 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
May 31, 2024



We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking
Jun 01, 2016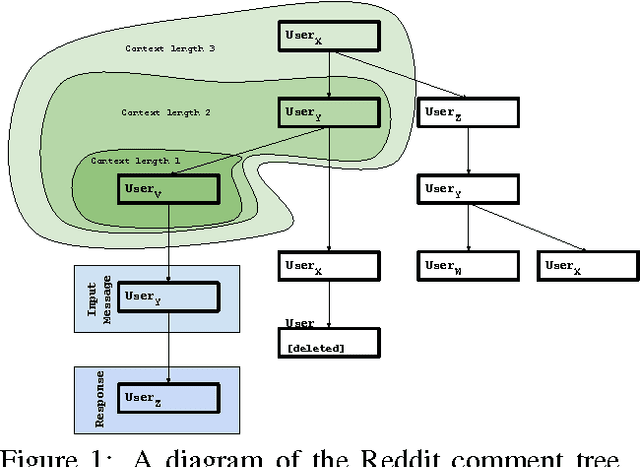
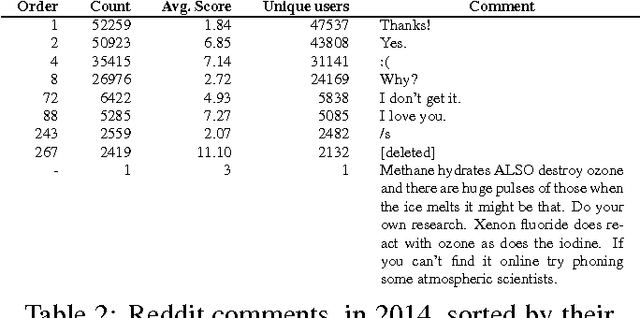
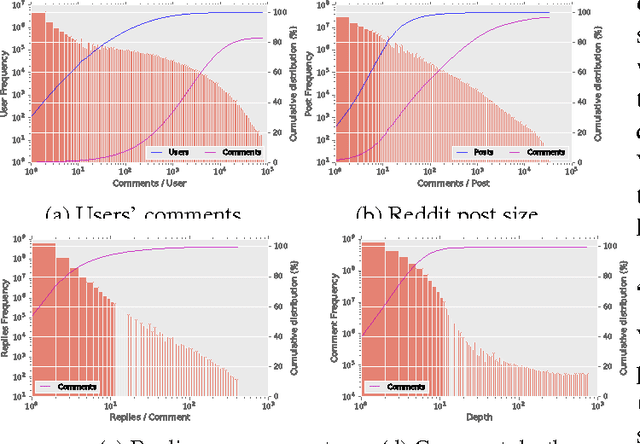
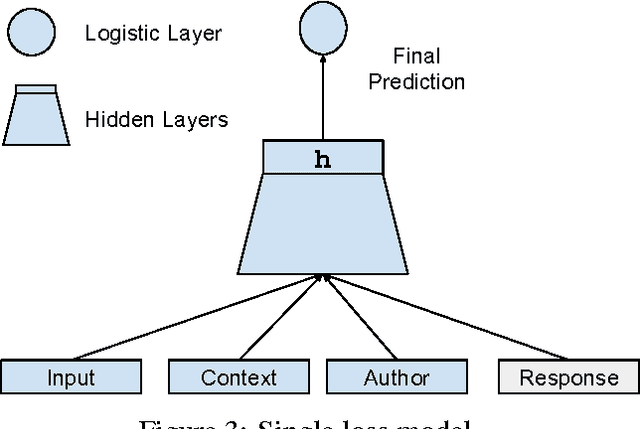
We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.