 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-SSL-MOS: Self-supervised Learning MOS Prediction with Spectral Augmentation for Generalized Multi-Rate Speech Assessment
Feb 16, 2026Designing a speech quality assessment (SQA) system for estimating mean-opinion-score (MOS) of multi-rate speech with varying sampling frequency (16-48 kHz) is a challenging task. The challenge arises due to the limited availability of a MOS-labeled training dataset comprising multi-rate speech samples. While self-supervised learning (SSL) models have been widely adopted in SQA to boost performance, a key limitation is that they are pretrained on 16 kHz speech and therefore discard high-frequency information present in higher sampling rates. To address this issue, we propose a spectrogram-augmented SSL method that incorporates high-frequency features (up to 48 kHz sampling rate) through a parallel-branch architecture. We further introduce a two-step training scheme: the model is first pre-trained on a large 48 kHz dataset and then fine-tuned on a smaller multi-rate dataset. Experimental results show that leveraging high-frequency information overlooked by SSL features is crucial for accurate multi-rate SQA, and that the proposed two-step training substantially improves generalization when multi-rate data is limited.
Selection of Layers from Self-supervised Learning Models for Predicting Mean-Opinion-Score of Speech
Aug 12, 2025Self-supervised learning (SSL) models like Wav2Vec2, HuBERT, and WavLM have been widely used in speech processing. These transformer-based models consist of multiple layers, each capturing different levels of representation. While prior studies explored their layer-wise representations for efficiency and performance, speech quality assessment (SQA) models predominantly rely on last-layer features, leaving intermediate layers underexamined. In this work, we systematically evaluate different layers of multiple SSL models for predicting mean-opinion-score (MOS). Features from each layer are fed into a lightweight regression network to assess effectiveness. Our experiments consistently show early-layers features outperform or match those from the last layer, leading to significant improvements over conventional approaches and state-of-the-art MOS prediction models. These findings highlight the advantages of early-layer selection, offering enhanced performance and reduced system complexity.
Multivariate Probabilistic Assessment of Speech Quality
Jun 05, 2025The mean opinion score (MOS) is a standard metric for assessing speech quality, but its singular focus fails to identify specific distortions when low scores are observed. The NISQA dataset addresses this limitation by providing ratings across four additional dimensions: noisiness, coloration, discontinuity, and loudness, alongside MOS. In this paper, we extend the explored univariate MOS estimation to a multivariate framework by modeling these dimensions jointly using a multivariate Gaussian distribution. Our approach utilizes Cholesky decomposition to predict covariances without imposing restrictive assumptions and extends probabilistic affine transformations to a multivariate context. Experimental results show that our model performs on par with state-of-the-art methods in point estimation, while uniquely providing uncertainty and correlation estimates across speech quality dimensions. This enables better diagnosis of poor speech quality and informs targeted improvements.
Impairments are Clustered in Latents of Deep Neural Network-based Speech Quality Models
Apr 30, 2025In this article, we provide an experimental observation: Deep neural network (DNN) based speech quality assessment (SQA) models have inherent latent representations where many types of impairments are clustered. While DNN-based SQA models are not trained for impairment classification, our experiments show good impairment classification results in an appropriate SQA latent representation. We investigate the clustering of impairments using various kinds of audio degradations that include different types of noises, waveform clipping, gain transition, pitch shift, compression, reverberation, etc. To visualize the clusters we perform classification of impairments in the SQA-latent representation domain using a standard k-nearest neighbor (kNN) classifier. We also develop a new DNN-based SQA model, named DNSMOS+, to examine whether an improvement in SQA leads to an improvement in impairment classification. The classification accuracy is 94% for LibriAugmented dataset with 16 types of impairments and 54% for ESC-50 dataset with 50 types of real noises.
Towards sub-millisecond latency real-time speech enhancement models on hearables
Sep 26, 2024

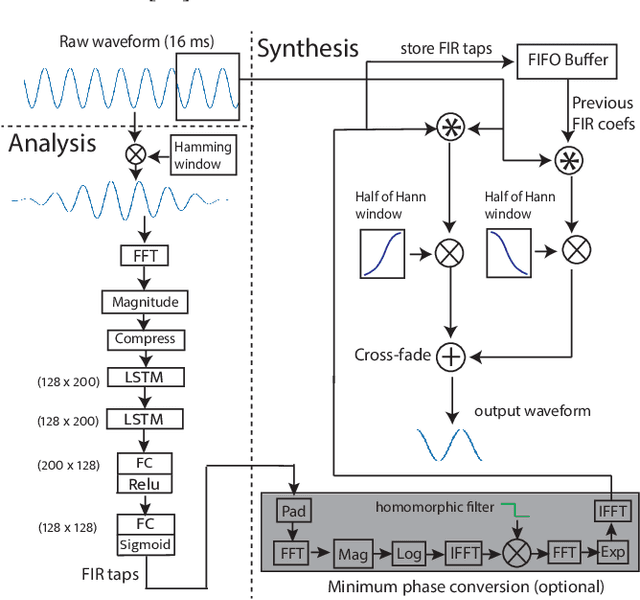
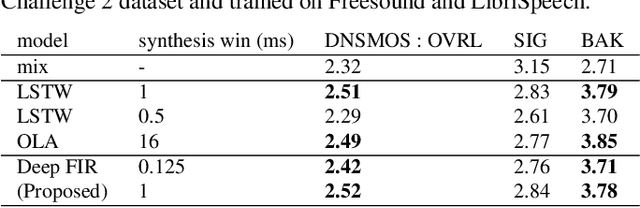
Low latency models are critical for real-time speech enhancement applications, such as hearing aids and hearables. However, the sub-millisecond latency space for resource-constrained hearables remains underexplored. We demonstrate speech enhancement using a computationally efficient minimum-phase FIR filter, enabling sample-by-sample processing to achieve mean algorithmic latency of 0.32 ms to 1.25 ms. With a single microphone, we observe a mean SI-SDRi of 4.1 dB. The approach shows generalization with a DNSMOS increase of 0.2 on unseen audio recordings. We use a lightweight LSTM-based model of 644k parameters to generate FIR taps. We benchmark that our system can run on low-power DSP with 388 MIPS and mean end-to-end latency of 3.35 ms. We provide a comparison with baseline low-latency spectral masking techniques. We hope this work will enable a better understanding of latency and can be used to improve the comfort and usability of hearables.
A Comparison of Deep Learning MOS Predictors for Speech Synthesis Quality
Apr 05, 2022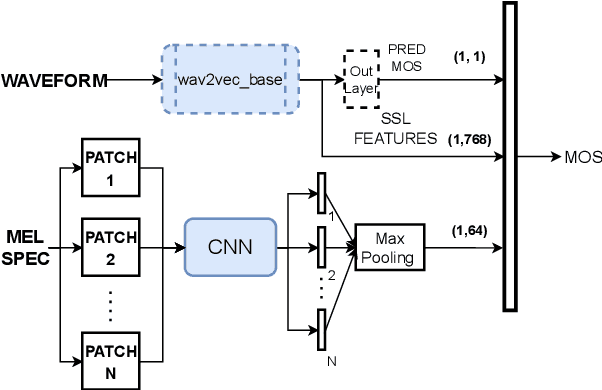
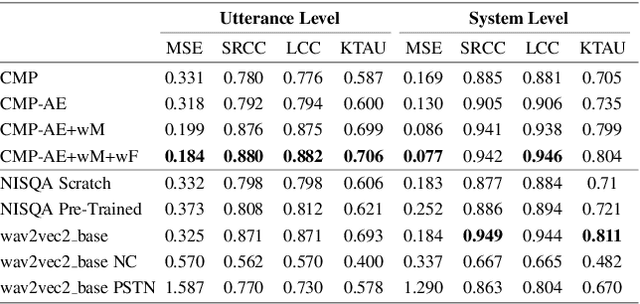
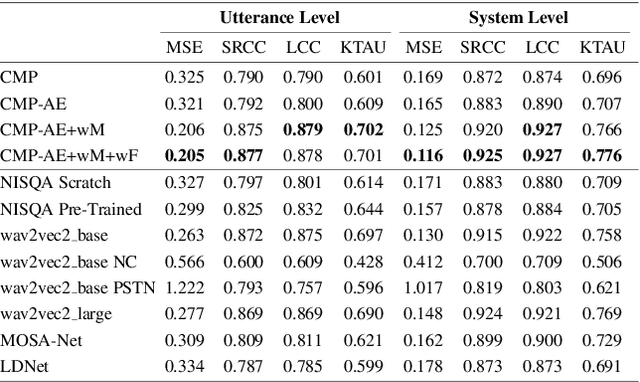
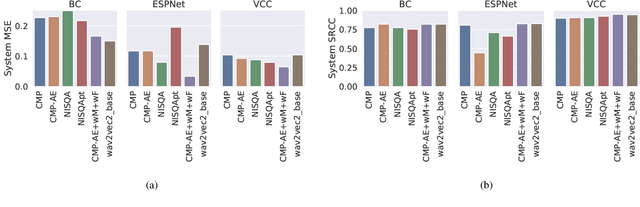
This paper introduces a comparison of deep learning-based techniques for the MOS prediction task of synthesised speech in the Interspeech VoiceMOS challenge. Using the data from the main track of the VoiceMOS challenge we explore both existing predictors and propose new ones. We evaluate two groups of models: NISQA-based models and techniques based on fine-tuning the self-supervised learning (SSL) model wav2vec2_base. Our findings show that a simplified version of NISQA with 40% fewer parameters achieves results close to the original NISQA architecture on both utterance-level and system-level performances. Pre-training NISQA with the NISQA corpus improves utterance-level performance but shows no benefit on the system-level performance. Also, the NISQA-based models perform close to LDNet and MOSANet, 2 out of 3 baselines of the challenge. Fine-tuning wav2vec2_base shows superior performance than the NISQA-based models. We explore the mismatch between natural and synthetic speech and discovered that the performance of the SSL model drops consistently when fine-tuned on natural speech samples. We show that adding CNN features with the SSL model does not improve the baseline performance. Finally, we show that the system type has an impact on the predictions of the non-SSL models.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021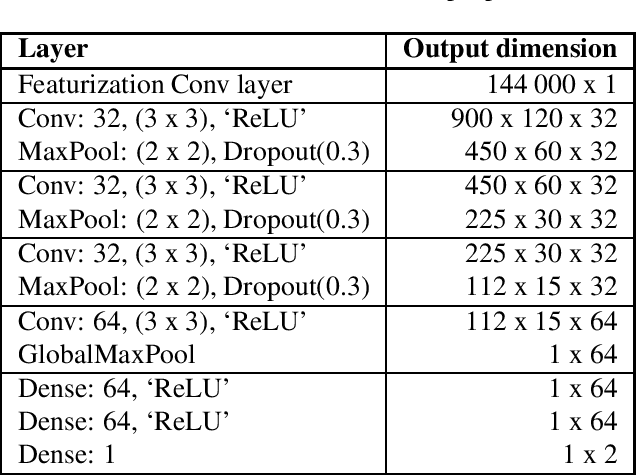
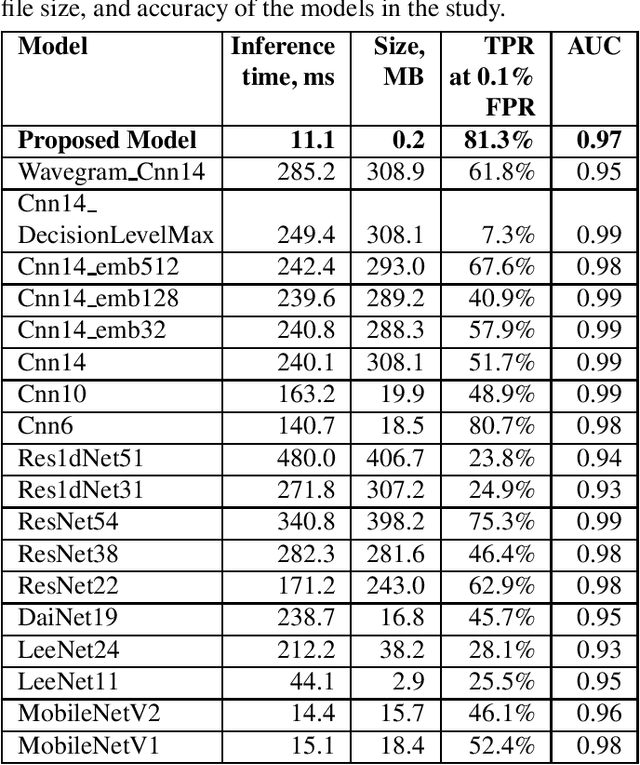
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
Towards efficient models for real-time deep noise suppression
Jan 22, 2021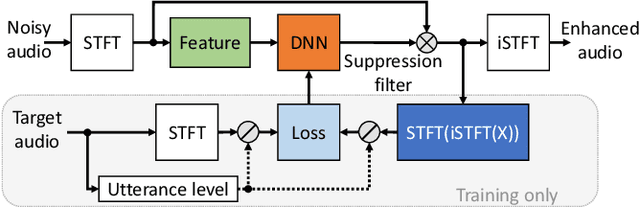

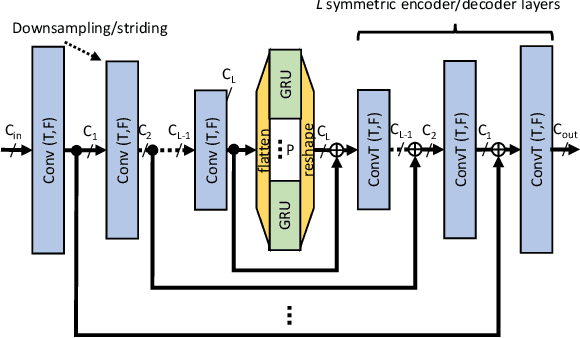
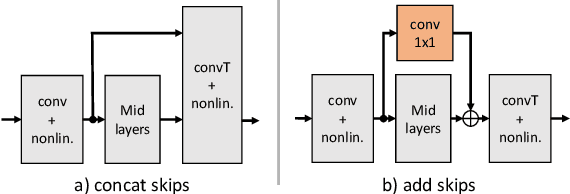
With recent research advancements, deep learning models are becoming attractive and powerful choices for speech enhancement in real-time applications. While state-of-the-art models can achieve outstanding results in terms of speech quality and background noise reduction, the main challenge is to obtain compact enough models, which are resource efficient during inference time. An important but often neglected aspect for data-driven methods is that results can be only convincing when tested on real-world data and evaluated with useful metrics. In this work, we investigate reasonably small recurrent and convolutional-recurrent network architectures for speech enhancement, trained on a large dataset considering also reverberation. We show interesting tradeoffs between computational complexity and the achievable speech quality, measured on real recordings using a highly accurate MOS estimator. It is shown that the achievable speech quality is a function of network complexity, and show which models have better tradeoffs.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results
May 29, 2020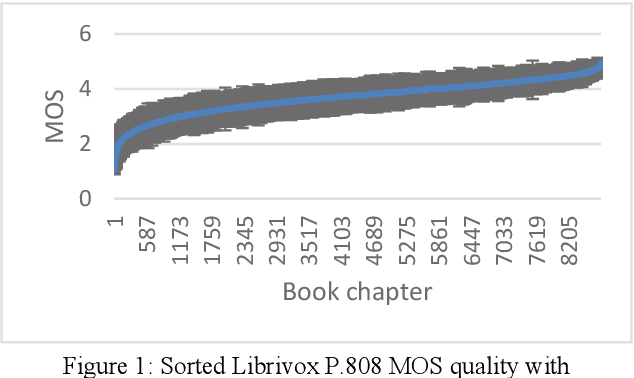

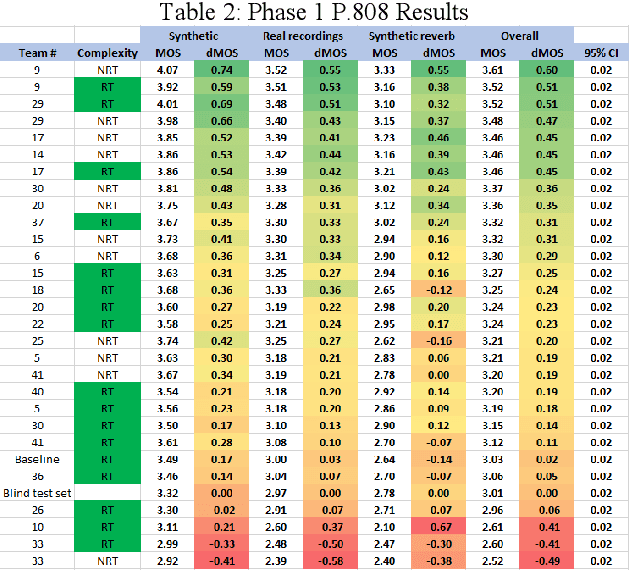
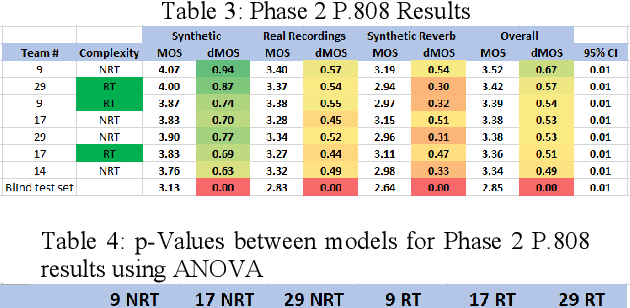
The INTERSPEECH 2020 Deep Noise Suppression (DNS) Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. While the performance is good on the synthetic test set, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-sourced a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open-sourced an online subjective test framework based on ITU-T P.808 for researchers to reliably test their developments. We evaluated the results using P.808 on a blind test set. The results and the key learnings from the challenge are discussed. The datasets and scripts can be found here for quick access https://github.com/microsoft/DNS-Challenge.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
Jan 23, 2020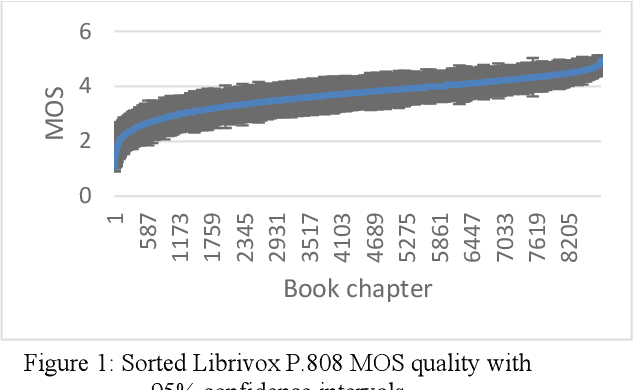

The INTERSPEECH 2020 Deep Noise Suppression Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. Many publications report reasonable performance on the synthetic test set drawn from the same distribution as that of the training set. However, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-source a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open source an online subjective test framework based on ITU-T P.808 for researchers to quickly test their developments. The winners of this challenge will be selected based on subjective evaluation on a representative test set using P.808 framework.