 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSF-SciFy: Mining the NSF Awards Database for Scientific Claims
Mar 11, 2025



We present NSF-SciFy, a large-scale dataset for scientific claim extraction derived from the National Science Foundation (NSF) awards database, comprising over 400K grant abstracts spanning five decades. While previous datasets relied on published literature, we leverage grant abstracts which offer a unique advantage: they capture claims at an earlier stage in the research lifecycle before publication takes effect. We also introduce a new task to distinguish between existing scientific claims and aspirational research intentions in proposals.Using zero-shot prompting with frontier large language models, we jointly extract 114K scientific claims and 145K investigation proposals from 16K grant abstracts in the materials science domain to create a focused subset called NSF-SciFy-MatSci. We use this dataset to evaluate 3 three key tasks: (1) technical to non-technical abstract generation, where models achieve high BERTScore (0.85+ F1); (2) scientific claim extraction, where fine-tuned models outperform base models by 100% relative improvement; and (3) investigation proposal extraction, showing 90%+ improvement with fine-tuning. We introduce novel LLM-based evaluation metrics for robust assessment of claim/proposal extraction quality. As the largest scientific claim dataset to date -- with an estimated 2.8 million claims across all STEM disciplines funded by the NSF -- NSF-SciFy enables new opportunities for claim verification and meta-scientific research. We publicly release all datasets, trained models, and evaluation code to facilitate further research.
WithdrarXiv: A Large-Scale Dataset for Retraction Study
Dec 04, 2024



Retractions play a vital role in maintaining scientific integrity, yet systematic studies of retractions in computer science and other STEM fields remain scarce. We present WithdrarXiv, the first large-scale dataset of withdrawn papers from arXiv, containing over 14,000 papers and their associated retraction comments spanning the repository's entire history through September 2024. Through careful analysis of author comments, we develop a comprehensive taxonomy of retraction reasons, identifying 10 distinct categories ranging from critical errors to policy violations. We demonstrate a simple yet highly accurate zero-shot automatic categorization of retraction reasons, achieving a weighted average F1-score of 0.96. Additionally, we release WithdrarXiv-SciFy, an enriched version including scripts for parsed full-text PDFs, specifically designed to enable research in scientific feasibility studies, claim verification, and automated theorem proving. These findings provide valuable insights for improving scientific quality control and automated verification systems. Finally, and most importantly, we discuss ethical issues and take a number of steps to implement responsible data release while fostering open science in this area.
Learning Interpretable Style Embeddings via Prompting LLMs
May 22, 2023

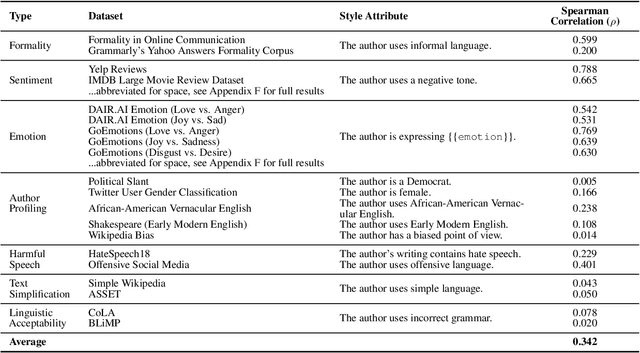
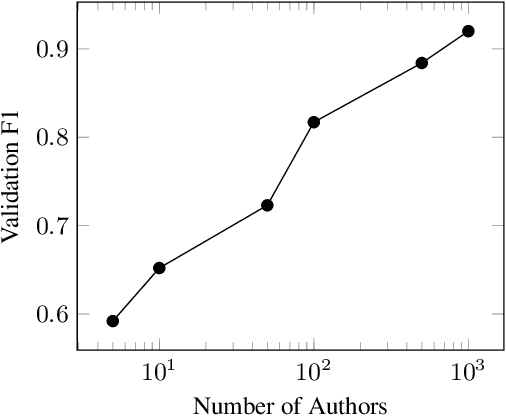
Style representation learning builds content-independent representations of author style in text. Stylometry, the analysis of style in text, is often performed by expert forensic linguists and no large dataset of stylometric annotations exists for training. Current style representation learning uses neural methods to disentangle style from content to create style vectors, however, these approaches result in uninterpretable representations, complicating their usage in downstream applications like authorship attribution where auditing and explainability is critical. In this work, we use prompting to perform stylometry on a large number of texts to create a synthetic dataset and train human-interpretable style representations we call LISA embeddings. We release our synthetic stylometry dataset and our interpretable style models as resources.
Faithful Chain-of-Thought Reasoning
Feb 01, 2023



While Chain-of-Thought (CoT) prompting boosts Language Models' (LM) performance on a gamut of complex reasoning tasks, the generated reasoning chain does not necessarily reflect how the model arrives at the answer (aka. faithfulness). We propose Faithful CoT, a faithful-by-construction framework that decomposes a reasoning task into two stages: Translation (Natural Language query $\rightarrow$ symbolic reasoning chain) and Problem Solving (reasoning chain $\rightarrow$ answer), using an LM and a deterministic solver respectively. We demonstrate the efficacy of our approach on 10 reasoning datasets from 4 diverse domains. It outperforms traditional CoT prompting on 9 out of the 10 datasets, with an average accuracy gain of 4.4 on Math Word Problems, 1.9 on Planning, 4.0 on Multi-hop Question Answering (QA), and 18.1 on Logical Inference, under greedy decoding. Together with self-consistency decoding, we achieve new state-of-the-art few-shot performance on 7 out of the 10 datasets, showing a strong synergy between faithfulness and accuracy.
Listening to the World Improves Speech Command Recognition
Oct 23, 2017
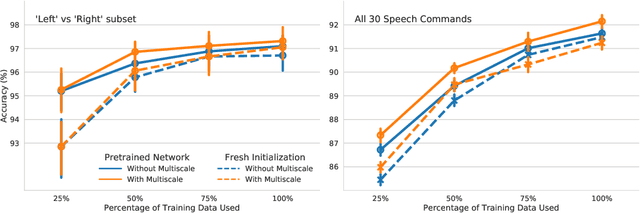
We study transfer learning in convolutional network architectures applied to the task of recognizing audio, such as environmental sound events and speech commands. Our key finding is that not only is it possible to transfer representations from an unrelated task like environmental sound classification to a voice-focused task like speech command recognition, but also that doing so improves accuracies significantly. We also investigate the effect of increased model capacity for transfer learning audio, by first validating known results from the field of Computer Vision of achieving better accuracies with increasingly deeper networks on two audio datasets: UrbanSound8k and the newly released Google Speech Commands dataset. Then we propose a simple multiscale input representation using dilated convolutions and show that it is able to aggregate larger contexts and increase classification performance. Further, the models trained using a combination of transfer learning and multiscale input representations need only 40% of the training data to achieve similar accuracies as a freshly trained model with 100% of the training data. Finally, we demonstrate a positive interaction effect for the multiscale input and transfer learning, making a case for the joint application of the two techniques.