 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023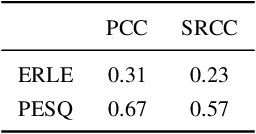
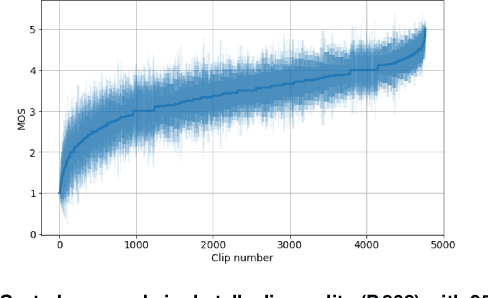

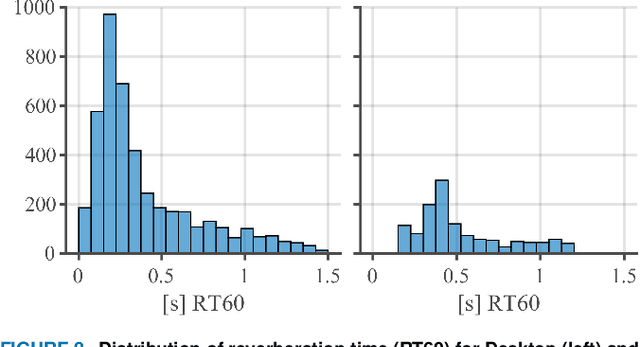
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
DeepVQE: Real Time Deep Voice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation
Jun 05, 2023


Acoustic echo cancellation (AEC), noise suppression (NS) and dereverberation (DR) are an integral part of modern full-duplex communication systems. As the demand for teleconferencing systems increases, addressing these tasks is required for an effective and efficient online meeting experience. Most prior research proposes solutions for these tasks separately, combining them with digital signal processing (DSP) based components, resulting in complex pipelines that are often impractical to deploy in real-world applications. This paper proposes a real-time cross-attention deep model, named DeepVQE, based on residual convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to simultaneously address AEC, NS, and DR. We conduct several ablation studies to analyze the contributions of different components of our model to the overall performance. DeepVQE achieves state-of-the-art performance on non-personalized tracks from the ICASSP 2023 Acoustic Echo Cancellation Challenge and ICASSP 2023 Deep Noise Suppression Challenge test sets, showing that a single model can handle multiple tasks with excellent performance. Moreover, the model runs in real-time and has been successfully tested for the Microsoft Teams platform.
Deep model with built-in self-attention alignment for acoustic echo cancellation
Aug 24, 2022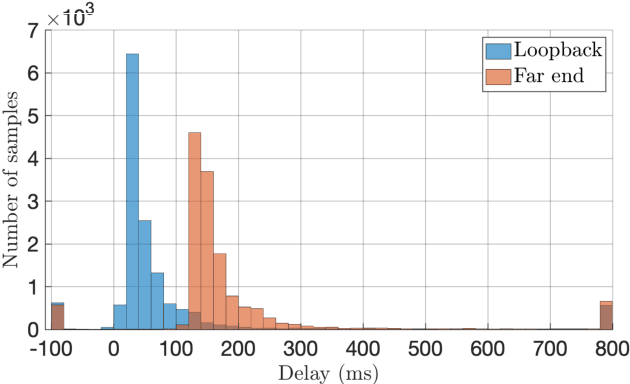

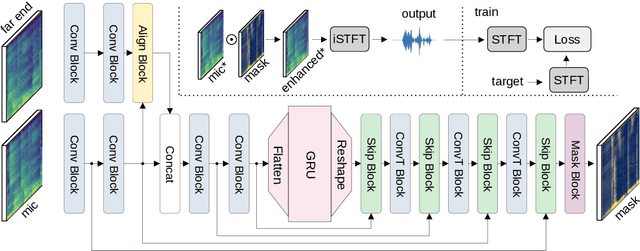
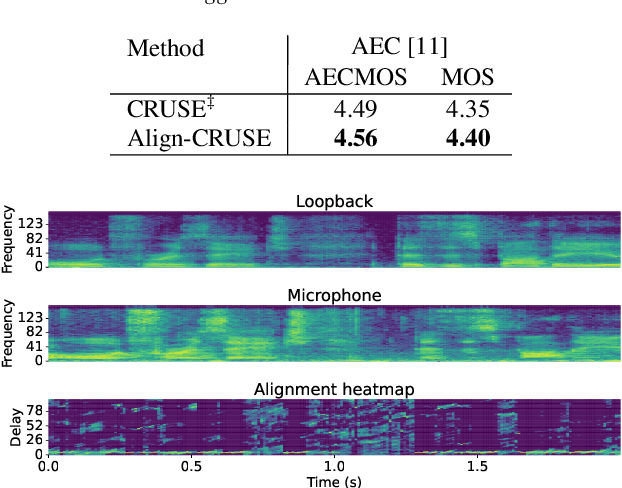
With recent research advances, deep learning models have become an attractive choice for acoustic echo cancellation (AEC) in real-time teleconferencing applications. Since acoustic echo is one of the major sources of poor audio quality, a wide variety of deep models have been proposed. However, an important but often omitted requirement for good echo cancellation quality is the synchronization of the microphone and far end signals. Typically implemented using classical algorithms based on cross-correlation, the alignment module is a separate functional block with known design limitations. In our work we propose a deep learning architecture with built-in self-attention based alignment, which is able to handle unaligned inputs, improving echo cancellation performance while simplifying the communication pipeline. Moreover, we show that our approach achieves significant improvements for difficult delay estimation cases on real recordings from AEC Challenge data set.