 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Deep Learning MOS Predictors for Speech Synthesis Quality
Apr 05, 2022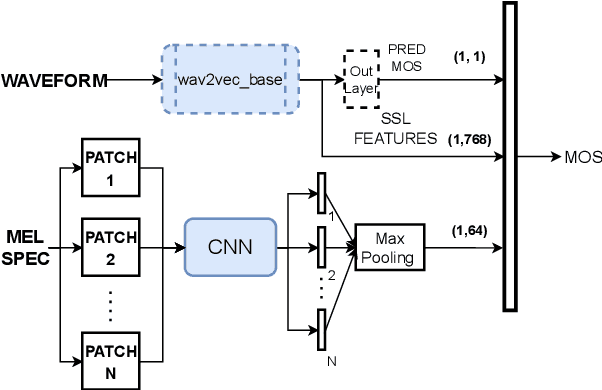
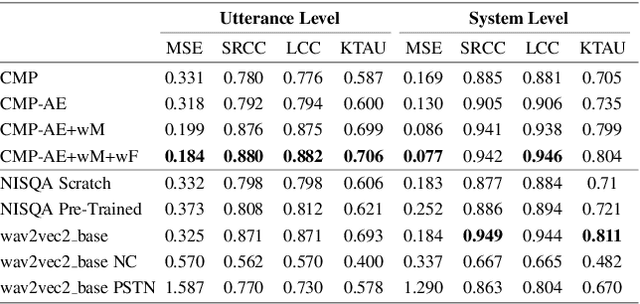
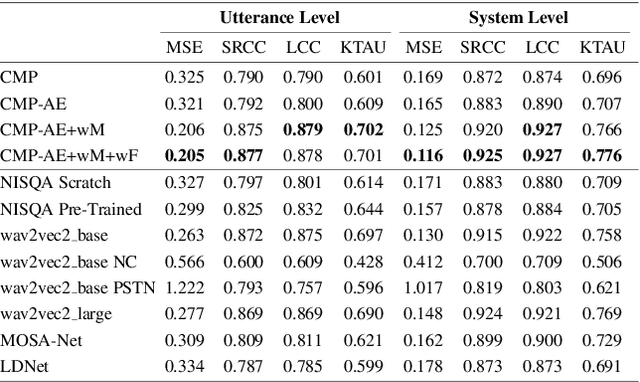
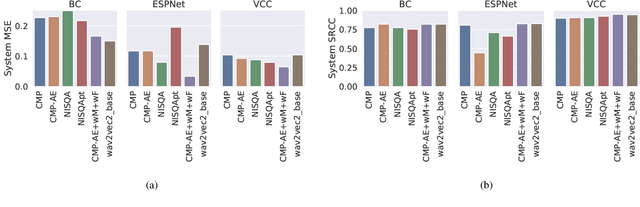
This paper introduces a comparison of deep learning-based techniques for the MOS prediction task of synthesised speech in the Interspeech VoiceMOS challenge. Using the data from the main track of the VoiceMOS challenge we explore both existing predictors and propose new ones. We evaluate two groups of models: NISQA-based models and techniques based on fine-tuning the self-supervised learning (SSL) model wav2vec2_base. Our findings show that a simplified version of NISQA with 40% fewer parameters achieves results close to the original NISQA architecture on both utterance-level and system-level performances. Pre-training NISQA with the NISQA corpus improves utterance-level performance but shows no benefit on the system-level performance. Also, the NISQA-based models perform close to LDNet and MOSANet, 2 out of 3 baselines of the challenge. Fine-tuning wav2vec2_base shows superior performance than the NISQA-based models. We explore the mismatch between natural and synthetic speech and discovered that the performance of the SSL model drops consistently when fine-tuned on natural speech samples. We show that adding CNN features with the SSL model does not improve the baseline performance. Finally, we show that the system type has an impact on the predictions of the non-SSL models.