 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Time-Frequency Features for Binaural Sound Source Localization
Nov 18, 2025This study presents a systematic evaluation of time-frequency feature design for binaural sound source localization (SSL), focusing on how feature selection influences model performance across diverse conditions. We investigate the performance of a convolutional neural network (CNN) model using various combinations of amplitude-based features (magnitude spectrogram, interaural level difference - ILD) and phase-based features (phase spectrogram, interaural phase difference - IPD). Evaluations on in-domain and out-of-domain data with mismatched head-related transfer functions (HRTFs) reveal that carefully chosen feature combinations often outperform increases in model complexity. While two-feature sets such as ILD + IPD are sufficient for in-domain SSL, generalization to diverse content requires richer inputs combining channel spectrograms with both ILD and IPD. Using the optimal feature sets, our low-complexity CNN model achieves competitive performance. Our findings underscore the importance of feature design in binaural SSL and provide practical guidance for both domain-specific and general-purpose localization.
BINAQUAL: A Full-Reference Objective Localization Similarity Metric for Binaural Audio
May 17, 2025Spatial audio enhances immersion in applications such as virtual reality, augmented reality, gaming, and cinema by creating a three-dimensional auditory experience. Ensuring the spatial fidelity of binaural audio is crucial, given that processes such as compression, encoding, or transmission can alter localization cues. While subjective listening tests like MUSHRA remain the gold standard for evaluating spatial localization quality, they are costly and time-consuming. This paper introduces BINAQUAL, a full-reference objective metric designed to assess localization similarity in binaural audio recordings. BINAQUAL adapts the AMBIQUAL metric, originally developed for localization quality assessment in ambisonics audio format to the binaural domain. We evaluate BINAQUAL across five key research questions, examining its sensitivity to variations in sound source locations, angle interpolations, surround speaker layouts, audio degradations, and content diversity. Results demonstrate that BINAQUAL effectively differentiates between subtle spatial variations and correlates strongly with subjective listening tests, making it a reliable metric for binaural localization quality assessment. The proposed metric provides a robust benchmark for ensuring spatial accuracy in binaural audio processing, paving the way for improved objective evaluations in immersive audio applications.
Binamix -- A Python Library for Generating Binaural Audio Datasets
May 02, 2025The increasing demand for spatial audio in applications such as virtual reality, immersive media, and spatial audio research necessitates robust solutions to generate binaural audio data sets for use in testing and validation. Binamix is an open-source Python library designed to facilitate programmatic binaural mixing using the extensive SADIE II Database, which provides Head Related Impulse Response (HRIR) and Binaural Room Impulse Response (BRIR) data for 20 subjects. The Binamix library provides a flexible and repeatable framework for creating large-scale spatial audio datasets, making it an invaluable resource for codec evaluation, audio quality metric development, and machine learning model training. A range of pre-built example scripts, utility functions, and visualization plots further streamline the process of custom pipeline creation. This paper presents an overview of the library's capabilities, including binaural rendering, impulse response interpolation, and multi-track mixing for various speaker layouts. The tools utilize a modified Delaunay triangulation technique to achieve accurate HRIR/BRIR interpolation where desired angles are not present in the data. By supporting a wide range of parameters such as azimuth, elevation, subject Impulse Responses (IRs), speaker layouts, mixing controls, and more, the library enables researchers to create large binaural datasets for any downstream purpose. Binamix empowers researchers and developers to advance spatial audio applications with reproducible methodologies by offering an open-source solution for binaural rendering and dataset generation. We release the library under the Apache 2.0 License at https://github.com/QxLabIreland/Binamix/
Perceptual Audio Coding: A 40-Year Historical Perspective
Apr 22, 2025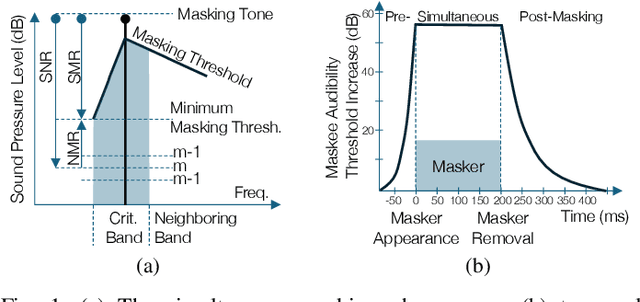



In the history of audio and acoustic signal processing, perceptual audio coding has certainly excelled as a bright success story by its ubiquitous deployment in virtually all digital media devices, such as computers, tablets, mobile phones, set-top-boxes, and digital radios. From a technology perspective, perceptual audio coding has undergone tremendous development from the first very basic perceptually driven coders (including the popular mp3 format) to today's full-blown integrated coding/rendering systems. This paper provides a historical overview of this research journey by pinpointing the pivotal development steps in the evolution of perceptual audio coding. Finally, it provides thoughts about future directions in this area.
SCOREQ: Speech Quality Assessment with Contrastive Regression
Oct 09, 2024In this paper, we present SCOREQ, a novel approach for speech quality prediction. SCOREQ is a triplet loss function for contrastive regression that addresses the domain generalisation shortcoming exhibited by state of the art no-reference speech quality metrics. In the paper we: (i) illustrate the problem of L2 loss training failing at capturing the continuous nature of the mean opinion score (MOS) labels; (ii) demonstrate the lack of generalisation through a benchmarking evaluation across several speech domains; (iii) outline our approach and explore the impact of the architectural design decisions through incremental evaluation; (iv) evaluate the final model against state of the art models for a wide variety of data and domains. The results show that the lack of generalisation observed in state of the art speech quality metrics is addressed by SCOREQ. We conclude that using a triplet loss function for contrastive regression improves generalisation for speech quality prediction models but also has potential utility across a wide range of applications using regression-based predictive models.
Neural Speech and Audio Coding
Aug 13, 2024This paper explores the integration of model-based and data-driven approaches within the realm of neural speech and audio coding systems. It highlights the challenges posed by the subjective evaluation processes of speech and audio codecs and discusses the limitations of purely data-driven approaches, which often require inefficiently large architectures to match the performance of model-based methods. The study presents hybrid systems as a viable solution, offering significant improvements to the performance of conventional codecs through meticulously chosen design enhancements. Specifically, it introduces a neural network-based signal enhancer designed to post-process existing codecs' output, along with the autoencoder-based end-to-end models and LPCNet--hybrid systems that combine linear predictive coding (LPC) with neural networks. Furthermore, the paper delves into predictive models operating within custom feature spaces (TF-Codec) or predefined transform domains (MDCTNet) and examines the use of psychoacoustically calibrated loss functions to train end-to-end neural audio codecs. Through these investigations, the paper demonstrates the potential of hybrid systems to advance the field of speech and audio coding by bridging the gap between traditional model-based approaches and modern data-driven techniques.
NOMAD: Unsupervised Learning of Perceptual Embeddings for Speech Enhancement and Non-matching Reference Audio Quality Assessment
Sep 28, 2023This paper presents NOMAD (Non-Matching Audio Distance), a differentiable perceptual similarity metric that measures the distance of a degraded signal against non-matching references. The proposed method is based on learning deep feature embeddings via a triplet loss guided by the Neurogram Similarity Index Measure (NSIM) to capture degradation intensity. During inference, the similarity score between any two audio samples is computed through Euclidean distance of their embeddings. NOMAD is fully unsupervised and can be used in general perceptual audio tasks for audio analysis e.g. quality assessment and generative tasks such as speech enhancement and speech synthesis. The proposed method is evaluated with 3 tasks. Ranking degradation intensity, predicting speech quality, and as a loss function for speech enhancement. Results indicate NOMAD outperforms other non-matching reference approaches in both ranking degradation intensity and quality assessment, exhibiting competitive performance with full-reference audio metrics. NOMAD demonstrates a promising technique that mimics human capabilities in assessing audio quality with non-matching references to learn perceptual embeddings without the need for human-generated labels.
LMCodec: A Low Bitrate Speech Codec With Causal Transformer Models
Mar 23, 2023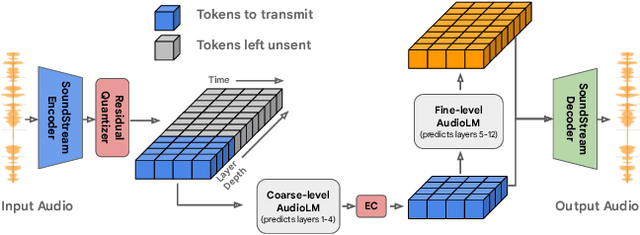
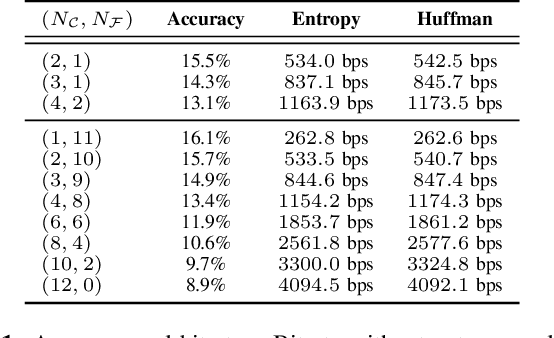
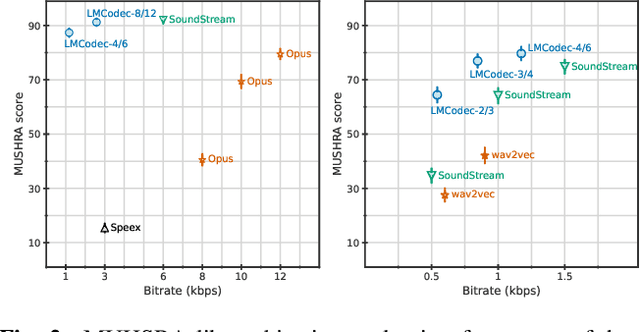
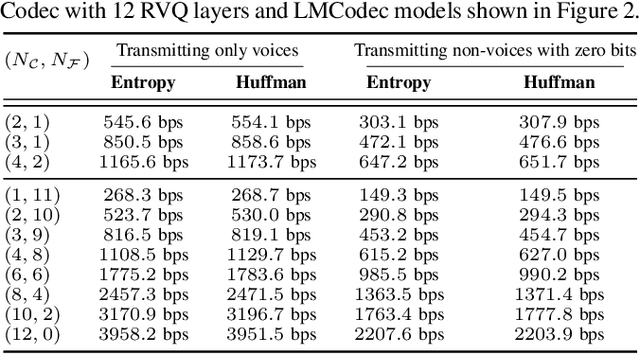
We introduce LMCodec, a causal neural speech codec that provides high quality audio at very low bitrates. The backbone of the system is a causal convolutional codec that encodes audio into a hierarchy of coarse-to-fine tokens using residual vector quantization. LMCodec trains a Transformer language model to predict the fine tokens from the coarse ones in a generative fashion, allowing for the transmission of fewer codes. A second Transformer predicts the uncertainty of the next codes given the past transmitted codes, and is used to perform conditional entropy coding. A MUSHRA subjective test was conducted and shows that the quality is comparable to reference codecs at higher bitrates. Example audio is available at https://mjenrungrot.github.io/chrome-media-audio-papers/publications/lmcodec.
Using Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Sep 14, 2022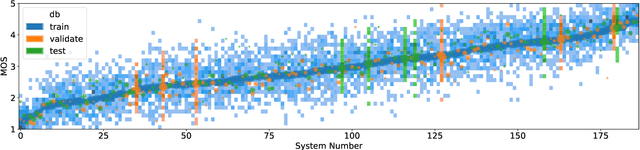
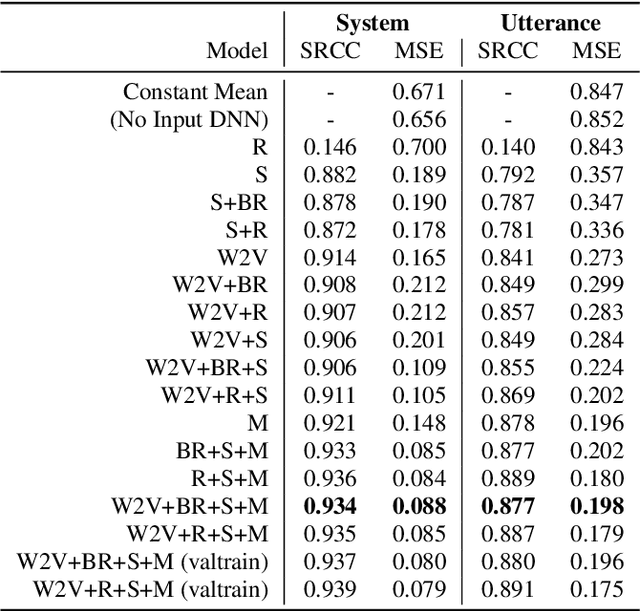
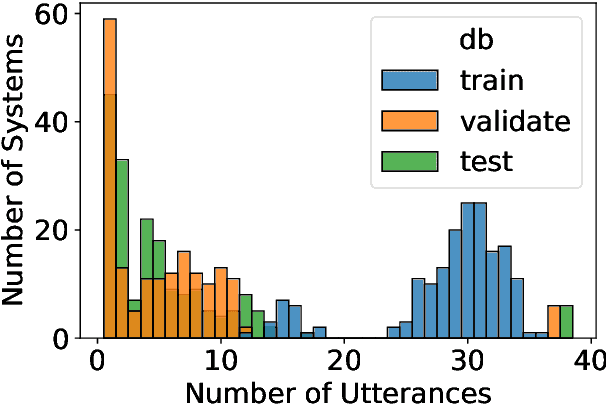
Non-reference speech quality models are important for a growing number of applications. The VoiceMOS 2022 challenge provided a dataset of synthetic voice conversion and text-to-speech samples with subjective labels. This study looks at the amount of variance that can be explained in subjective ratings of speech quality from metadata and the distribution imbalances of the dataset. Speech quality models were constructed using wav2vec 2.0 with additional metadata features that included rater groups and system identifiers and obtained competitive metrics including a Spearman rank correlation coefficient (SRCC) of 0.934 and MSE of 0.088 at the system-level, and 0.877 and 0.198 at the utterance-level. Using data and metadata that the test restricted or blinded further improved the metrics. A metadata analysis showed that the system-level metrics do not represent the model's system-level prediction as a result of the wide variation in the number of utterances used for each system on the validation and test datasets. We conclude that, in general, conditions should have enough utterances in the test set to bound the sample mean error, and be relatively balanced in utterance count between systems, otherwise the utterance-level metrics may be more reliable and interpretable.
Ultra-Low-Bitrate Speech Coding with Pretrained Transformers
Jul 05, 2022
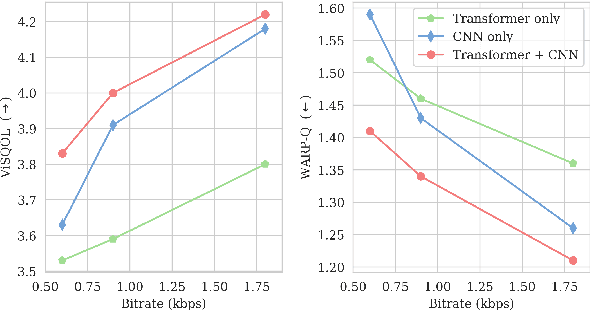
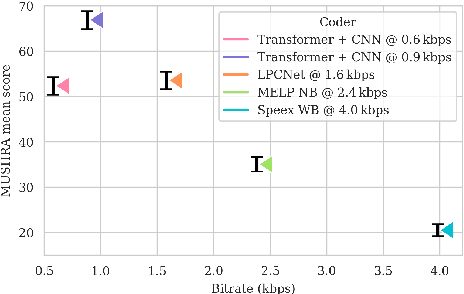
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.