 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards efficient models for real-time deep noise suppression
Paper and Code
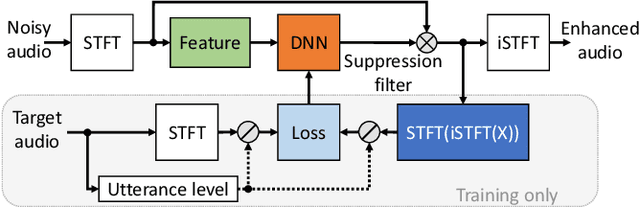

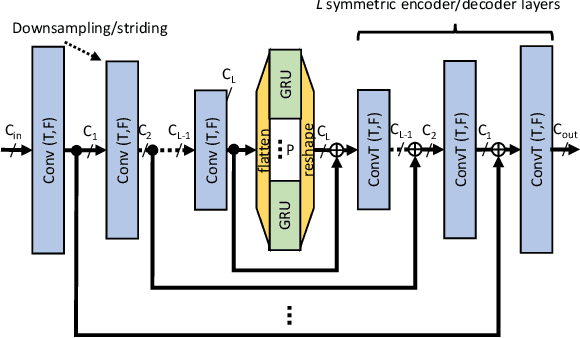
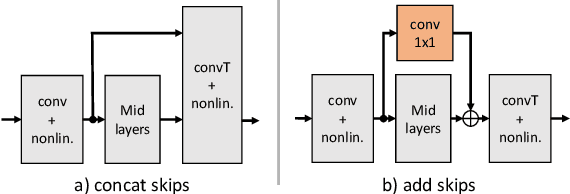
With recent research advancements, deep learning models are becoming attractive and powerful choices for speech enhancement in real-time applications. While state-of-the-art models can achieve outstanding results in terms of speech quality and background noise reduction, the main challenge is to obtain compact enough models, which are resource efficient during inference time. An important but often neglected aspect for data-driven methods is that results can be only convincing when tested on real-world data and evaluated with useful metrics. In this work, we investigate reasonably small recurrent and convolutional-recurrent network architectures for speech enhancement, trained on a large dataset considering also reverberation. We show interesting tradeoffs between computational complexity and the achievable speech quality, measured on real recordings using a highly accurate MOS estimator. It is shown that the achievable speech quality is a function of network complexity, and show which models have better tradeoffs.