Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Optimal Run Racing: Application to Deep Learning Calibration
Paper and Code
Jun 20, 2017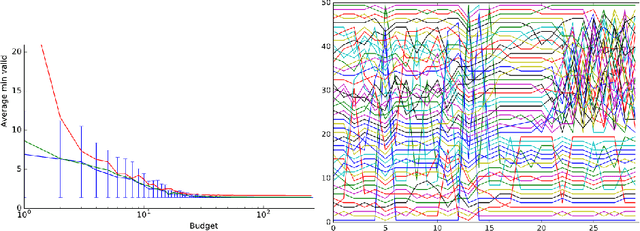
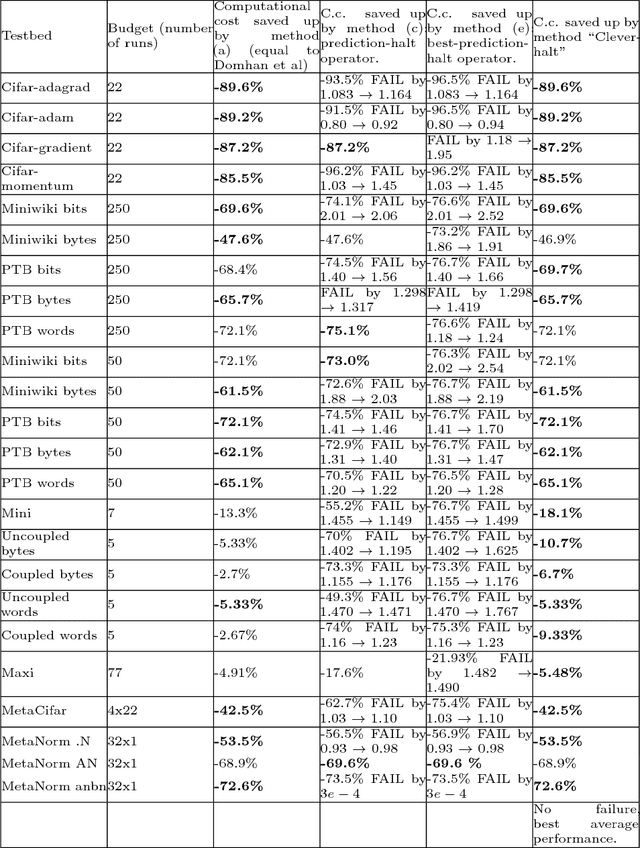
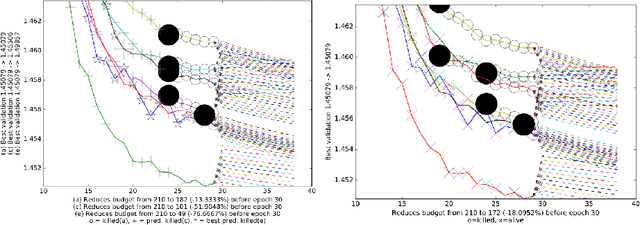
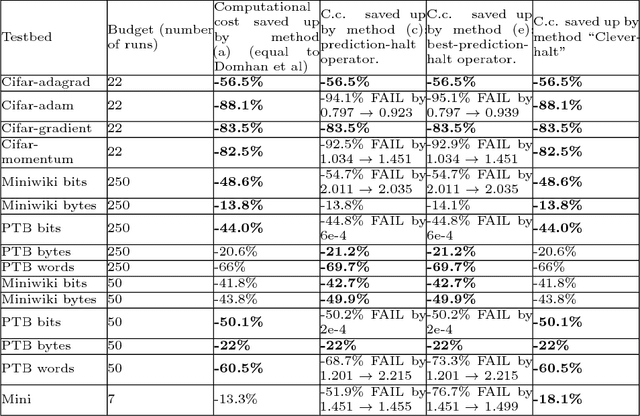
This paper aims at one-shot learning of deep neural nets, where a highly parallel setting is considered to address the algorithm calibration problem - selecting the best neural architecture and learning hyper-parameter values depending on the dataset at hand. The notoriously expensive calibration problem is optimally reduced by detecting and early stopping non-optimal runs. The theoretical contribution regards the optimality guarantees within the multiple hypothesis testing framework. Experimentations on the Cifar10, PTB and Wiki benchmarks demonstrate the relevance of the approach with a principled and consistent improvement on the state of the art with no extra hyper-parameter.
View paper on