 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Research Football: A Novel Reinforcement Learning Environment
Jul 25, 2019


Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Football Environment, a new reinforcement learning environment where agents are trained to play football in an advanced, physics-based 3D simulator. The resulting environment is challenging, easy to use and customize, and it is available under a permissive open-source license. In addition, it provides support for multiplayer and multi-agent experiments. We propose three full-game scenarios of varying difficulty with the Football Benchmarks and report baseline results for three commonly used reinforcement algorithms (IMPALA, PPO, and Ape-X DQN). We also provide a diverse set of simpler scenarios with the Football Academy and showcase several promising research directions.
Towards Accurate Generative Models of Video: A New Metric & Challenges
Dec 03, 2018



Recent advances in deep generative models have lead to remarkable progress in synthesizing high quality images. Following their successful application in image processing and representation learning, an important next step is to consider videos. Learning generative models of video is a much harder task, requiring a model to capture the temporal dynamics of a scene, in addition to the visual presentation of objects. Although recent attempts at formulating generative models of video have had some success, current progress is hampered by (1) the lack of qualitative metrics that consider visual quality, temporal coherence, and diversity of samples, and (2) the wide gap between purely synthetic video datasets and challenging real-world datasets in terms of complexity. To this extent we propose Fr\'echet Video Distance (FVD), a new metric for generative models of video based on FID, and StarCraft 2 Videos (SCV), a collection of progressively harder datasets that challenge the capabilities of the current iteration of generative models for video. We conduct a large-scale human study, which confirms that FVD correlates well with qualitative human judgment of generated videos, and provide initial benchmark results on SCV.
Are GANs Created Equal? A Large-Scale Study
Oct 29, 2018
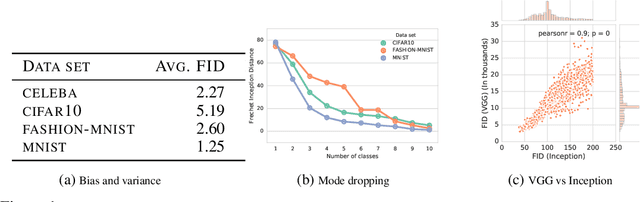
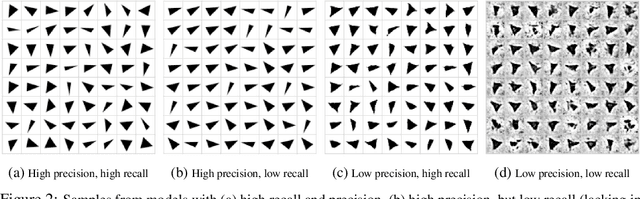
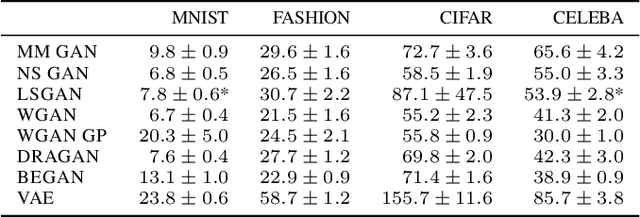
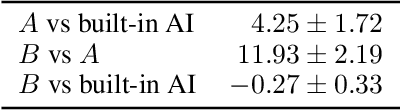
Generative adversarial networks (GAN) are a powerful subclass of generative models. Despite a very rich research activity leading to numerous interesting GAN algorithms, it is still very hard to assess which algorithm(s) perform better than others. We conduct a neutral, multi-faceted large-scale empirical study on state-of-the art models and evaluation measures. We find that most models can reach similar scores with enough hyperparameter optimization and random restarts. This suggests that improvements can arise from a higher computational budget and tuning more than fundamental algorithmic changes. To overcome some limitations of the current metrics, we also propose several data sets on which precision and recall can be computed. Our experimental results suggest that future GAN research should be based on more systematic and objective evaluation procedures. Finally, we did not find evidence that any of the tested algorithms consistently outperforms the non-saturating GAN introduced in \cite{goodfellow2014generative}.
The GAN Landscape: Losses, Architectures, Regularization, and Normalization
Oct 26, 2018



Generative adversarial networks (GANs) are a class of deep generative models which aim to learn a target distribution in an unsupervised fashion. While they were successfully applied to many problems, training a GAN is a notoriously challenging task and requires a significant amount of hyperparameter tuning, neural architecture engineering, and a non-trivial amount of "tricks". The success in many practical applications coupled with the lack of a measure to quantify the failure modes of GANs resulted in a plethora of proposed losses, regularization and normalization schemes, and neural architectures. In this work we take a sober view of the current state of GANs from a practical perspective. We reproduce the current state of the art and go beyond fairly exploring the GAN landscape. We discuss common pitfalls and reproducibility issues, open-source our code on Github, and provide pre-trained models on TensorFlow Hub.
A Case for Object Compositionality in Deep Generative Models of Images
Oct 17, 2018



Deep generative models seek to recover the process with which the observed data was generated. They may be used to synthesize new samples or to subsequently extract representations. Successful approaches in the domain of images are driven by several core inductive biases. However, a bias to account for the compositional way in which humans structure a visual scene in terms of objects has frequently been overlooked. In this work we propose to structure the generator of a GAN to consider objects and their relations explicitly, and generate images by means of composition. This provides a way to efficiently learn a more accurate generative model of real-world images, and serves as an initial step towards learning corresponding object representations. We evaluate our approach on several multi-object image datasets, and find that the generator learns to identify and disentangle information corresponding to different objects at a representational level. A human study reveals that the resulting generative model is better at generating images that are more faithful to the reference distribution.
MemGEN: Memory is All You Need
Mar 29, 2018



We propose a new learning paradigm called Deep Memory. It has the potential to completely revolutionize the Machine Learning field. Surprisingly, this paradigm has not been reinvented yet, unlike Deep Learning. At the core of this approach is the \textit{Learning By Heart} principle, well studied in primary schools all over the world. Inspired by poem recitation, or by $\pi$ decimal memorization, we propose a concrete algorithm that mimics human behavior. We implement this paradigm on the task of generative modeling, and apply to images, natural language and even the $\pi$ decimals as long as one can print them as text. The proposed algorithm even generated this paper, in a one-shot learning setting. In carefully designed experiments, we show that the generated samples are indistinguishable from the training examples, as measured by any statistical tests or metrics.
Toward Optimal Run Racing: Application to Deep Learning Calibration
Jun 20, 2017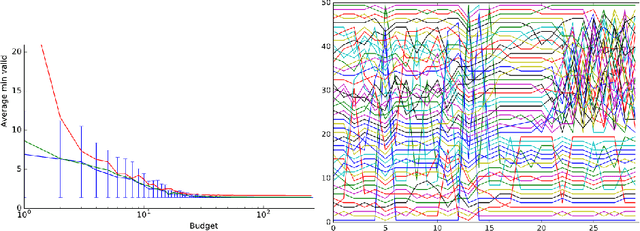
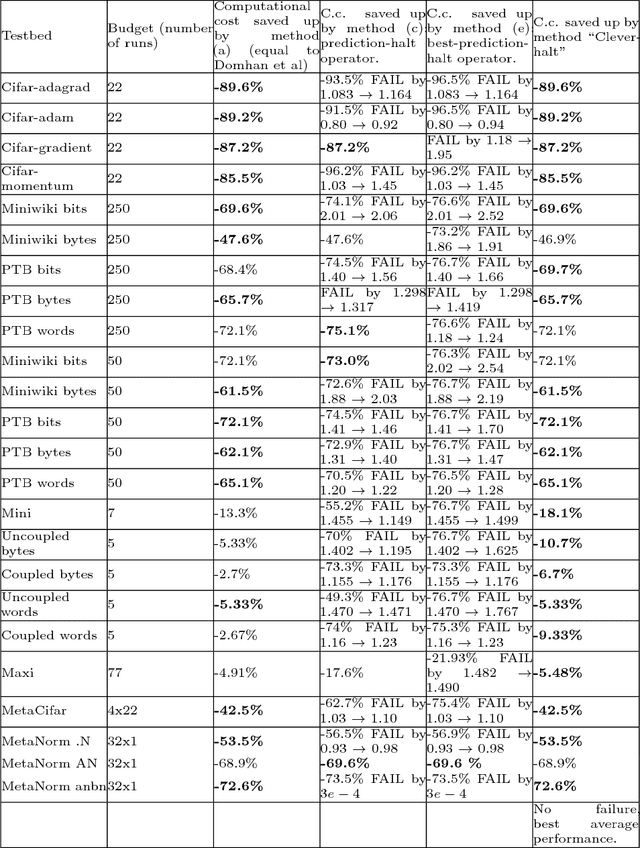
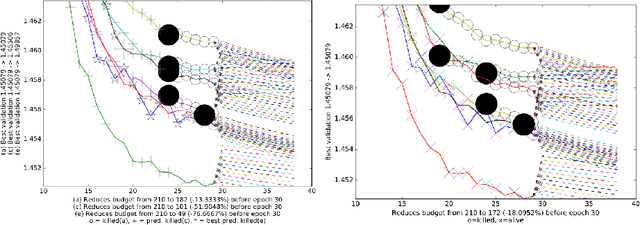
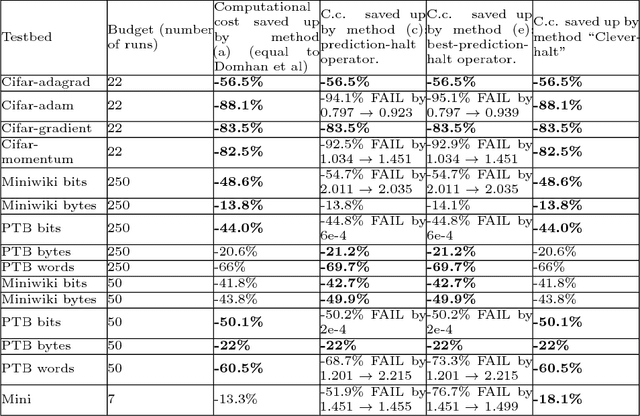
This paper aims at one-shot learning of deep neural nets, where a highly parallel setting is considered to address the algorithm calibration problem - selecting the best neural architecture and learning hyper-parameter values depending on the dataset at hand. The notoriously expensive calibration problem is optimally reduced by detecting and early stopping non-optimal runs. The theoretical contribution regards the optimality guarantees within the multiple hypothesis testing framework. Experimentations on the Cifar10, PTB and Wiki benchmarks demonstrate the relevance of the approach with a principled and consistent improvement on the state of the art with no extra hyper-parameter.
Critical Hyper-Parameters: No Random, No Cry
Jun 10, 2017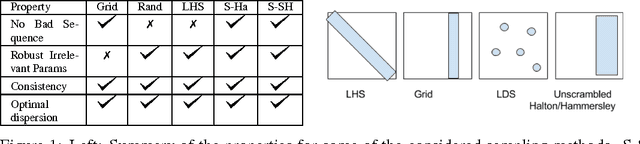
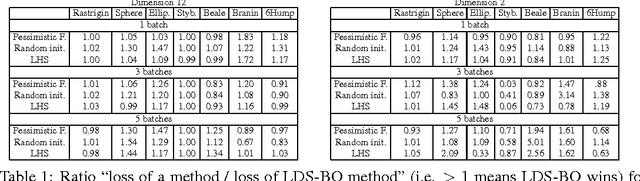

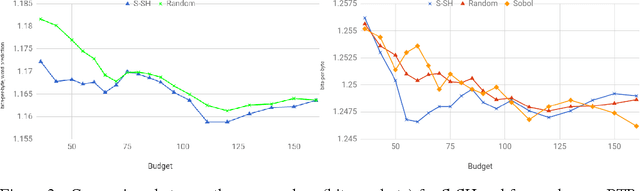
The selection of hyper-parameters is critical in Deep Learning. Because of the long training time of complex models and the availability of compute resources in the cloud, "one-shot" optimization schemes - where the sets of hyper-parameters are selected in advance (e.g. on a grid or in a random manner) and the training is executed in parallel - are commonly used. It is known that grid search is sub-optimal, especially when only a few critical parameters matter, and suggest to use random search instead. Yet, random search can be "unlucky" and produce sets of values that leave some part of the domain unexplored. Quasi-random methods, such as Low Discrepancy Sequences (LDS) avoid these issues. We show that such methods have theoretical properties that make them appealing for performing hyperparameter search, and demonstrate that, when applied to the selection of hyperparameters of complex Deep Learning models (such as state-of-the-art LSTM language models and image classification models), they yield suitable hyperparameters values with much fewer runs than random search. We propose a particularly simple LDS method which can be used as a drop-in replacement for grid or random search in any Deep Learning pipeline, both as a fully one-shot hyperparameter search or as an initializer in iterative batch optimization.
Better Text Understanding Through Image-To-Text Transfer
May 26, 2017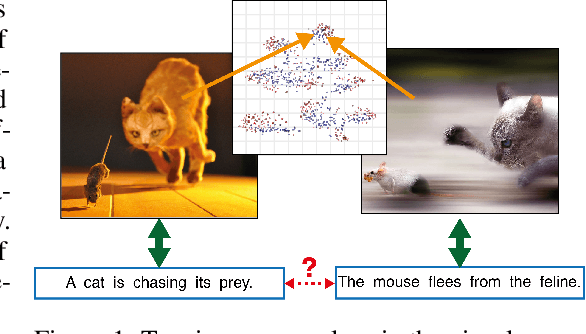
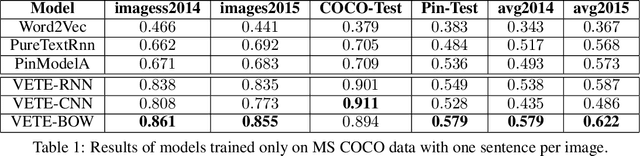
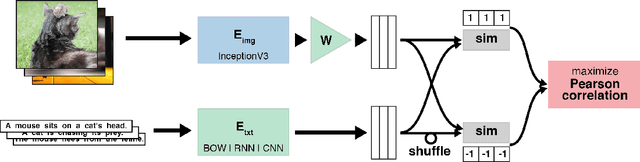
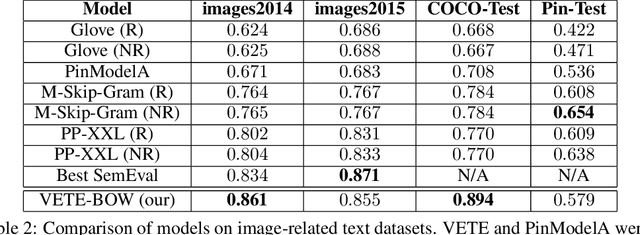
Generic text embeddings are successfully used in a variety of tasks. However, they are often learnt by capturing the co-occurrence structure from pure text corpora, resulting in limitations of their ability to generalize. In this paper, we explore models that incorporate visual information into the text representation. Based on comprehensive ablation studies, we propose a conceptually simple, yet well performing architecture. It outperforms previous multimodal approaches on a set of well established benchmarks. We also improve the state-of-the-art results for image-related text datasets, using orders of magnitude less data.
Smart Reply: Automated Response Suggestion for Email
Jun 15, 2016
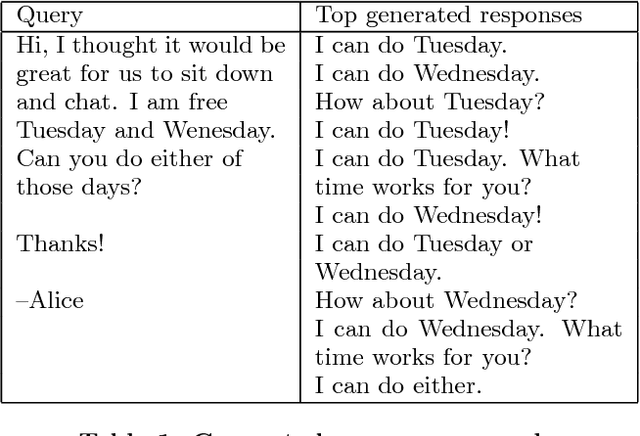
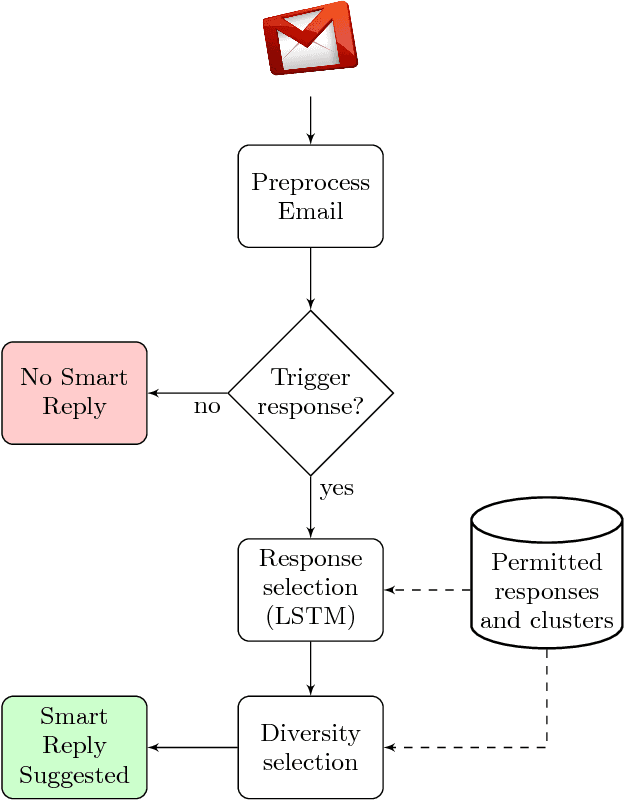

In this paper we propose and investigate a novel end-to-end method for automatically generating short email responses, called Smart Reply. It generates semantically diverse suggestions that can be used as complete email responses with just one tap on mobile. The system is currently used in Inbox by Gmail and is responsible for assisting with 10% of all mobile responses. It is designed to work at very high throughput and process hundreds of millions of messages daily. The system exploits state-of-the-art, large-scale deep learning. We describe the architecture of the system as well as the challenges that we faced while building it, like response diversity and scalability. We also introduce a new method for semantic clustering of user-generated content that requires only a modest amount of explicitly labeled data.