 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Reply: Automated Response Suggestion for Email
Jun 15, 2016
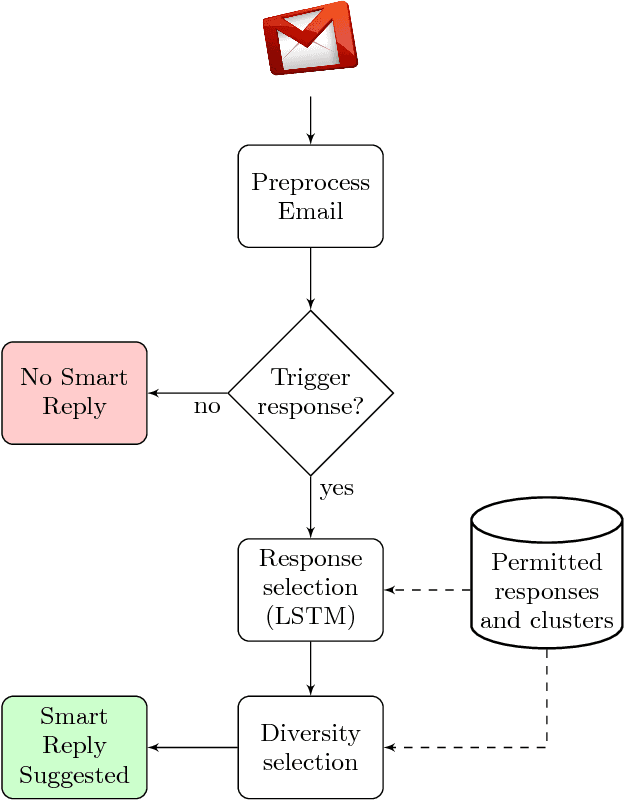

In this paper we propose and investigate a novel end-to-end method for automatically generating short email responses, called Smart Reply. It generates semantically diverse suggestions that can be used as complete email responses with just one tap on mobile. The system is currently used in Inbox by Gmail and is responsible for assisting with 10% of all mobile responses. It is designed to work at very high throughput and process hundreds of millions of messages daily. The system exploits state-of-the-art, large-scale deep learning. We describe the architecture of the system as well as the challenges that we faced while building it, like response diversity and scalability. We also introduce a new method for semantic clustering of user-generated content that requires only a modest amount of explicitly labeled data.
Probabilistic Bag-Of-Hyperlinks Model for Entity Linking
Jan 29, 2016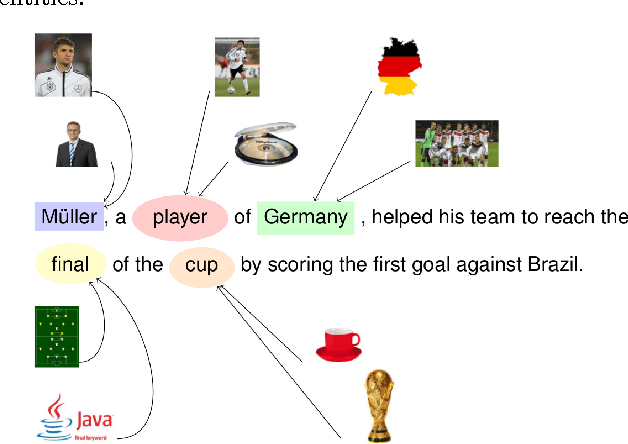



Many fundamental problems in natural language processing rely on determining what entities appear in a given text. Commonly referenced as entity linking, this step is a fundamental component of many NLP tasks such as text understanding, automatic summarization, semantic search or machine translation. Name ambiguity, word polysemy, context dependencies and a heavy-tailed distribution of entities contribute to the complexity of this problem. We here propose a probabilistic approach that makes use of an effective graphical model to perform collective entity disambiguation. Input mentions (i.e.,~linkable token spans) are disambiguated jointly across an entire document by combining a document-level prior of entity co-occurrences with local information captured from mentions and their surrounding context. The model is based on simple sufficient statistics extracted from data, thus relying on few parameters to be learned. Our method does not require extensive feature engineering, nor an expensive training procedure. We use loopy belief propagation to perform approximate inference. The low complexity of our model makes this step sufficiently fast for real-time usage. We demonstrate the accuracy of our approach on a wide range of benchmark datasets, showing that it matches, and in many cases outperforms, existing state-of-the-art methods.