 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting LLMs for Code Editing: Struggles and Remedies
Apr 28, 2025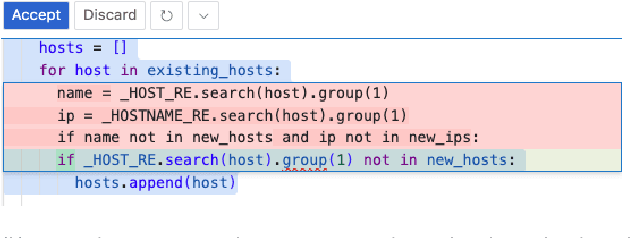

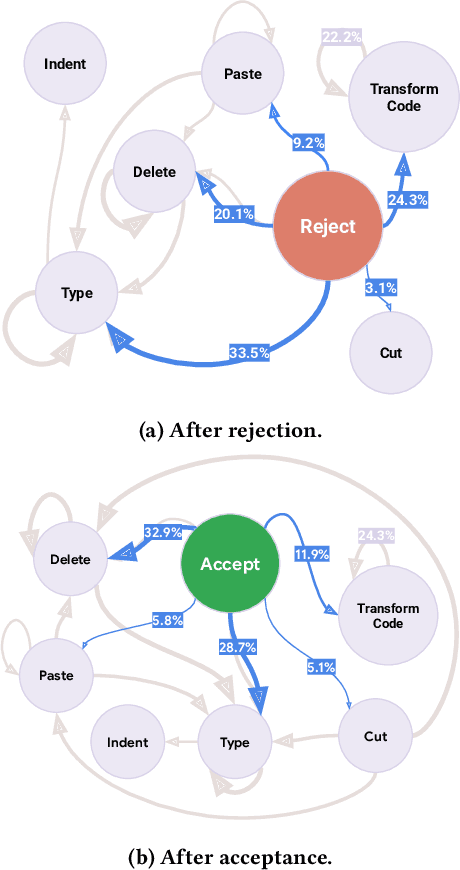

Large Language Models (LLMs) are rapidly transforming software engineering, with coding assistants embedded in an IDE becoming increasingly prevalent. While research has focused on improving the tools and understanding developer perceptions, a critical gap exists in understanding how developers actually use these tools in their daily workflows, and, crucially, where they struggle. This paper addresses part of this gap through a multi-phased investigation of developer interactions with an LLM-powered code editing and transformation feature, Transform Code, in an IDE widely used at Google. First, we analyze telemetry logs of the feature usage, revealing that frequent re-prompting can be an indicator of developer struggles with using Transform Code. Second, we conduct a qualitative analysis of unsatisfactory requests, identifying five key categories of information often missing from developer prompts. Finally, based on these findings, we propose and evaluate a tool, AutoPrompter, for automatically improving prompts by inferring missing information from the surrounding code context, leading to a 27% improvement in edit correctness on our test set.
Disentangling speech from surroundings in a neural audio codec
Mar 29, 2022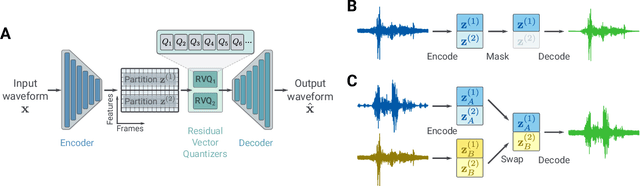
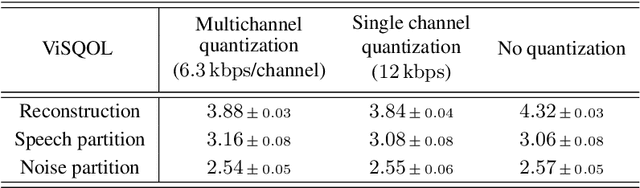
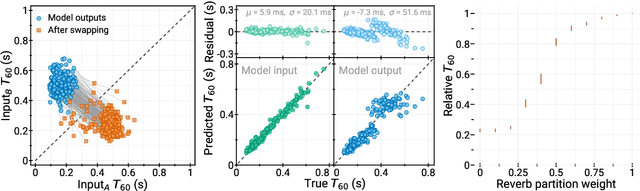
We present a method to separate speech signals from noisy environments in the compressed domain of a neural audio codec. We introduce a new training procedure that allows our model to produce structured encodings of audio waveforms given by embedding vectors, where one part of the embedding vector represents the speech signal, and the rest represents the environment. We achieve this by partitioning the embeddings of different input waveforms and training the model to faithfully reconstruct audio from mixed partitions, thereby ensuring each partition encodes a separate audio attribute. As use cases, we demonstrate the separation of speech from background noise or from reverberation characteristics. Our method also allows for targeted adjustments of the audio output characteristics.
SoundStream: An End-to-End Neural Audio Codec
Jul 07, 2021



We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.