 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023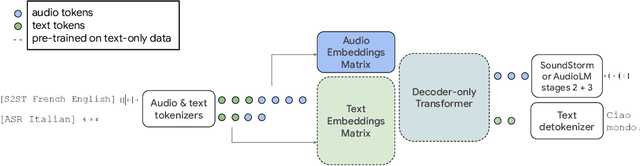



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
Disentangling speech from surroundings in a neural audio codec
Mar 29, 2022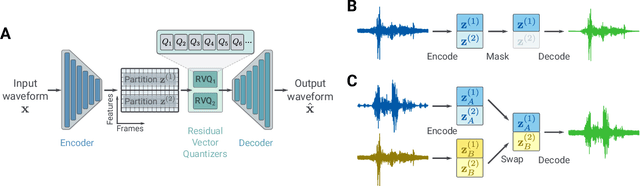
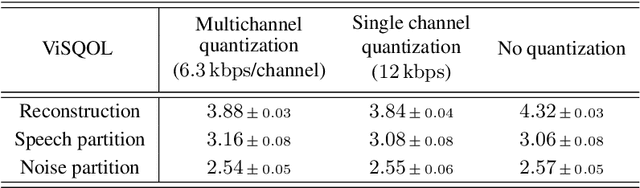
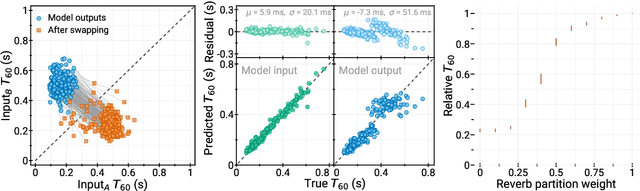
We present a method to separate speech signals from noisy environments in the compressed domain of a neural audio codec. We introduce a new training procedure that allows our model to produce structured encodings of audio waveforms given by embedding vectors, where one part of the embedding vector represents the speech signal, and the rest represents the environment. We achieve this by partitioning the embeddings of different input waveforms and training the model to faithfully reconstruct audio from mixed partitions, thereby ensuring each partition encodes a separate audio attribute. As use cases, we demonstrate the separation of speech from background noise or from reverberation characteristics. Our method also allows for targeted adjustments of the audio output characteristics.
LEAF: A Learnable Frontend for Audio Classification
Jan 21, 2021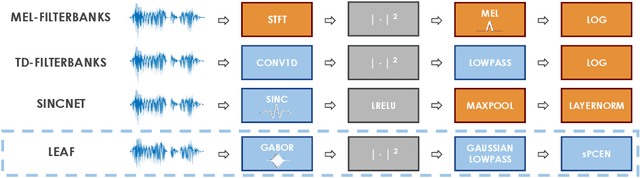
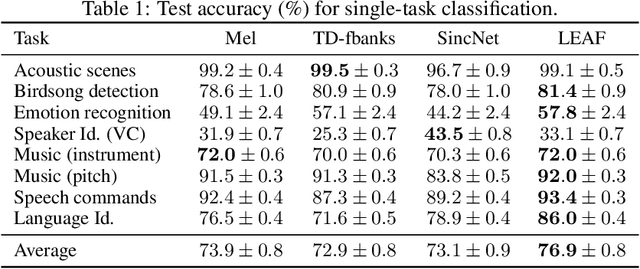
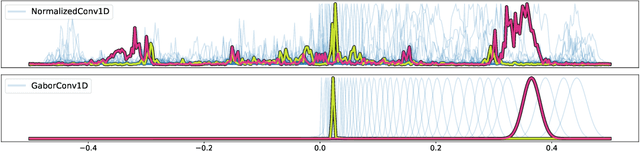

Mel-filterbanks are fixed, engineered audio features which emulate human perception and have been used through the history of audio understanding up to today. However, their undeniable qualities are counterbalanced by the fundamental limitations of handmade representations. In this work we show that we can train a single learnable frontend that outperforms mel-filterbanks on a wide range of audio signals, including speech, music, audio events and animal sounds, providing a general-purpose learned frontend for audio classification. To do so, we introduce a new principled, lightweight, fully learnable architecture that can be used as a drop-in replacement of mel-filterbanks. Our system learns all operations of audio features extraction, from filtering to pooling, compression and normalization, and can be integrated into any neural network at a negligible parameter cost. We perform multi-task training on eight diverse audio classification tasks, and show consistent improvements of our model over mel-filterbanks and previous learnable alternatives. Moreover, our system outperforms the current state-of-the-art learnable frontend on Audioset, with orders of magnitude fewer parameters.
Learning audio representations via phase prediction
Oct 25, 2019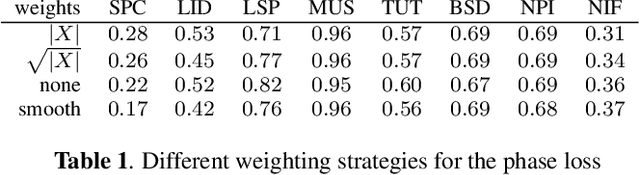
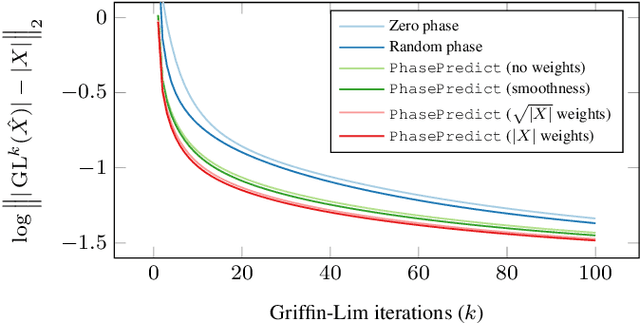
We learn audio representations by solving a novel self-supervised learning task, which consists of predicting the phase of the short-time Fourier transform from its magnitude. A convolutional encoder is used to map the magnitude spectrum of the input waveform to a lower dimensional embedding. A convolutional decoder is then used to predict the instantaneous frequency (i.e., the temporal rate of change of the phase) from such embedding. To evaluate the quality of the learned representations, we evaluate how they transfer to a wide variety of downstream audio tasks. Our experiments reveal that the phase prediction task leads to representations that generalize across different tasks, partially bridging the gap with fully-supervised models. In addition, we show that the predicted phase can be used as initialization of the Griffin-Lim algorithm, thus reducing the number of iterations needed to reconstruct the waveform in the time domain.
Self-supervised audio representation learning for mobile devices
May 24, 2019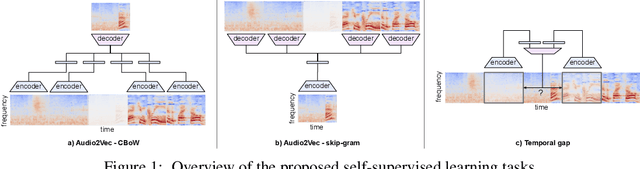
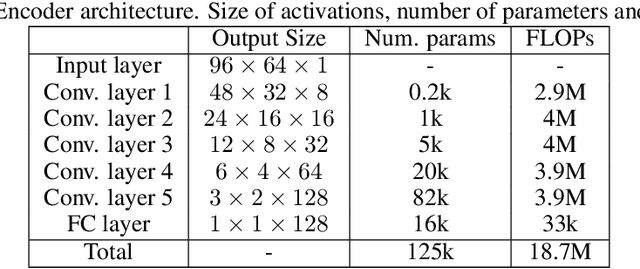
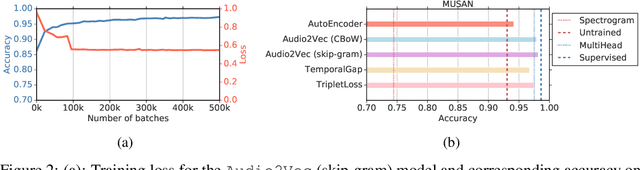
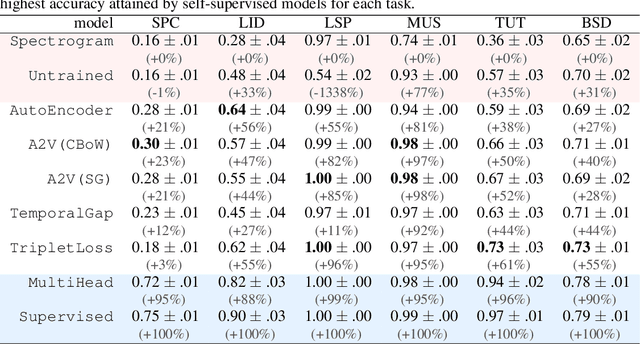
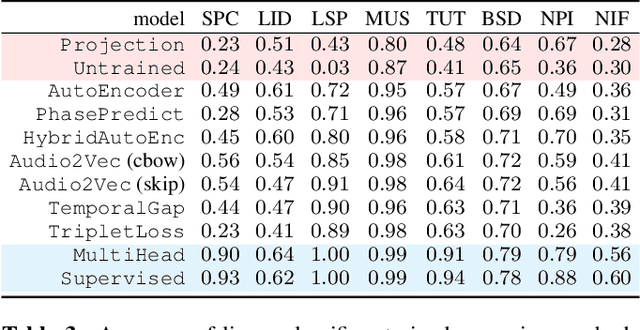
We explore self-supervised models that can be potentially deployed on mobile devices to learn general purpose audio representations. Specifically, we propose methods that exploit the temporal context in the spectrogram domain. One method estimates the temporal gap between two short audio segments extracted at random from the same audio clip. The other methods are inspired by Word2Vec, a popular technique used to learn word embeddings, and aim at reconstructing a temporal spectrogram slice from past and future slices or, alternatively, at reconstructing the context of surrounding slices from the current slice. We focus our evaluation on small encoder architectures, which can be potentially run on mobile devices during both inference (re-using a common learned representation across multiple downstream tasks) and training (capturing the true data distribution without compromising users' privacy when combined with federated learning). We evaluate the quality of the embeddings produced by the self-supervised learning models, and show that they can be re-used for a variety of downstream tasks, and for some tasks even approach the performance of fully supervised models of similar size.