 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
Multimodal Datasets with Controllable Mutual Information
Oct 24, 2025We introduce a framework for generating highly multimodal datasets with explicitly calculable mutual information between modalities. This enables the construction of benchmark datasets that provide a novel testbed for systematic studies of mutual information estimators and multimodal self-supervised learning techniques. Our framework constructs realistic datasets with known mutual information using a flow-based generative model and a structured causal framework for generating correlated latent variables.
Impact of Pretraining Word Co-occurrence on Compositional Generalization in Multimodal Models
Jul 10, 2025CLIP and large multimodal models (LMMs) have better accuracy on examples involving concepts that are highly represented in the training data. However, the role of concept combinations in the training data on compositional generalization is largely unclear -- for instance, how does accuracy vary when a common object appears in an uncommon pairing with another object? In this paper, we investigate how word co-occurrence statistics in the pretraining dataset (a proxy for co-occurrence of visual concepts) impacts CLIP/LMM performance. To disentangle the effects of word co-occurrence frequencies from single-word frequencies, we measure co-occurrence with pointwise mutual information (PMI), which normalizes the joint probability of two words co-occurring by the probability of co-occurring independently. Using synthetically generated images with a variety of concept pairs, we show a strong correlation between PMI in the CLIP pretraining data and zero-shot accuracy in CLIP models trained on LAION-400M (r=0.97 and 14% accuracy gap between images in the top and bottom 5% of PMI values), demonstrating that even accuracy on common concepts is affected by the combination of concepts in the image. Leveraging this finding, we reproduce this effect in natural images by editing them to contain pairs with varying PMI, resulting in a correlation of r=0.75. Finally, we demonstrate that this behavior in CLIP transfers to LMMs built on top of CLIP (r=0.70 for TextVQA, r=0.62 for VQAv2). Our findings highlight the need for algorithms and architectures that improve compositional generalization in multimodal models without scaling the training data combinatorially. Our code is available at https://github.com/helenqu/multimodal-pretraining-pmi.
The FIX Benchmark: Extracting Features Interpretable to eXperts
Sep 20, 2024

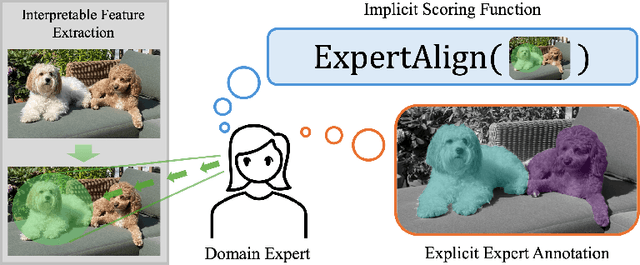
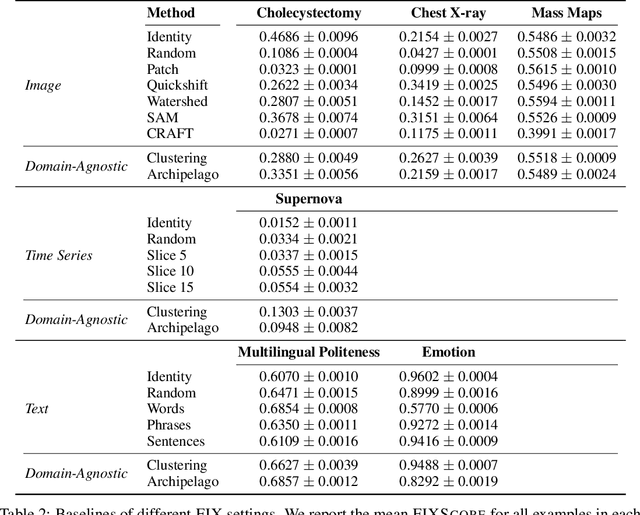
Feature-based methods are commonly used to explain model predictions, but these methods often implicitly assume that interpretable features are readily available. However, this is often not the case for high-dimensional data, and it can be hard even for domain experts to mathematically specify which features are important. Can we instead automatically extract collections or groups of features that are aligned with expert knowledge? To address this gap, we present FIX (Features Interpretable to eXperts), a benchmark for measuring how well a collection of features aligns with expert knowledge. In collaboration with domain experts, we have developed feature interpretability objectives across diverse real-world settings and unified them into a single framework that is the FIX benchmark. We find that popular feature-based explanation methods have poor alignment with expert-specified knowledge, highlighting the need for new methods that can better identify features interpretable to experts.
Sum-of-Parts Models: Faithful Attributions for Groups of Features
Oct 25, 2023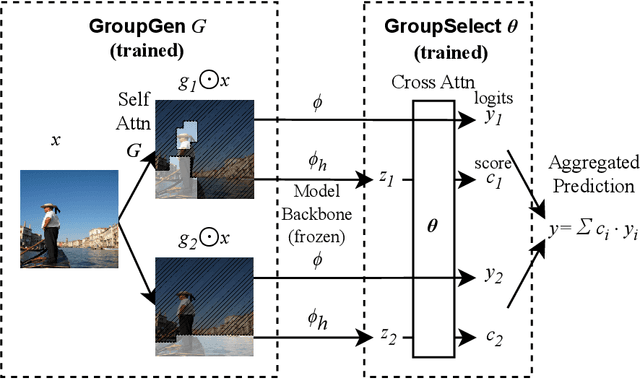
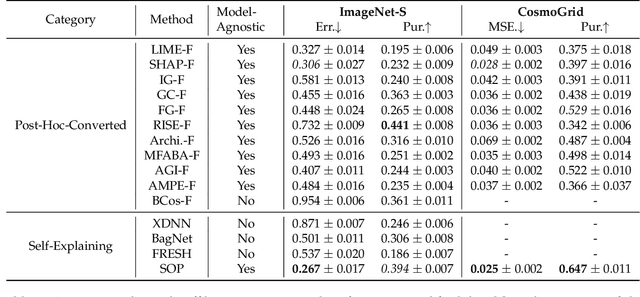

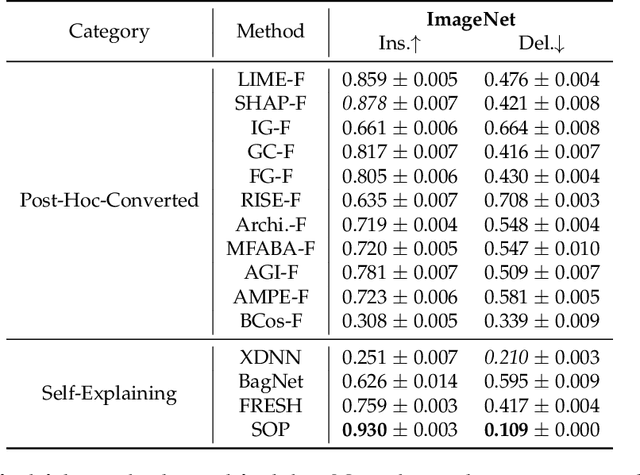
An explanation of a machine learning model is considered "faithful" if it accurately reflects the model's decision-making process. However, explanations such as feature attributions for deep learning are not guaranteed to be faithful, and can produce potentially misleading interpretations. In this work, we develop Sum-of-Parts (SOP), a class of models whose predictions come with grouped feature attributions that are faithful-by-construction. This model decomposes a prediction into an interpretable sum of scores, each of which is directly attributable to a sparse group of features. We evaluate SOP on benchmarks with standard interpretability metrics, and in a case study, we use the faithful explanations from SOP to help astrophysicists discover new knowledge about galaxy formation.
Transformers for scientific data: a pedagogical review for astronomers
Oct 19, 2023The deep learning architecture associated with ChatGPT and related generative AI products is known as transformers. Initially applied to Natural Language Processing, transformers and the self-attention mechanism they exploit have gained widespread interest across the natural sciences. The goal of this pedagogical and informal review is to introduce transformers to scientists. The review includes the mathematics underlying the attention mechanism, a description of the original transformer architecture, and a section on applications to time series and imaging data in astronomy. We include a Frequently Asked Questions section for readers who are curious about generative AI or interested in getting started with transformers for their research problem.
Photo-zSNthesis: Converting Type Ia Supernova Lightcurves to Redshift Estimates via Deep Learning
May 19, 2023Upcoming photometric surveys will discover tens of thousands of Type Ia supernovae (SNe Ia), vastly outpacing the capacity of our spectroscopic resources. In order to maximize the science return of these observations in the absence of spectroscopic information, we must accurately extract key parameters, such as SN redshifts, with photometric information alone. We present Photo-zSNthesis, a convolutional neural network-based method for predicting full redshift probability distributions from multi-band supernova lightcurves, tested on both simulated Sloan Digital Sky Survey (SDSS) and Vera C. Rubin Legacy Survey of Space and Time (LSST) data as well as observed SDSS SNe. We show major improvements over predictions from existing methods on both simulations and real observations as well as minimal redshift-dependent bias, which is a challenge due to selection effects, e.g. Malmquist bias. The PDFs produced by this method are well-constrained and will maximize the cosmological constraining power of photometric SNe Ia samples.
A Convolutional Neural Network Approach to Supernova Time-Series Classification
Jul 19, 2022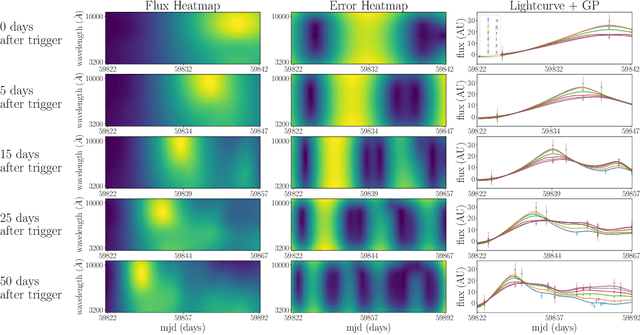
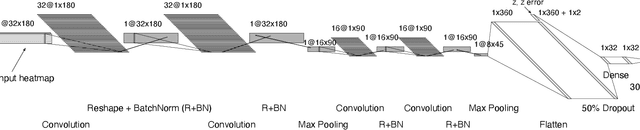
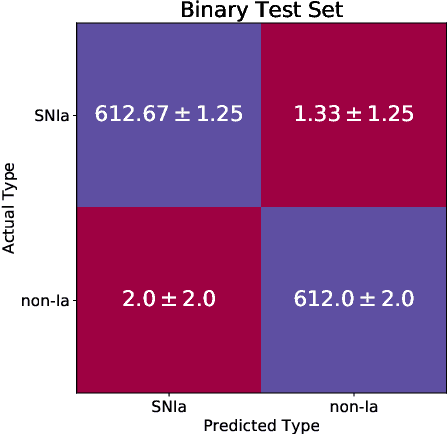

One of the brightest objects in the universe, supernovae (SNe) are powerful explosions marking the end of a star's lifetime. Supernova (SN) type is defined by spectroscopic emission lines, but obtaining spectroscopy is often logistically unfeasible. Thus, the ability to identify SNe by type using time-series image data alone is crucial, especially in light of the increasing breadth and depth of upcoming telescopes. We present a convolutional neural network method for fast supernova time-series classification, with observed brightness data smoothed in both the wavelength and time directions with Gaussian process regression. We apply this method to full duration and truncated SN time-series, to simulate retrospective as well as real-time classification performance. Retrospective classification is used to differentiate cosmologically useful Type Ia SNe from other SN types, and this method achieves >99% accuracy on this task. We are also able to differentiate between 6 SN types with 60% accuracy given only two nights of data and 98% accuracy retrospectively.
There's no difference: Convolutional Neural Networks for transient detection without template subtraction
Mar 14, 2022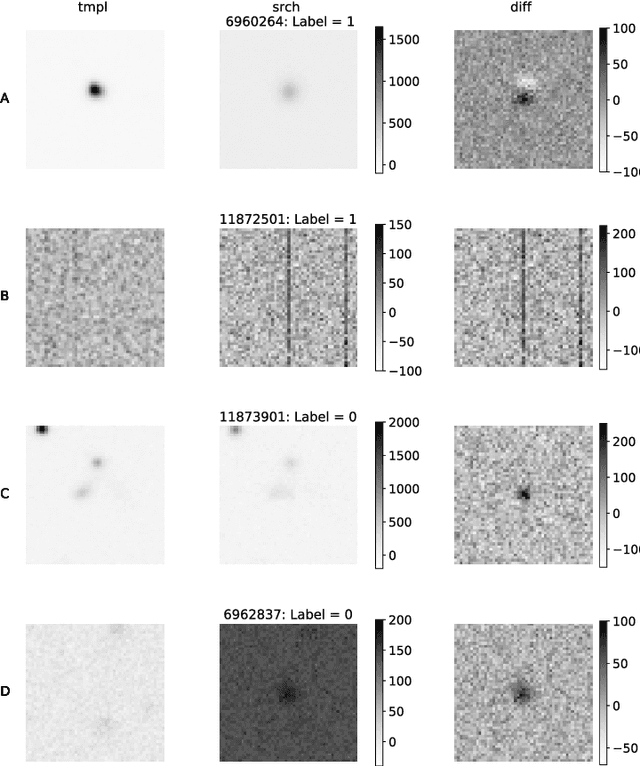
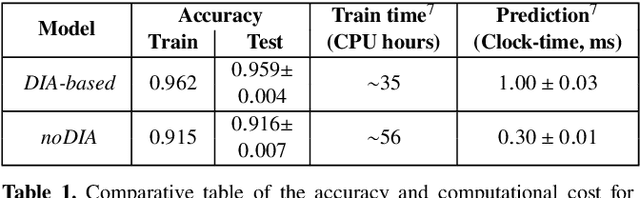
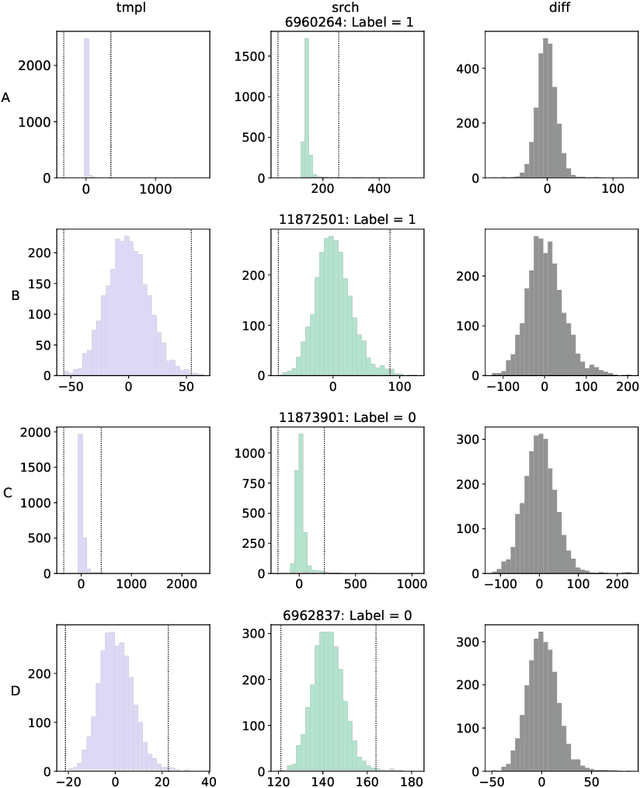

We present a Convolutional Neural Network (CNN) model for the separation of astrophysical transients from image artifacts, a task known as "real-bogus" classification, that does not rely on Difference Image Analysis (DIA) which is a computationally expensive process involving image matching on small spatial scales in large volumes of data. We explore the use of CNNs to (1) automate the "real-bogus" classification, (2) reduce the computational costs of transient discovery. We compare the efficiency of two CNNs with similar architectures, one that uses "image triplets" (templates, search, and the corresponding difference image) and one that adopts a similar architecture but takes as input the template and search only. Without substantially changing the model architecture or retuning the hyperparameters to the new input, we observe only a small decrease in model efficiency (97% to 92% accuracy). We further investigate how the model that does not receive the difference image learns the required information from the template and search by exploring the saliency maps. Our work demonstrates that (1) CNNs are excellent models for "real-bogus" classification that rely exclusively on the imaging data and require no feature engineering task; (2) high-accuracy models can be built without the need to construct difference images. Since once trained, neural networks can generate predictions at minimal computational costs, we argue that future implementations of this methodology could dramatically reduce the computational costs in the detection of genuine transients in synoptic surveys like Rubin Observatory's Legacy Survey of Space and Time by bypassing the DIA step entirely.