 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023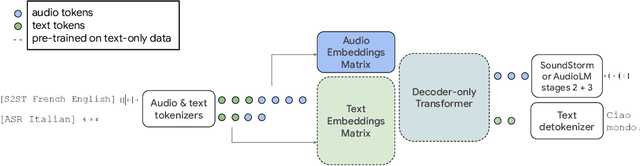



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
SoundStorm: Efficient Parallel Audio Generation
May 16, 2023We present SoundStorm, a model for efficient, non-autoregressive audio generation. SoundStorm receives as input the semantic tokens of AudioLM, and relies on bidirectional attention and confidence-based parallel decoding to generate the tokens of a neural audio codec. Compared to the autoregressive generation approach of AudioLM, our model produces audio of the same quality and with higher consistency in voice and acoustic conditions, while being two orders of magnitude faster. SoundStorm generates 30 seconds of audio in 0.5 seconds on a TPU-v4. We demonstrate the ability of our model to scale audio generation to longer sequences by synthesizing high-quality, natural dialogue segments, given a transcript annotated with speaker turns and a short prompt with the speakers' voices.
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision
Feb 07, 2023We introduce SPEAR-TTS, a multi-speaker text-to-speech (TTS) system that can be trained with minimal supervision. By combining two types of discrete speech representations, we cast TTS as a composition of two sequence-to-sequence tasks: from text to high-level semantic tokens (akin to "reading") and from semantic tokens to low-level acoustic tokens ("speaking"). Decoupling these two tasks enables training of the "speaking" module using abundant audio-only data, and unlocks the highly efficient combination of pretraining and backtranslation to reduce the need for parallel data when training the "reading" component. To control the speaker identity, we adopt example prompting, which allows SPEAR-TTS to generalize to unseen speakers using only a short sample of 3 seconds, without any explicit speaker representation or speaker-id labels. Our experiments demonstrate that SPEAR-TTS achieves a character error rate that is competitive with state-of-the-art methods using only 15 minutes of parallel data, while matching ground-truth speech in terms of naturalness and acoustic quality, as measured in subjective tests.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022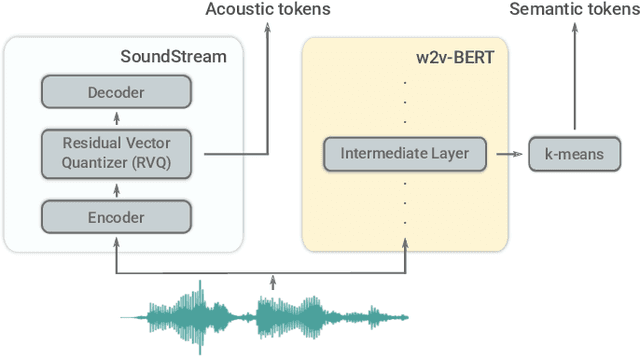

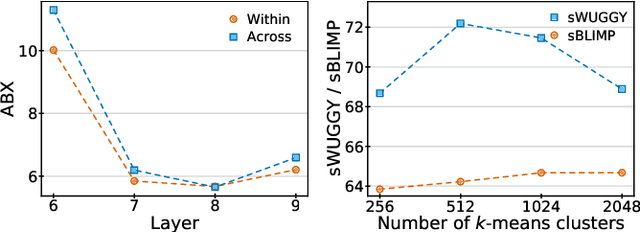

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
Nov 04, 2021



We introduce RLDS (Reinforcement Learning Datasets), an ecosystem for recording, replaying, manipulating, annotating and sharing data in the context of Sequential Decision Making (SDM) including Reinforcement Learning (RL), Learning from Demonstrations, Offline RL or Imitation Learning. RLDS enables not only reproducibility of existing research and easy generation of new datasets, but also accelerates novel research. By providing a standard and lossless format of datasets it enables to quickly test new algorithms on a wider range of tasks. The RLDS ecosystem makes it easy to share datasets without any loss of information and to be agnostic to the underlying original format when applying various data processing pipelines to large collections of datasets. Besides, RLDS provides tools for collecting data generated by either synthetic agents or humans, as well as for inspecting and manipulating the collected data. Ultimately, integration with TFDS facilitates the sharing of RL datasets with the research community.
Continuous Control with Action Quantization from Demonstrations
Oct 19, 2021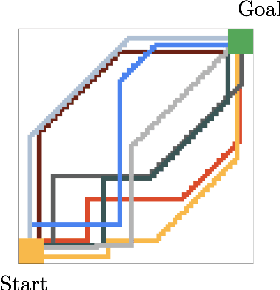
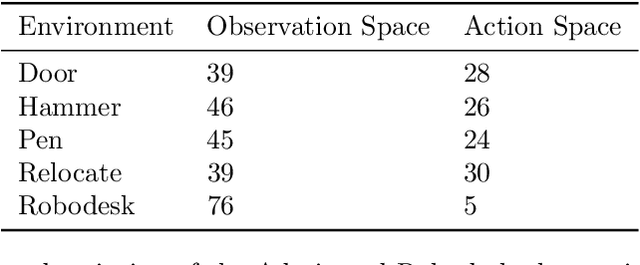

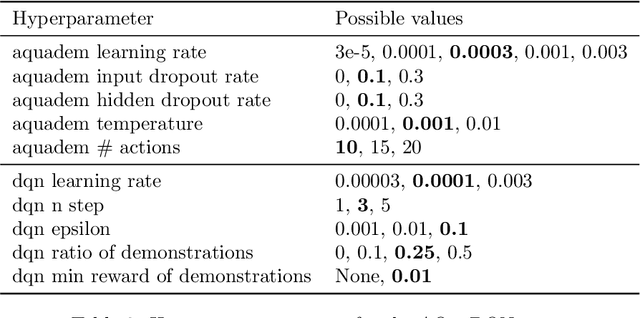
In Reinforcement Learning (RL), discrete actions, as opposed to continuous actions, result in less complex exploration problems and the immediate computation of the maximum of the action-value function which is central to dynamic programming-based methods. In this paper, we propose a novel method: Action Quantization from Demonstrations (AQuaDem) to learn a discretization of continuous action spaces by leveraging the priors of demonstrations. This dramatically reduces the exploration problem, since the actions faced by the agent not only are in a finite number but also are plausible in light of the demonstrator's behavior. By discretizing the action space we can apply any discrete action deep RL algorithm to the continuous control problem. We evaluate the proposed method on three different setups: RL with demonstrations, RL with play data --demonstrations of a human playing in an environment but not solving any specific task-- and Imitation Learning. For all three setups, we only consider human data, which is more challenging than synthetic data. We found that AQuaDem consistently outperforms state-of-the-art continuous control methods, both in terms of performance and sample efficiency. We provide visualizations and videos in the paper's website: https://google-research.github.io/aquadem.
What Matters for Adversarial Imitation Learning?
Jun 01, 2021

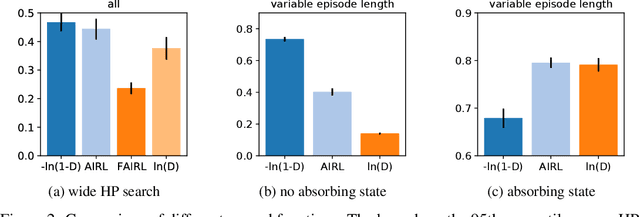

Adversarial imitation learning has become a popular framework for imitation in continuous control. Over the years, several variations of its components were proposed to enhance the performance of the learned policies as well as the sample complexity of the algorithm. In practice, these choices are rarely tested all together in rigorous empirical studies. It is therefore difficult to discuss and understand what choices, among the high-level algorithmic options as well as low-level implementation details, matter. To tackle this issue, we implement more than 50 of these choices in a generic adversarial imitation learning framework and investigate their impacts in a large-scale study (>500k trained agents) with both synthetic and human-generated demonstrations. While many of our findings confirm common practices, some of them are surprising or even contradict prior work. In particular, our results suggest that artificial demonstrations are not a good proxy for human data and that the very common practice of evaluating imitation algorithms only with synthetic demonstrations may lead to algorithms which perform poorly in the more realistic scenarios with human demonstrations.
Hyperparameter Selection for Imitation Learning
May 25, 2021
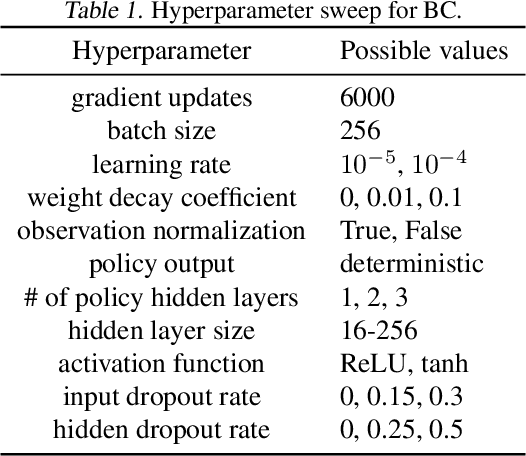
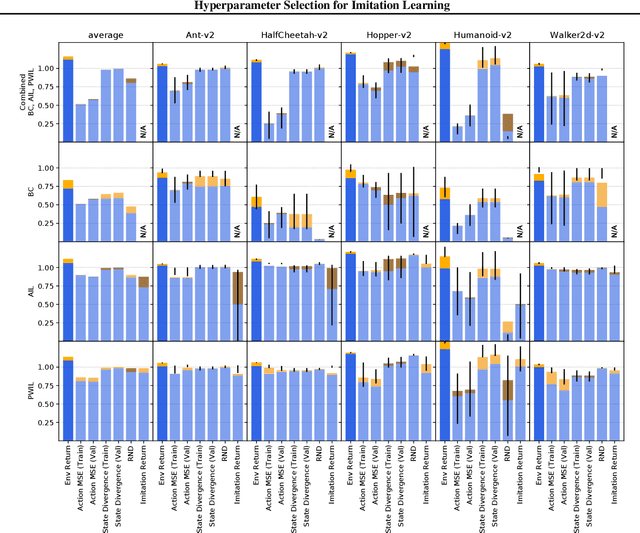
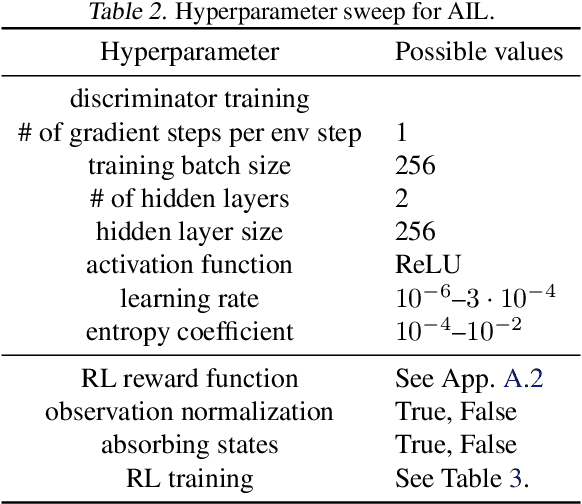
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.