 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Speech Enhancement Without a Separate Speaker Embedding Model
Jun 14, 2024


Personalized speech enhancement (PSE) models can improve the audio quality of teleconferencing systems by adapting to the characteristics of a speaker's voice. However, most existing methods require a separate speaker embedding model to extract a vector representation of the speaker from enrollment audio, which adds complexity to the training and deployment process. We propose to use the internal representation of the PSE model itself as the speaker embedding, thereby avoiding the need for a separate model. We show that our approach performs equally well or better than the standard method of using a pre-trained speaker embedding model on noise suppression and echo cancellation tasks. Moreover, our approach surpasses the ICASSP 2023 Deep Noise Suppression Challenge winner by 0.15 in Mean Opinion Score.
Deep model with built-in self-attention alignment for acoustic echo cancellation
Aug 24, 2022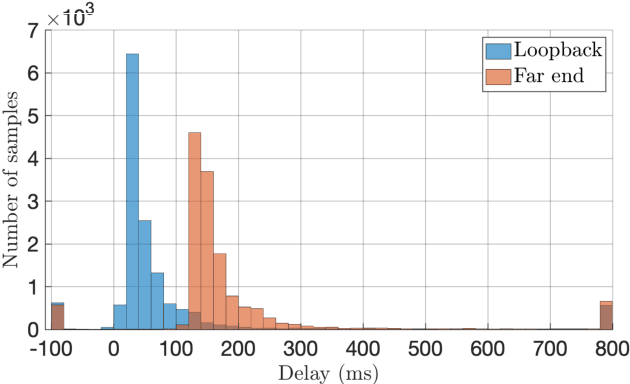

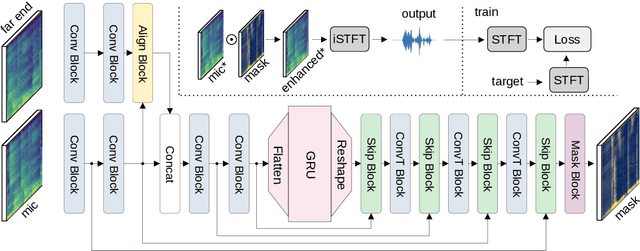
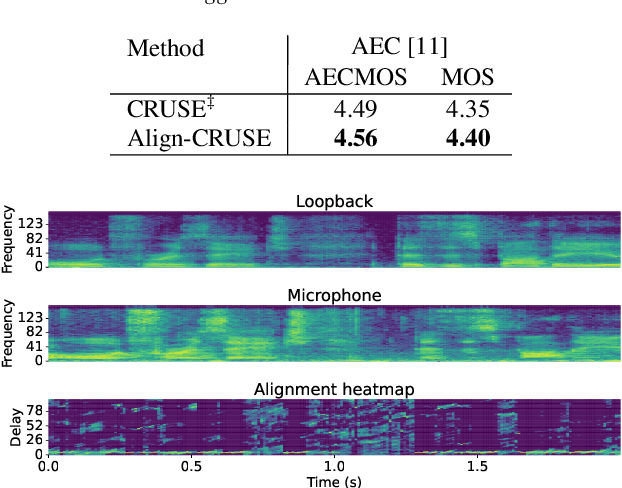
With recent research advances, deep learning models have become an attractive choice for acoustic echo cancellation (AEC) in real-time teleconferencing applications. Since acoustic echo is one of the major sources of poor audio quality, a wide variety of deep models have been proposed. However, an important but often omitted requirement for good echo cancellation quality is the synchronization of the microphone and far end signals. Typically implemented using classical algorithms based on cross-correlation, the alignment module is a separate functional block with known design limitations. In our work we propose a deep learning architecture with built-in self-attention based alignment, which is able to handle unaligned inputs, improving echo cancellation performance while simplifying the communication pipeline. Moreover, we show that our approach achieves significant improvements for difficult delay estimation cases on real recordings from AEC Challenge data set.
A Neural Knowledge Language Model
Mar 02, 2017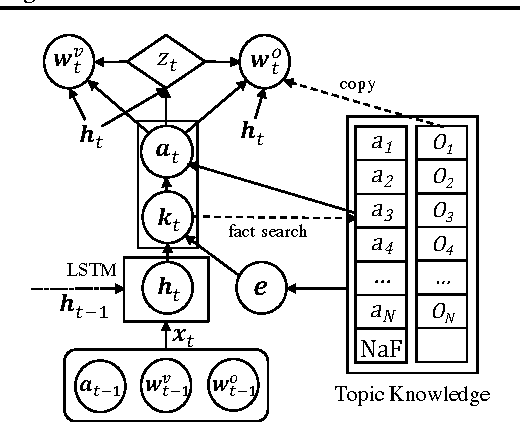

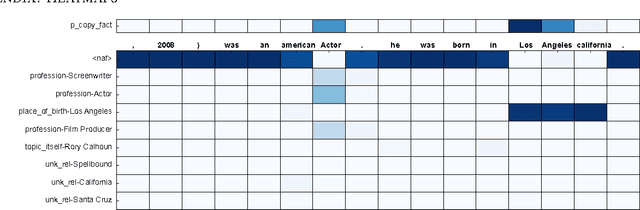

Current language models have a significant limitation in the ability to encode and decode factual knowledge. This is mainly because they acquire such knowledge from statistical co-occurrences although most of the knowledge words are rarely observed. In this paper, we propose a Neural Knowledge Language Model (NKLM) which combines symbolic knowledge provided by the knowledge graph with the RNN language model. By predicting whether the word to generate has an underlying fact or not, the model can generate such knowledge-related words by copying from the description of the predicted fact. In experiments, we show that the NKLM significantly improves the performance while generating a much smaller number of unknown words.