section for readers who are curious about generative AI or interested in getting started with transformers for their research problem.