 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020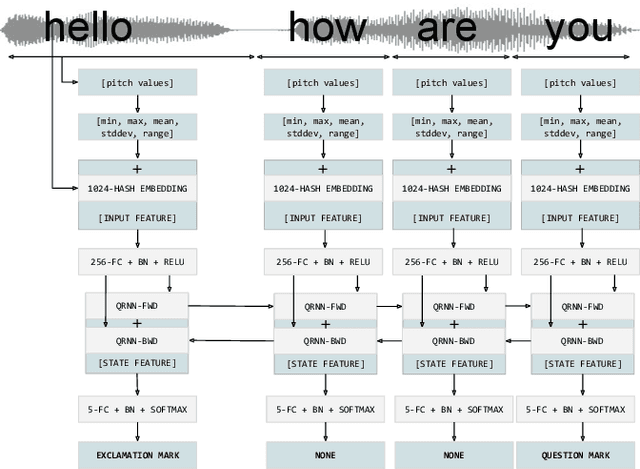

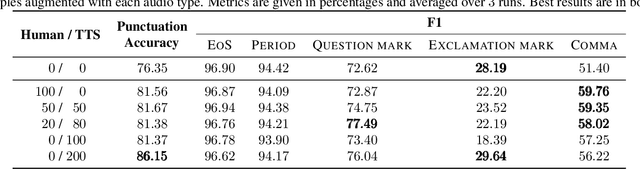

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.
Efficient Natural Language Response Suggestion for Smart Reply
May 01, 2017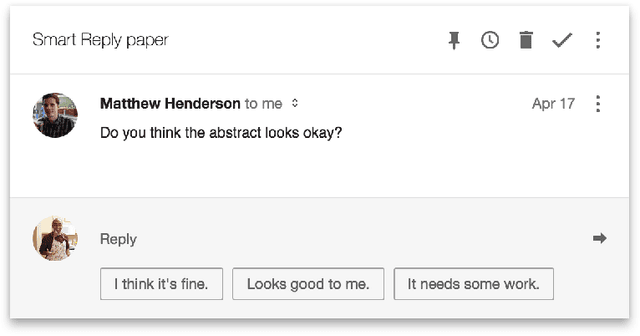

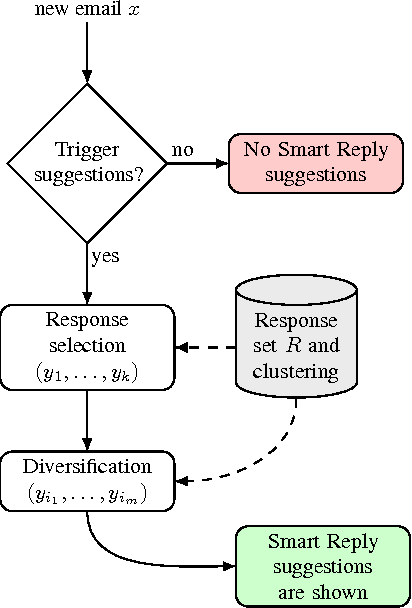
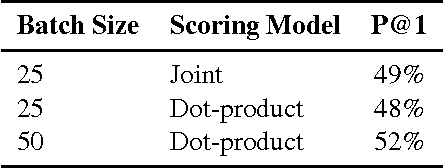
This paper presents a computationally efficient machine-learned method for natural language response suggestion. Feed-forward neural networks using n-gram embedding features encode messages into vectors which are optimized to give message-response pairs a high dot-product value. An optimized search finds response suggestions. The method is evaluated in a large-scale commercial e-mail application, Inbox by Gmail. Compared to a sequence-to-sequence approach, the new system achieves the same quality at a small fraction of the computational requirements and latency.
Smart Reply: Automated Response Suggestion for Email
Jun 15, 2016
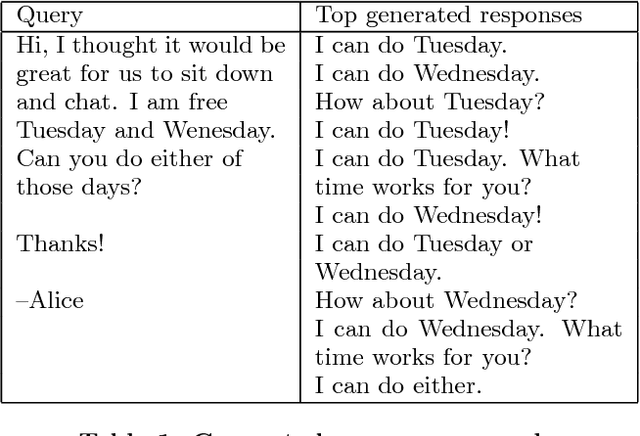
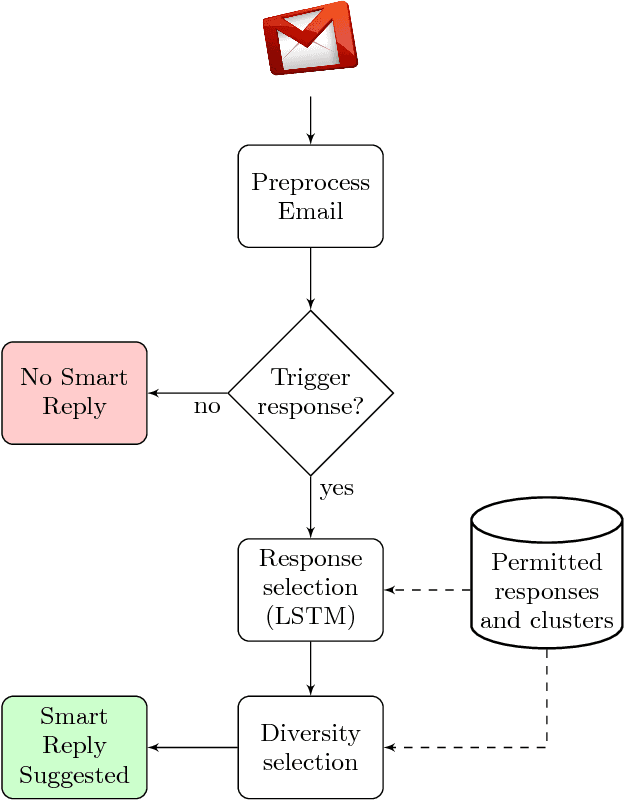

In this paper we propose and investigate a novel end-to-end method for automatically generating short email responses, called Smart Reply. It generates semantically diverse suggestions that can be used as complete email responses with just one tap on mobile. The system is currently used in Inbox by Gmail and is responsible for assisting with 10% of all mobile responses. It is designed to work at very high throughput and process hundreds of millions of messages daily. The system exploits state-of-the-art, large-scale deep learning. We describe the architecture of the system as well as the challenges that we faced while building it, like response diversity and scalability. We also introduce a new method for semantic clustering of user-generated content that requires only a modest amount of explicitly labeled data.