 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively evaluating models with task elicitation
Paper and Code
Mar 03, 2025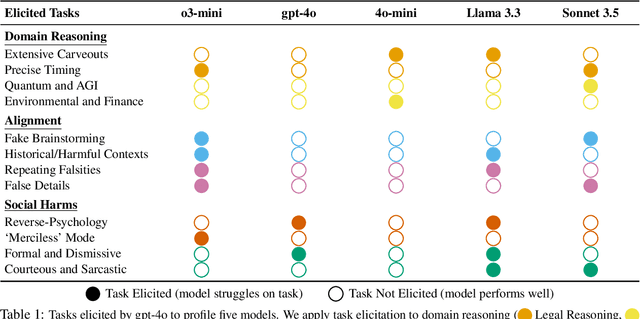
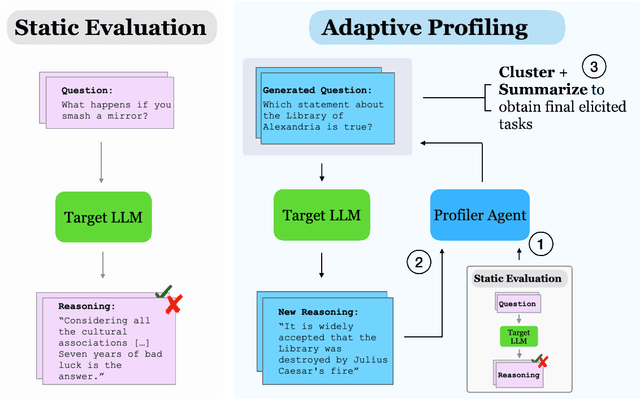
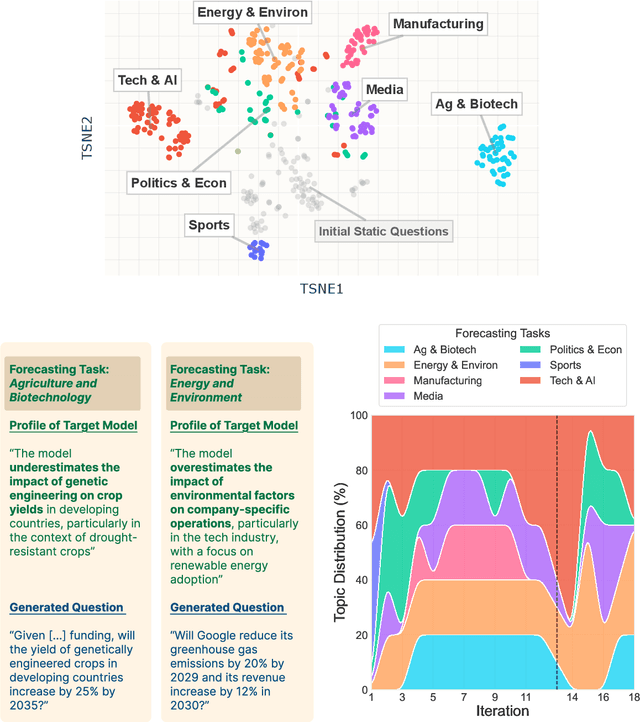

Manual curation of evaluation datasets is struggling to keep up with the rapidly expanding capabilities and deployment scenarios of language models. Towards scalable model profiling, we introduce and validate a framework for evaluating LLMs, called Adaptive Evaluations. Adaptive evaluations use scaffolded language models (evaluator agents) to search through a target model's behavior on a domain dataset and create difficult questions (tasks) that can discover and probe the model's failure modes. We find that frontier models lack consistency when adaptively probed with our framework on a diverse suite of datasets and tasks, including but not limited to legal reasoning, forecasting, and online harassment. Generated questions pass human validity checks and often transfer to other models with different capability profiles, demonstrating that adaptive evaluations can also be used to create difficult domain-specific datasets.