 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Convolutional-Recurrent Networks to Improve Speech Quality with Low Impact on Recognition Accuracy
Paper and Code
Feb 16, 2018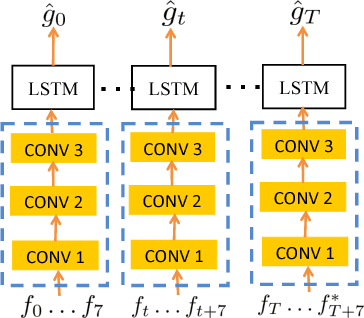
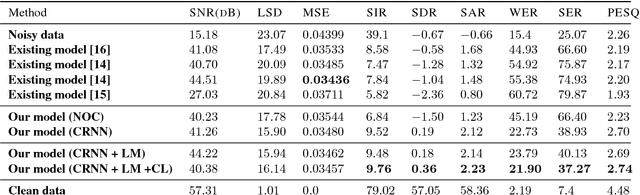
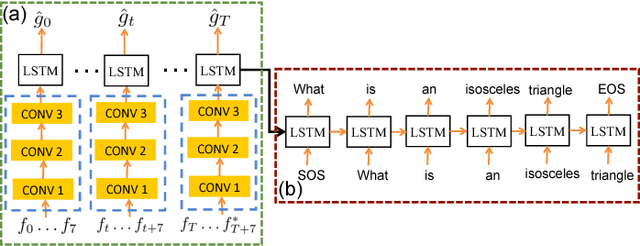

For a speech-enhancement algorithm, it is highly desirable to simultaneously improve perceptual quality and recognition rate. Thanks to computational costs and model complexities, it is challenging to train a model that effectively optimizes both metrics at the same time. In this paper, we propose a method for speech enhancement that combines local and global contextual structures information through convolutional-recurrent neural networks that improves perceptual quality. At the same time, we introduce a new constraint on the objective function using a language model/decoder that limits the impact on recognition rate. Based on experiments conducted with real user data, we demonstrate that our new context-augmented machine-learning approach for speech enhancement improves PESQ and WER by an additional 24.5% and 51.3%, respectively, when compared to the best-performing methods in the literature.