 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming LLMs into Cross-modal and Cross-lingual Retrieval Systems
Apr 04, 2024Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Knowledge Prompts: Injecting World Knowledge into Language Models through Soft Prompts
Oct 10, 2022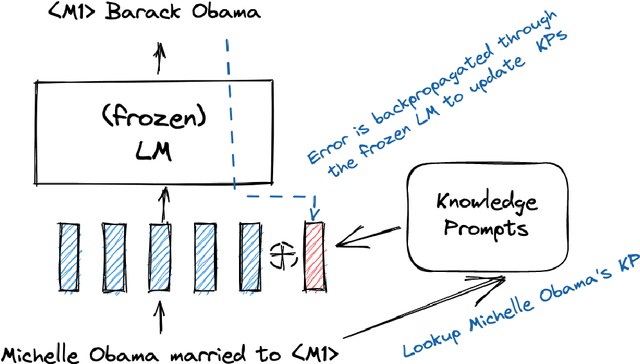


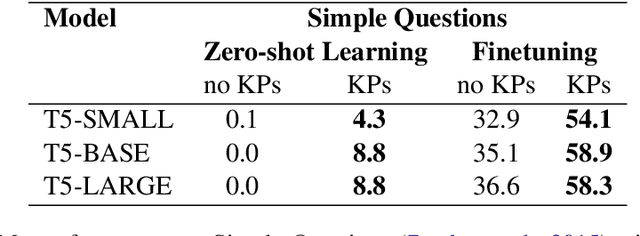
Soft prompts have been recently proposed as a tool for adapting large frozen language models (LMs) to new tasks. In this work, we repurpose soft prompts to the task of injecting world knowledge into LMs. We introduce a method to train soft prompts via self-supervised learning on data from knowledge bases. The resulting soft knowledge prompts (KPs) are task independent and work as an external memory of the LMs. We perform qualitative and quantitative experiments and demonstrate that: (1) KPs can effectively model the structure of the training data; (2) KPs can be used to improve the performance of LMs in different knowledge intensive tasks.
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax
Feb 22, 2019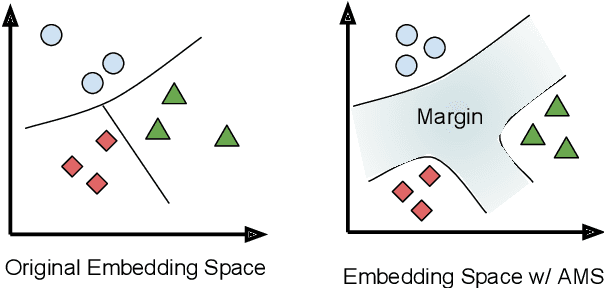

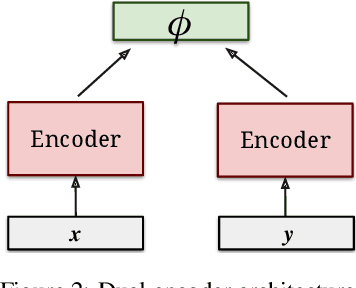

In this paper, we present an approach to learn multilingual sentence embeddings using a bi-directional dual-encoder with additive margin softmax. The embeddings are able to achieve state-of-the-art results on the United Nations (UN) parallel corpus retrieval task. In all the languages tested, the system achieves P@1 of 86% or higher. We use pairs retrieved by our approach to train NMT models that achieve similar performance to models trained on gold pairs. We explore simple document-level embeddings constructed by averaging our sentence embeddings. On the UN document-level retrieval task, document embeddings achieve around 97% on P@1 for all experimented language pairs. Lastly, we evaluate the proposed model on the BUCC mining task. The learned embeddings with raw cosine similarity scores achieve competitive results compared to current state-of-the-art models, and with a second-stage scorer we achieve a new state-of-the-art level on this task.
Efficient Natural Language Response Suggestion for Smart Reply
May 01, 2017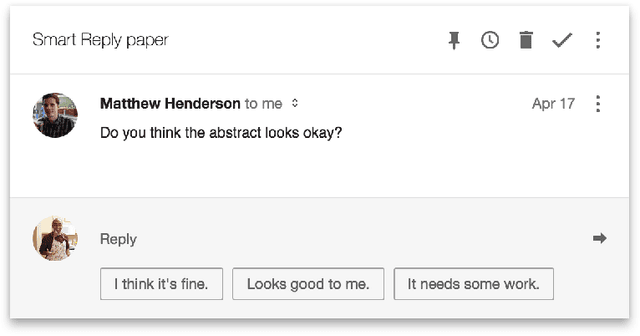

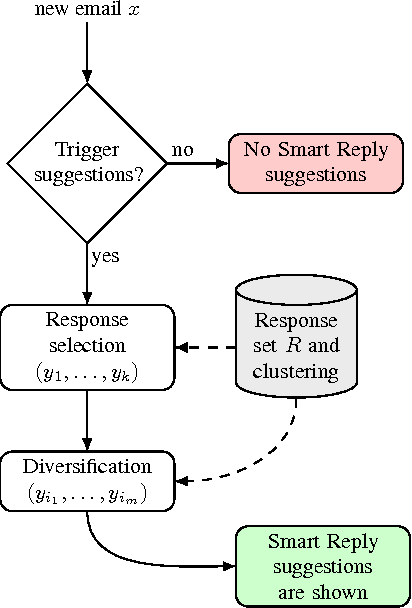
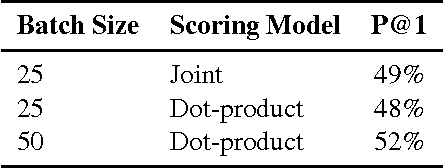
This paper presents a computationally efficient machine-learned method for natural language response suggestion. Feed-forward neural networks using n-gram embedding features encode messages into vectors which are optimized to give message-response pairs a high dot-product value. An optimized search finds response suggestions. The method is evaluated in a large-scale commercial e-mail application, Inbox by Gmail. Compared to a sequence-to-sequence approach, the new system achieves the same quality at a small fraction of the computational requirements and latency.
Conversational Contextual Cues: The Case of Personalization and History for Response Ranking
Jun 01, 2016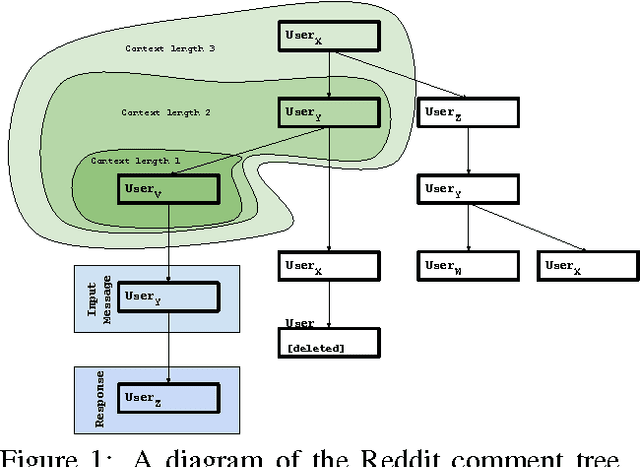
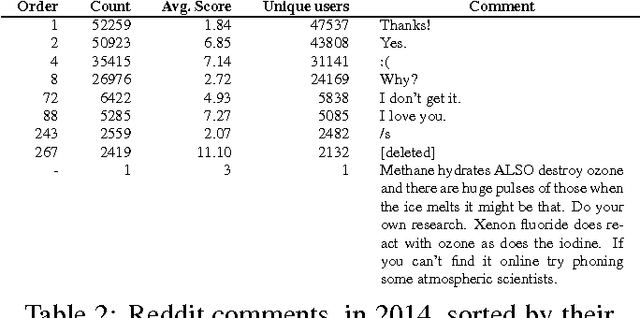
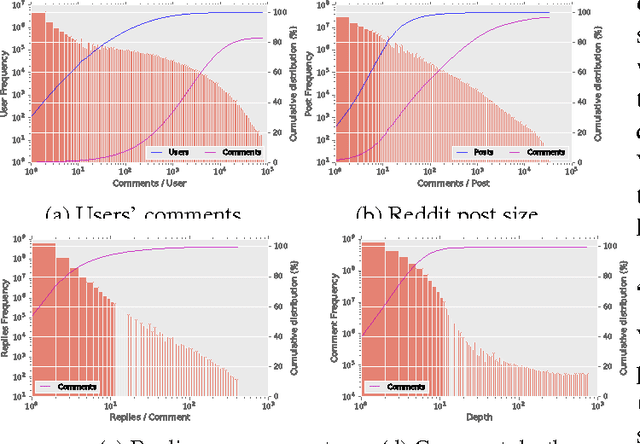
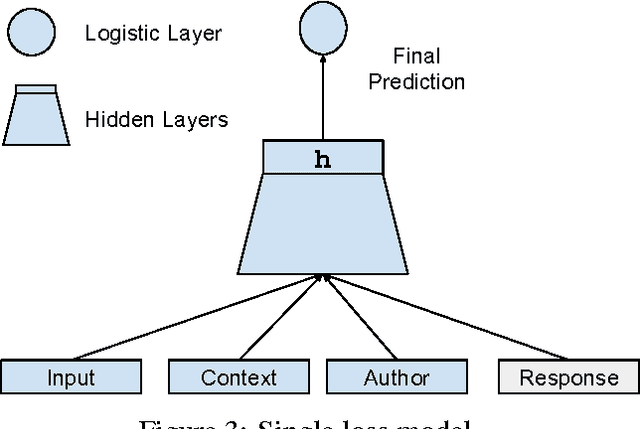
We investigate the task of modeling open-domain, multi-turn, unstructured, multi-participant, conversational dialogue. We specifically study the effect of incorporating different elements of the conversation. Unlike previous efforts, which focused on modeling messages and responses, we extend the modeling to long context and participant's history. Our system does not rely on handwritten rules or engineered features; instead, we train deep neural networks on a large conversational dataset. In particular, we exploit the structure of Reddit comments and posts to extract 2.1 billion messages and 133 million conversations. We evaluate our models on the task of predicting the next response in a conversation, and we find that modeling both context and participants improves prediction accuracy.