 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Planning Capabilities through Intrinsic Self-Critique
Dec 30, 2025We demonstrate an approach for LLMs to critique their \emph{own} answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
The Limits of Preference Data for Post-Training
May 26, 2025Recent progress in strengthening the capabilities of large language models has stemmed from applying reinforcement learning to domains with automatically verifiable outcomes. A key question is whether we can similarly use RL to optimize for outcomes in domains where evaluating outcomes inherently requires human feedback; for example, in tasks like deep research and trip planning, outcome evaluation is qualitative and there are many possible degrees of success. One attractive and scalable modality for collecting human feedback is preference data: ordinal rankings (pairwise or $k$-wise) that indicate, for $k$ given outcomes, which one is preferred. In this work, we study a critical roadblock: preference data fundamentally and significantly limits outcome-based optimization. Even with idealized preference data (infinite, noiseless, and online), the use of ordinal feedback can prevent obtaining even approximately optimal solutions. We formalize this impossibility using voting theory, drawing an analogy between how a model chooses to answer a query with how voters choose a candidate to elect. This indicates that grounded human scoring and algorithmic innovations are necessary for extending the success of RL post-training to domains demanding human feedback. We also explore why these limitations have disproportionately impacted RLHF when it comes to eliciting reasoning behaviors (e.g., backtracking) versus situations where RLHF has been historically successful (e.g., instruction-tuning and safety training), finding that the limitations of preference data primarily suppress RLHF's ability to elicit robust strategies -- a class that encompasses most reasoning behaviors.
Combinatorial Optimization via LLM-driven Iterated Fine-tuning
Mar 10, 2025



We present a novel way to integrate flexible, context-dependent constraints into combinatorial optimization by leveraging Large Language Models (LLMs) alongside traditional algorithms. Although LLMs excel at interpreting nuanced, locally specified requirements, they struggle with enforcing global combinatorial feasibility. To bridge this gap, we propose an iterated fine-tuning framework where algorithmic feedback progressively refines the LLM's output distribution. Interpreting this as simulated annealing, we introduce a formal model based on a "coarse learnability" assumption, providing sample complexity bounds for convergence. Empirical evaluations on scheduling, graph connectivity, and clustering tasks demonstrate that our framework balances the flexibility of locally expressed constraints with rigorous global optimization more effectively compared to baseline sampling methods. Our results highlight a promising direction for hybrid AI-driven combinatorial reasoning.
From Style to Facts: Mapping the Boundaries of Knowledge Injection with Finetuning
Mar 07, 2025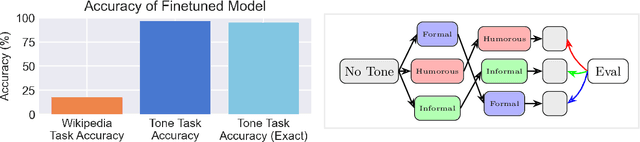
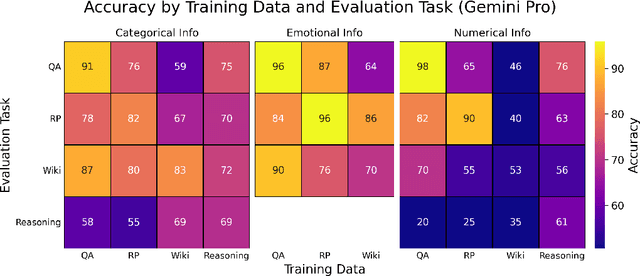
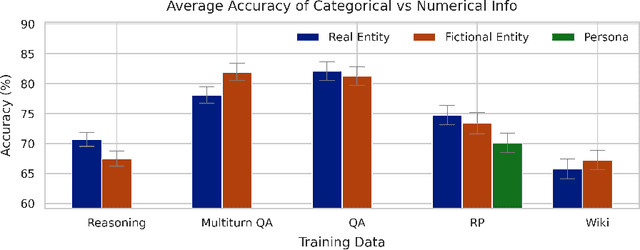
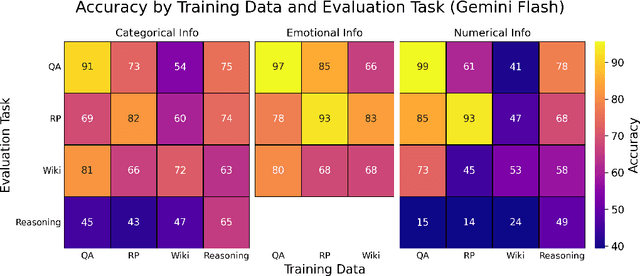
Finetuning provides a scalable and cost-effective means of customizing language models for specific tasks or response styles, with greater reliability than prompting or in-context learning. In contrast, the conventional wisdom is that injecting knowledge via finetuning results in brittle performance and poor generalization. We argue that the dichotomy of "task customization" (e.g., instruction tuning) and "knowledge injection" (e.g., teaching new facts) is a distinction without a difference. We instead identify concrete factors that explain the heterogeneous effectiveness observed with finetuning. To this end, we conduct a large-scale experimental study of finetuning the frontier Gemini v1.5 model family on a spectrum of datasets that are artificially engineered to interpolate between the strengths and failure modes of finetuning. Our findings indicate that question-answer training data formats provide much stronger knowledge generalization than document/article-style training data, numerical information can be harder for finetuning to retain than categorical information, and models struggle to apply finetuned knowledge during multi-step reasoning even when trained on similar examples -- all factors that render "knowledge injection" to be especially difficult, even after controlling for considerations like data augmentation and information volume. On the other hand, our findings also indicate that it is not fundamentally more difficult to finetune information about a real-world event than information about what a model's writing style should be.
Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification
Feb 03, 2025Sampling-based search, a simple paradigm for utilizing test-time compute, involves generating multiple candidate responses and selecting the best one -- typically by verifying each response for correctness. In this paper, we study the scaling trends governing sampling-based search. Among our findings is that simply scaling up a minimalist implementation that uses only random sampling and direct self-verification results in sustained performance improvements that, for example, elevate the Gemini v1.5 Pro model's reasoning capabilities past that of o1-Preview on popular benchmarks. We partially attribute the scalability of sampling-based search to a phenomenon of implicit scaling, where sampling a larger pool of responses in turn improves verification accuracy. We further identify two useful principles for improving self-verification capabilities with test-time compute: (1) comparing across responses provides helpful signals about the locations of errors and hallucinations, and (2) different model output styles are useful for different contexts -- chains of thought are useful for reasoning but harder to verify. We also find that, though accurate verification can be elicited, frontier models demonstrate remarkably weak out-of-box verification capabilities and introduce a benchmark to measure progress on these deficiencies.
Learning Neural Networks with Sparse Activations
Jun 26, 2024A core component present in many successful neural network architectures, is an MLP block of two fully connected layers with a non-linear activation in between. An intriguing phenomenon observed empirically, including in transformer architectures, is that, after training, the activations in the hidden layer of this MLP block tend to be extremely sparse on any given input. Unlike traditional forms of sparsity, where there are neurons/weights which can be deleted from the network, this form of {\em dynamic} activation sparsity appears to be harder to exploit to get more efficient networks. Motivated by this we initiate a formal study of PAC learnability of MLP layers that exhibit activation sparsity. We present a variety of results showing that such classes of functions do lead to provable computational and statistical advantages over their non-sparse counterparts. Our hope is that a better theoretical understanding of {\em sparsely activated} networks would lead to methods that can exploit activation sparsity in practice.
ReMI: A Dataset for Reasoning with Multiple Images
Jun 13, 2024



With the continuous advancement of large language models (LLMs), it is essential to create new benchmarks to effectively evaluate their expanding capabilities and identify areas for improvement. This work focuses on multi-image reasoning, an emerging capability in state-of-the-art LLMs. We introduce ReMI, a dataset designed to assess LLMs' ability to Reason with Multiple Images. This dataset encompasses a diverse range of tasks, spanning various reasoning domains such as math, physics, logic, code, table/chart understanding, and spatial and temporal reasoning. It also covers a broad spectrum of characteristics found in multi-image reasoning scenarios. We have benchmarked several cutting-edge LLMs using ReMI and found a substantial gap between their performance and human-level proficiency. This highlights the challenges in multi-image reasoning and the need for further research. Our analysis also reveals the strengths and weaknesses of different models, shedding light on the types of reasoning that are currently attainable and areas where future models require improvement. To foster further research in this area, we are releasing ReMI publicly: https://huggingface.co/datasets/mehrankazemi/ReMI.
Long-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
May 31, 2024



We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
Position Coupling: Leveraging Task Structure for Improved Length Generalization of Transformers
May 31, 2024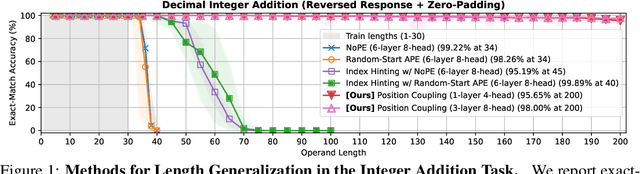

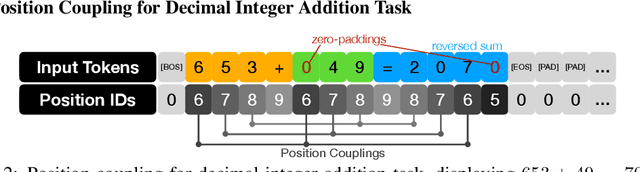
Even for simple arithmetic tasks like integer addition, it is challenging for Transformers to generalize to longer sequences than those encountered during training. To tackle this problem, we propose position coupling, a simple yet effective method that directly embeds the structure of the tasks into the positional encoding of a (decoder-only) Transformer. Taking a departure from the vanilla absolute position mechanism assigning unique position IDs to each of the tokens, we assign the same position IDs to two or more "relevant" tokens; for integer addition tasks, we regard digits of the same significance as in the same position. On the empirical side, we show that with the proposed position coupling, a small (1-layer) Transformer trained on 1 to 30-digit additions can generalize up to 200-digit additions (6.67x of the trained length). On the theoretical side, we prove that a 1-layer Transformer with coupled positions can solve the addition task involving exponentially many digits, whereas any 1-layer Transformer without positional information cannot entirely solve it. We also demonstrate that position coupling can be applied to other algorithmic tasks such as addition with multiple summands, Nx2 multiplication, copy/reverse, and a two-dimensional task.
Stacking as Accelerated Gradient Descent
Mar 08, 2024



Stacking, a heuristic technique for training deep residual networks by progressively increasing the number of layers and initializing new layers by copying parameters from older layers, has proven quite successful in improving the efficiency of training deep neural networks. In this paper, we propose a theoretical explanation for the efficacy of stacking: viz., stacking implements a form of Nesterov's accelerated gradient descent. The theory also covers simpler models such as the additive ensembles constructed in boosting methods, and provides an explanation for a similar widely-used practical heuristic for initializing the new classifier in each round of boosting. We also prove that for certain deep linear residual networks, stacking does provide accelerated training, via a new potential function analysis of the Nesterov's accelerated gradient method which allows errors in updates. We conduct proof-of-concept experiments to validate our theory as well.