 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWithdrarXiv: A Large-Scale Dataset for Retraction Study
Dec 04, 2024



Retractions play a vital role in maintaining scientific integrity, yet systematic studies of retractions in computer science and other STEM fields remain scarce. We present WithdrarXiv, the first large-scale dataset of withdrawn papers from arXiv, containing over 14,000 papers and their associated retraction comments spanning the repository's entire history through September 2024. Through careful analysis of author comments, we develop a comprehensive taxonomy of retraction reasons, identifying 10 distinct categories ranging from critical errors to policy violations. We demonstrate a simple yet highly accurate zero-shot automatic categorization of retraction reasons, achieving a weighted average F1-score of 0.96. Additionally, we release WithdrarXiv-SciFy, an enriched version including scripts for parsed full-text PDFs, specifically designed to enable research in scientific feasibility studies, claim verification, and automated theorem proving. These findings provide valuable insights for improving scientific quality control and automated verification systems. Finally, and most importantly, we discuss ethical issues and take a number of steps to implement responsible data release while fostering open science in this area.
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Mar 28, 2019
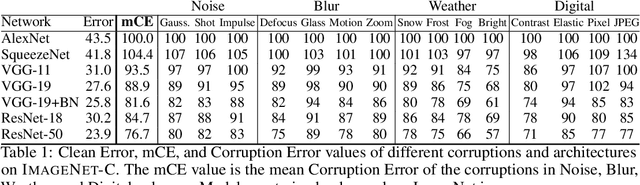

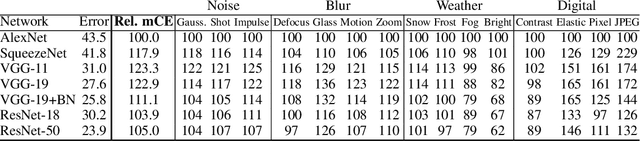
In this paper we establish rigorous benchmarks for image classifier robustness. Our first benchmark, ImageNet-C, standardizes and expands the corruption robustness topic, while showing which classifiers are preferable in safety-critical applications. Then we propose a new dataset called ImageNet-P which enables researchers to benchmark a classifier's robustness to common perturbations. Unlike recent robustness research, this benchmark evaluates performance on common corruptions and perturbations not worst-case adversarial perturbations. We find that there are negligible changes in relative corruption robustness from AlexNet classifiers to ResNet classifiers. Afterward we discover ways to enhance corruption and perturbation robustness. We even find that a bypassed adversarial defense provides substantial common perturbation robustness. Together our benchmarks may aid future work toward networks that robustly generalize.
A Meta-Analysis of the Anomaly Detection Problem
Aug 26, 2016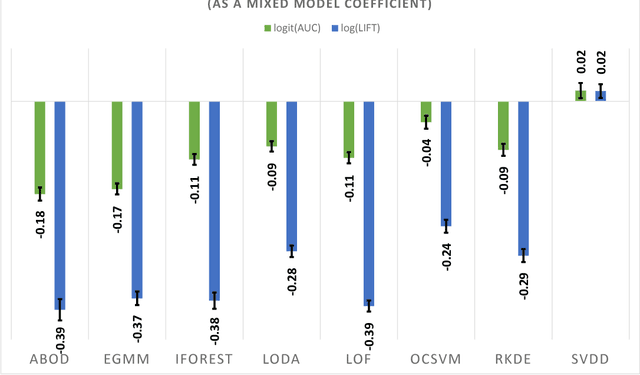
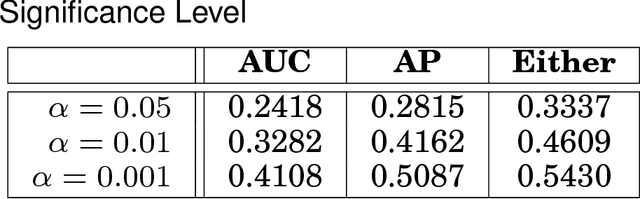
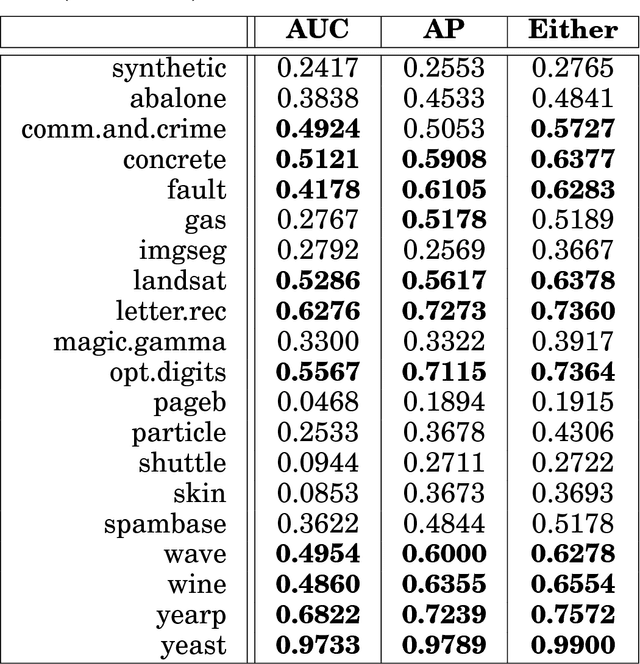
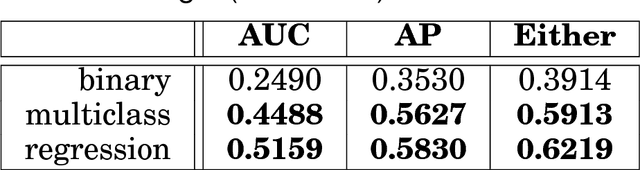
This article provides a thorough meta-analysis of the anomaly detection problem. To accomplish this we first identify approaches to benchmarking anomaly detection algorithms across the literature and produce a large corpus of anomaly detection benchmarks that vary in their construction across several dimensions we deem important to real-world applications: (a) point difficulty, (b) relative frequency of anomalies, (c) clusteredness of anomalies, and (d) relevance of features. We apply a representative set of anomaly detection algorithms to this corpus, yielding a very large collection of experimental results. We analyze these results to understand many phenomena observed in previous work. First we observe the effects of experimental design on experimental results. Second, results are evaluated with two metrics, ROC Area Under the Curve and Average Precision. We employ statistical hypothesis testing to demonstrate the value (or lack thereof) of our benchmarks. We then offer several approaches to summarizing our experimental results, drawing several conclusions about the impact of our methodology as well as the strengths and weaknesses of some algorithms. Last, we compare results against a trivial solution as an alternate means of normalizing the reported performance of algorithms. The intended contributions of this article are many; in addition to providing a large publicly-available corpus of anomaly detection benchmarks, we provide an ontology for describing anomaly detection contexts, a methodology for controlling various aspects of benchmark creation, guidelines for future experimental design and a discussion of the many potential pitfalls of trying to measure success in this field.