 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow complexity online convolutional beamforming
Jul 14, 2021


Convolutional beamformers integrate the multichannel linear prediction model into beamformers, which provide good performance and optimality for joint dereverberation and noise reduction tasks. While longer filters are required to model long reverberation times, the computational burden of current online solutions grows fast with the filter length and number of microphones. In this work, we propose a low complexity convolutional beamformer using a Kalman filter derived affine projection algorithm to solve the adaptive filtering problem. The proposed solution is several orders of magnitude less complex than comparable existing solutions while slightly outperforming them on the REVERB challenge dataset.
On training targets for noise-robust voice activity detection
Feb 15, 2021
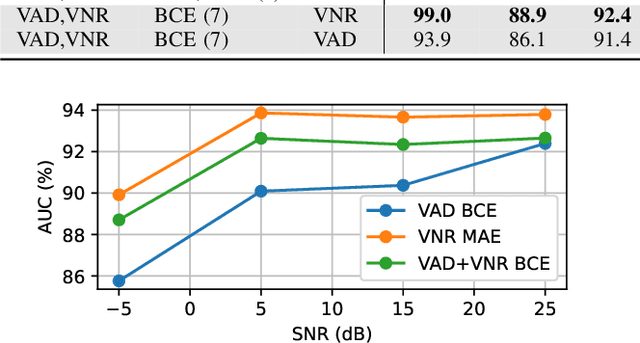
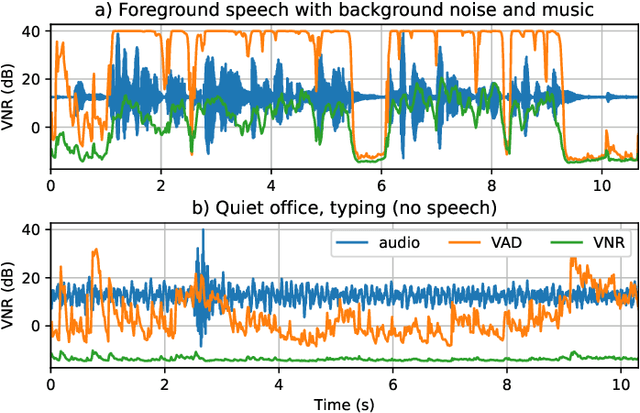

The task of voice activity detection (VAD) is an often required module in various speech processing, analysis and classification tasks. While state-of-the-art neural network based VADs can achieve great results, they often exceed computational budgets and real-time operating requirements. In this work, we propose a computationally efficient real-time VAD network that achieves state-of-the-art results on several public real recording datasets. We investigate different training targets for the VAD and show that using the segmental voice-to-noise ratio (VNR) is a better and more noise-robust training target than the clean speech level based VAD. We also show that multi-target training improves the performance further.
Towards efficient models for real-time deep noise suppression
Jan 22, 2021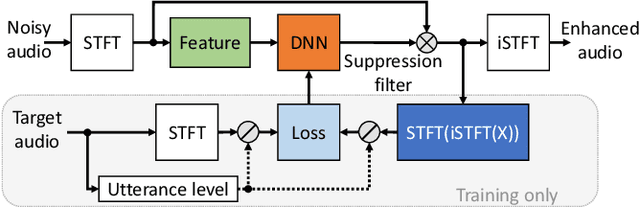

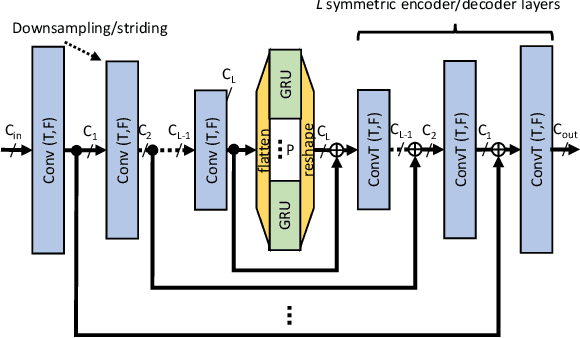
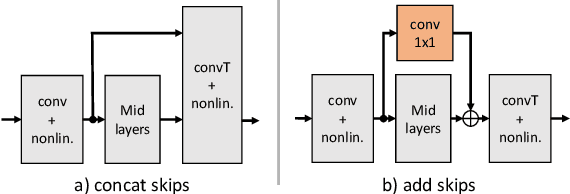
With recent research advancements, deep learning models are becoming attractive and powerful choices for speech enhancement in real-time applications. While state-of-the-art models can achieve outstanding results in terms of speech quality and background noise reduction, the main challenge is to obtain compact enough models, which are resource efficient during inference time. An important but often neglected aspect for data-driven methods is that results can be only convincing when tested on real-world data and evaluated with useful metrics. In this work, we investigate reasonably small recurrent and convolutional-recurrent network architectures for speech enhancement, trained on a large dataset considering also reverberation. We show interesting tradeoffs between computational complexity and the achievable speech quality, measured on real recordings using a highly accurate MOS estimator. It is shown that the achievable speech quality is a function of network complexity, and show which models have better tradeoffs.
Reinforcement Learning To Adapt Speech Enhancement to Instantaneous Input Signal Quality
Jul 27, 2018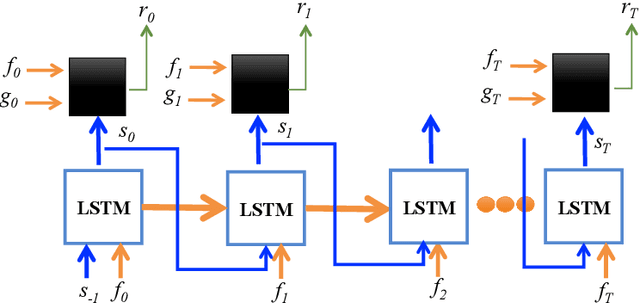
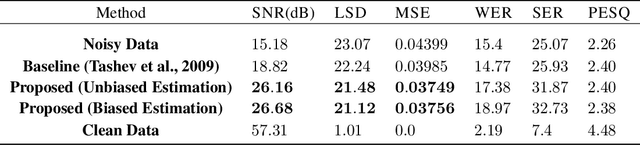
Today, the optimal performance of existing noise-suppression algorithms, both data-driven and those based on classic statistical methods, is range bound to specific levels of instantaneous input signal-to-noise ratios. In this paper, we present a new approach to improve the adaptivity of such algorithms enabling them to perform robustly across a wide range of input signal and noise types. Our methodology is based on the dynamic control of algorithmic parameters via reinforcement learning. Specifically, we model the noise-suppression module as a black box, requiring no knowledge of the algorithmic mechanics except a simple feedback from the output. We utilize this feedback as the reward signal for a reinforcement-learning agent that learns a policy to adapt the algorithmic parameters for every incoming audio frame (16 ms of data). Our preliminary results show that such a control mechanism can substantially increase the overall performance of the underlying noise-suppression algorithm; 42% and 16% improvements in output SNR and MSE, respectively, when compared to no adaptivity.
Convolutional-Recurrent Neural Networks for Speech Enhancement
May 02, 2018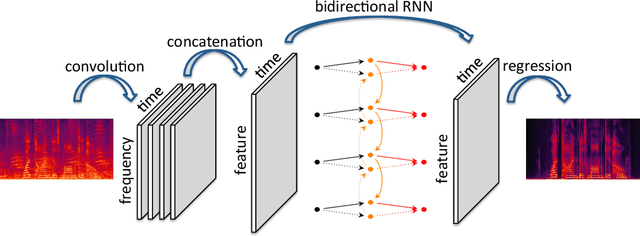
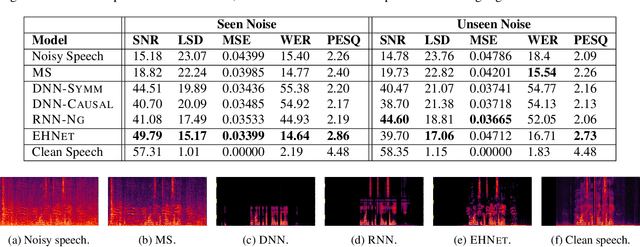
We propose an end-to-end model based on convolutional and recurrent neural networks for speech enhancement. Our model is purely data-driven and does not make any assumptions about the type or the stationarity of the noise. In contrast to existing methods that use multilayer perceptrons (MLPs), we employ both convolutional and recurrent neural network architectures. Thus, our approach allows us to exploit local structures in both the frequency and temporal domains. By incorporating prior knowledge of speech signals into the design of model structures, we build a model that is more data-efficient and achieves better generalization on both seen and unseen noise. Based on experiments with synthetic data, we demonstrate that our model outperforms existing methods, improving PESQ by up to 0.6 on seen noise and 0.64 on unseen noise.
Constrained Convolutional-Recurrent Networks to Improve Speech Quality with Low Impact on Recognition Accuracy
Feb 16, 2018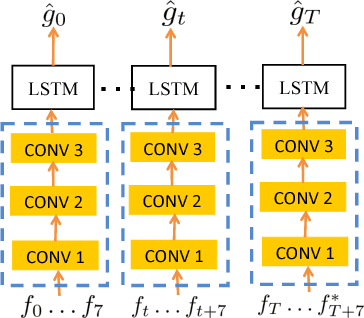
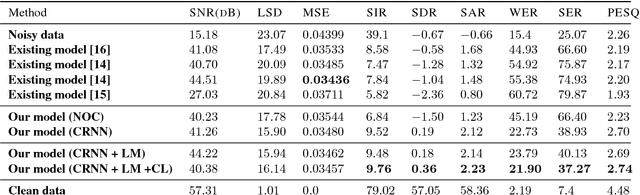
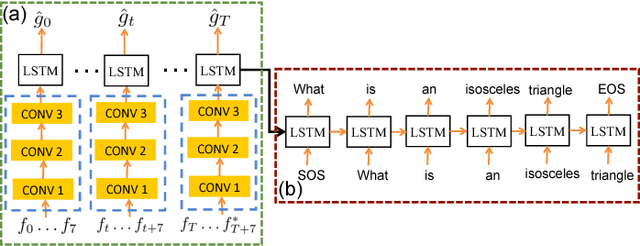

For a speech-enhancement algorithm, it is highly desirable to simultaneously improve perceptual quality and recognition rate. Thanks to computational costs and model complexities, it is challenging to train a model that effectively optimizes both metrics at the same time. In this paper, we propose a method for speech enhancement that combines local and global contextual structures information through convolutional-recurrent neural networks that improves perceptual quality. At the same time, we introduce a new constraint on the objective function using a language model/decoder that limits the impact on recognition rate. Based on experiments conducted with real user data, we demonstrate that our new context-augmented machine-learning approach for speech enhancement improves PESQ and WER by an additional 24.5% and 51.3%, respectively, when compared to the best-performing methods in the literature.