 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning To Adapt Speech Enhancement to Instantaneous Input Signal Quality
Jul 27, 2018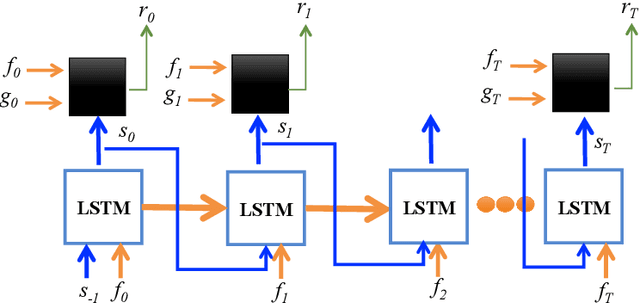
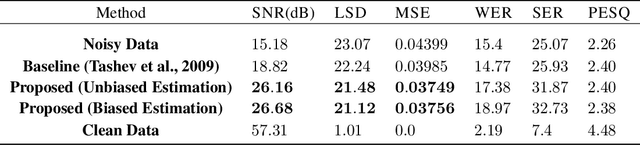
Today, the optimal performance of existing noise-suppression algorithms, both data-driven and those based on classic statistical methods, is range bound to specific levels of instantaneous input signal-to-noise ratios. In this paper, we present a new approach to improve the adaptivity of such algorithms enabling them to perform robustly across a wide range of input signal and noise types. Our methodology is based on the dynamic control of algorithmic parameters via reinforcement learning. Specifically, we model the noise-suppression module as a black box, requiring no knowledge of the algorithmic mechanics except a simple feedback from the output. We utilize this feedback as the reward signal for a reinforcement-learning agent that learns a policy to adapt the algorithmic parameters for every incoming audio frame (16 ms of data). Our preliminary results show that such a control mechanism can substantially increase the overall performance of the underlying noise-suppression algorithm; 42% and 16% improvements in output SNR and MSE, respectively, when compared to no adaptivity.
Convolutional-Recurrent Neural Networks for Speech Enhancement
May 02, 2018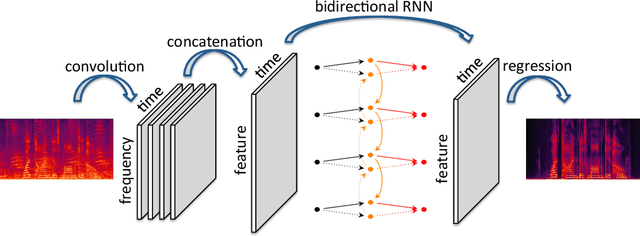
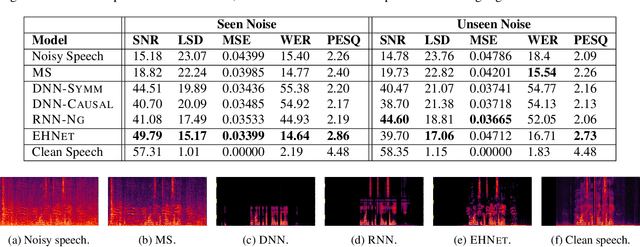
We propose an end-to-end model based on convolutional and recurrent neural networks for speech enhancement. Our model is purely data-driven and does not make any assumptions about the type or the stationarity of the noise. In contrast to existing methods that use multilayer perceptrons (MLPs), we employ both convolutional and recurrent neural network architectures. Thus, our approach allows us to exploit local structures in both the frequency and temporal domains. By incorporating prior knowledge of speech signals into the design of model structures, we build a model that is more data-efficient and achieves better generalization on both seen and unseen noise. Based on experiments with synthetic data, we demonstrate that our model outperforms existing methods, improving PESQ by up to 0.6 on seen noise and 0.64 on unseen noise.
Constrained Convolutional-Recurrent Networks to Improve Speech Quality with Low Impact on Recognition Accuracy
Feb 16, 2018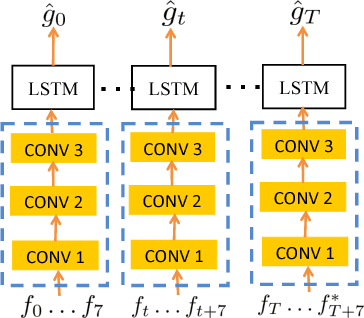
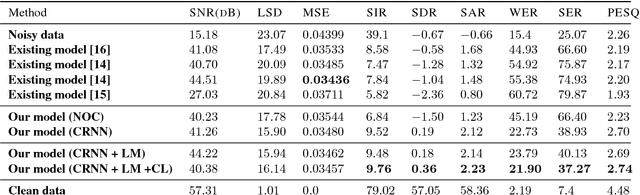
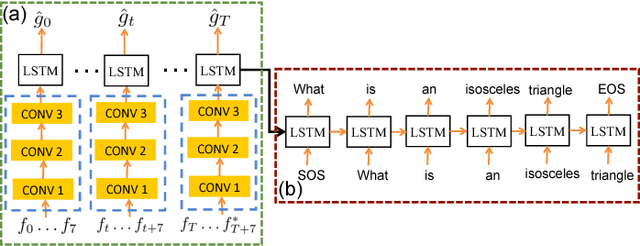

For a speech-enhancement algorithm, it is highly desirable to simultaneously improve perceptual quality and recognition rate. Thanks to computational costs and model complexities, it is challenging to train a model that effectively optimizes both metrics at the same time. In this paper, we propose a method for speech enhancement that combines local and global contextual structures information through convolutional-recurrent neural networks that improves perceptual quality. At the same time, we introduce a new constraint on the objective function using a language model/decoder that limits the impact on recognition rate. Based on experiments conducted with real user data, we demonstrate that our new context-augmented machine-learning approach for speech enhancement improves PESQ and WER by an additional 24.5% and 51.3%, respectively, when compared to the best-performing methods in the literature.