 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023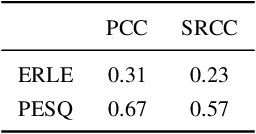
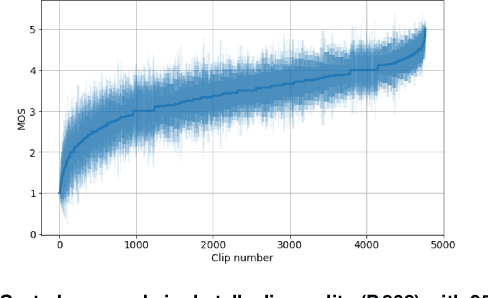

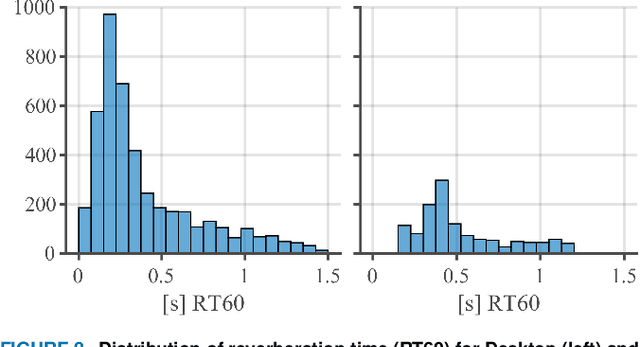
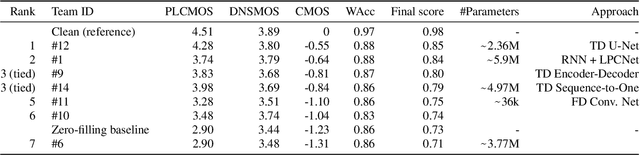
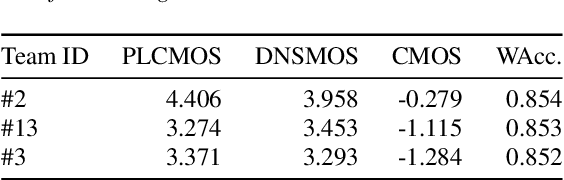
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
INTERSPEECH 2022 Audio Deep Packet Loss Concealment Challenge
Apr 11, 2022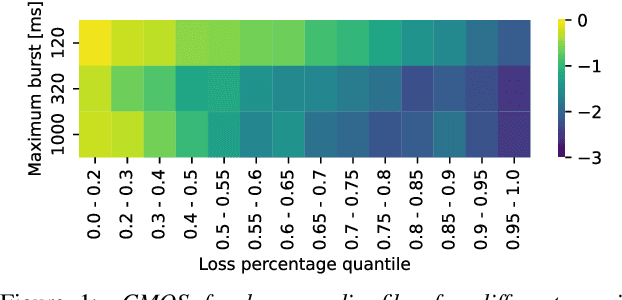
Audio Packet Loss Concealment (PLC) is the hiding of gaps in audio streams caused by data transmission failures in packet switched networks. This is a common problem, and of increasing importance as end-to-end VoIP telephony and teleconference systems become the default and ever more widely used form of communication in business as well as in personal usage. This paper presents the INTERSPEECH 2022 Audio Deep Packet Loss Concealment challenge. We first give an overview of the PLC problem, and introduce some classical approaches to PLC as well as recent work. We then present the open source dataset released as part of this challenge as well as the evaluation methods and metrics used to determine the winner. We also briefly introduce PLCMOS, a novel data-driven metric that can be used to quickly evaluate the performance PLC systems. Finally, we present the results of the INTERSPEECH 2022 Audio Deep PLC Challenge, and provide a summary of important takeaways.
ICASSP 2022 Acoustic Echo Cancellation Challenge
Feb 27, 2022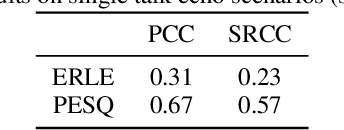
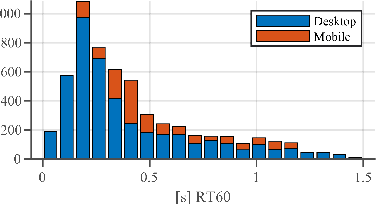
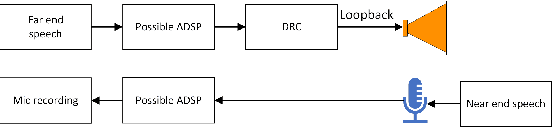

The ICASSP 2022 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and still a top issue in audio communication. This is the third AEC challenge and it is enhanced by including mobile scenarios, adding speech recognition rate in the challenge goal metrics, and making the default sample rate 48 kHz. In this challenge, we open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We also open source an online subjective test framework and provide an online objective metric service for researchers to quickly test their results. The winners of this challenge are selected based on the average Mean Opinion Score achieved across all different single talk and double talk scenarios, and the speech recognition word acceptance rate.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022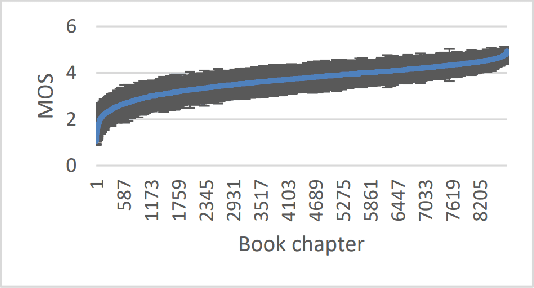
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.
MusicNet: Compact Convolutional Neural Network for Real-time Background Music Detection
Oct 08, 2021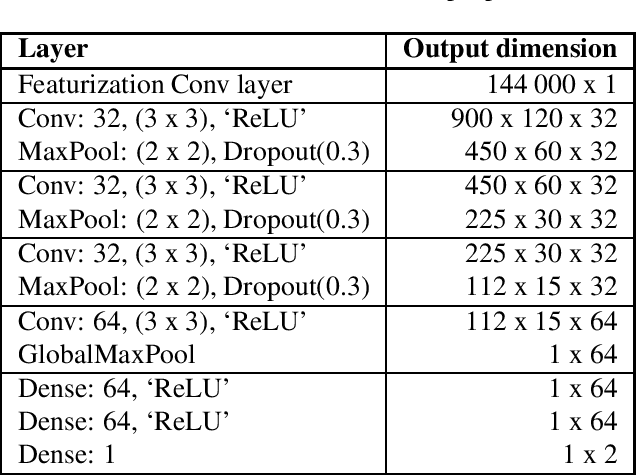
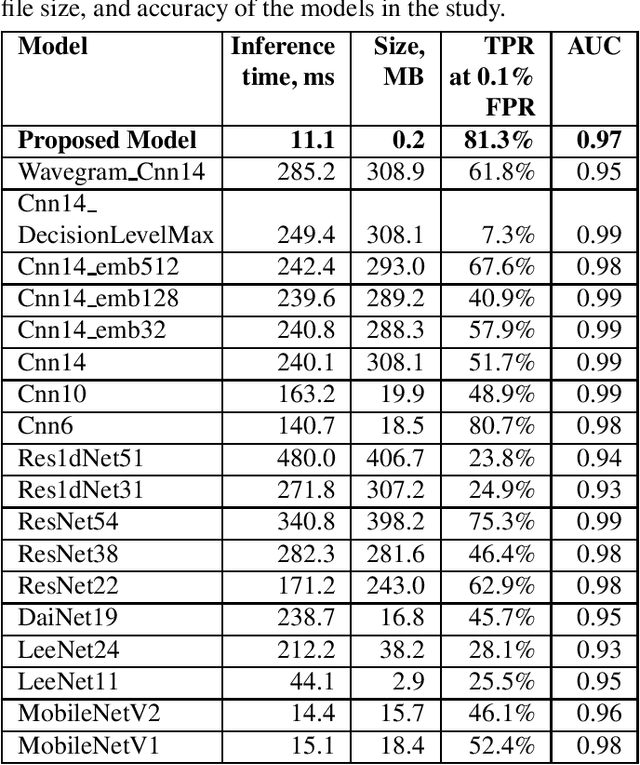
With the recent growth of remote and hybrid work, online meetings often encounter challenging audio contexts such as background noise, music, and echo. Accurate real-time detection of music events can help to improve the user experience in such scenarios, e.g., by switching to high-fidelity music-specific codec or selecting the optimal noise suppression model. In this paper, we present MusicNet -- a compact high-performance model for detecting background music in the real-time communications pipeline. In online video meetings, which is our main use case, music almost always co-occurs with speech and background noises, making the accurate classification quite challenging. The proposed model is a binary classifier that consists of a compact convolutional neural network core preceded by an in-model featurization layer. It takes 9 seconds of raw audio as input and does not require any model-specific featurization on the client. We train our model on a balanced subset of the AudioSet data and use 1000 crowd-sourced real test clips to validate the model. Finally, we compare MusicNet performance to 20 other state-of-the-art models. Our classifier gives a true positive rate of 81.3% at a 0.1% false positive rate, which is significantly better than any other model in the study. Our model is also 10x smaller and has 4x faster inference than the comparable baseline.
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021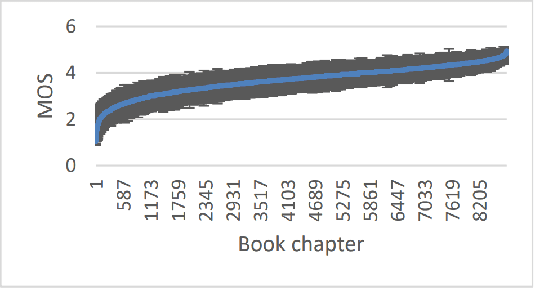
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results
May 29, 2020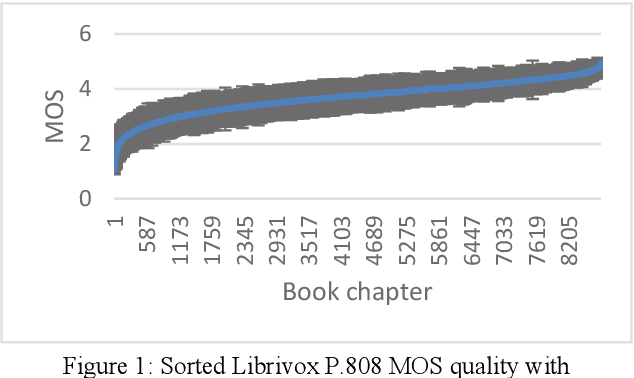

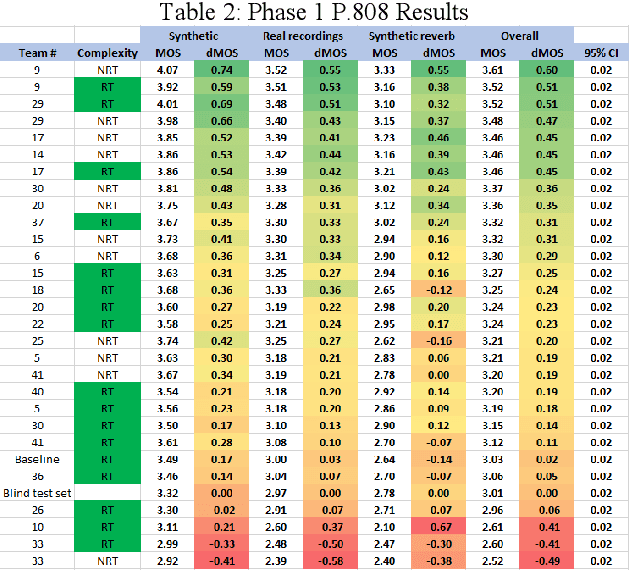
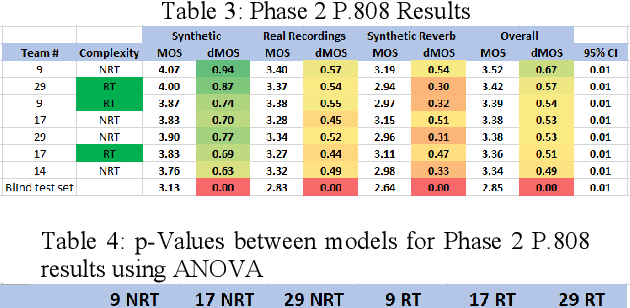
The INTERSPEECH 2020 Deep Noise Suppression (DNS) Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. While the performance is good on the synthetic test set, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-sourced a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open-sourced an online subjective test framework based on ITU-T P.808 for researchers to reliably test their developments. We evaluated the results using P.808 on a blind test set. The results and the key learnings from the challenge are discussed. The datasets and scripts can be found here for quick access https://github.com/microsoft/DNS-Challenge.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
Jan 23, 2020

The INTERSPEECH 2020 Deep Noise Suppression Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. Many publications report reasonable performance on the synthetic test set drawn from the same distribution as that of the training set. However, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-source a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open source an online subjective test framework based on ITU-T P.808 for researchers to quickly test their developments. The winners of this challenge will be selected based on subjective evaluation on a representative test set using P.808 framework.