 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2023 Speech Signal Improvement Challenge
Apr 02, 2023The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background and overall quality is impressive, but the improvement in the speech signal is statistically zero. To improve the speech signal the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.80's listening phase . The results show significant improvement was made across all measured dimensions of speech quality.
Guided Unsupervised Learning by Subaperture Decomposition for Ocean SAR Image Retrieval
Sep 29, 2022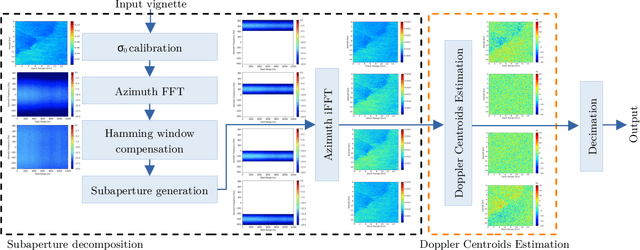
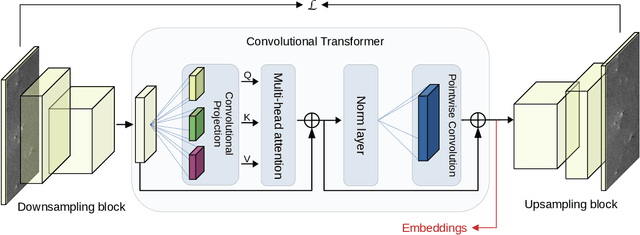
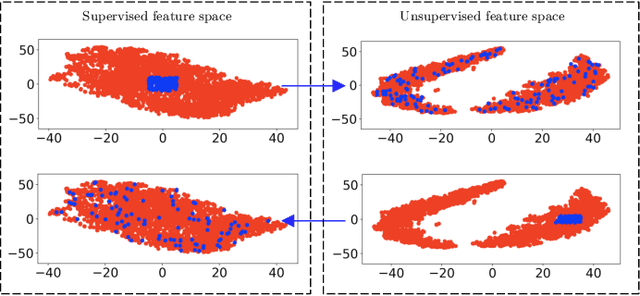
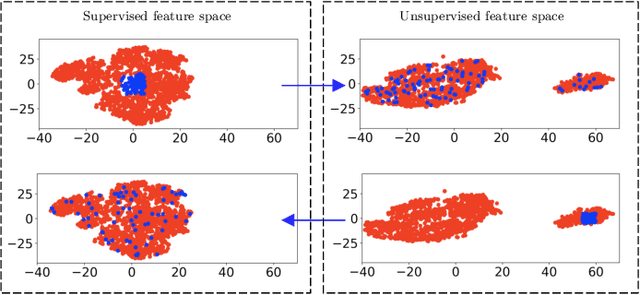
Spaceborne synthetic aperture radar (SAR) can provide accurate images of the ocean surface roughness day-or-night in nearly all weather conditions, being an unique asset for many geophysical applications. Considering the huge amount of data daily acquired by satellites, automated techniques for physical features extraction are needed. Even if supervised deep learning methods attain state-of-the-art results, they require great amount of labeled data, which are difficult and excessively expensive to acquire for ocean SAR imagery. To this end, we use the subaperture decomposition (SD) algorithm to enhance the unsupervised learning retrieval on the ocean surface, empowering ocean researchers to search into large ocean databases. We empirically prove that SD improve the retrieval precision with over 20% for an unsupervised transformer auto-encoder network. Moreover, we show that SD brings important performance boost when Doppler centroid images are used as input data, leading the way to new unsupervised physics guided retrieval algorithms.
Deep model with built-in self-attention alignment for acoustic echo cancellation
Aug 24, 2022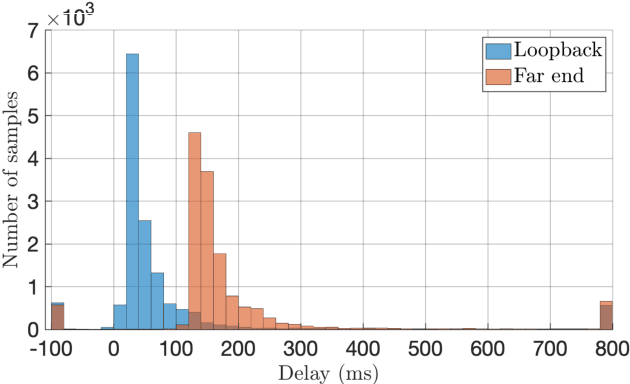

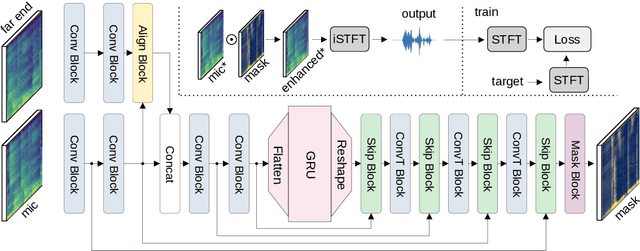
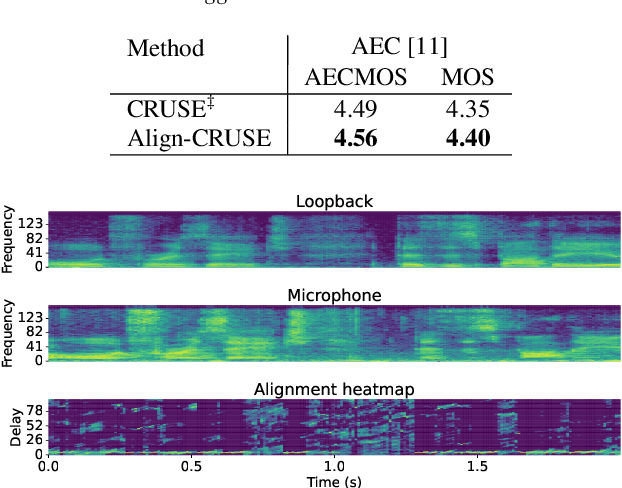
With recent research advances, deep learning models have become an attractive choice for acoustic echo cancellation (AEC) in real-time teleconferencing applications. Since acoustic echo is one of the major sources of poor audio quality, a wide variety of deep models have been proposed. However, an important but often omitted requirement for good echo cancellation quality is the synchronization of the microphone and far end signals. Typically implemented using classical algorithms based on cross-correlation, the alignment module is a separate functional block with known design limitations. In our work we propose a deep learning architecture with built-in self-attention based alignment, which is able to handle unaligned inputs, improving echo cancellation performance while simplifying the communication pipeline. Moreover, we show that our approach achieves significant improvements for difficult delay estimation cases on real recordings from AEC Challenge data set.
Automotive Radar Interference Mitigation with Unfolded Robust PCA based on Residual Overcomplete Auto-Encoder Blocks
Oct 14, 2020
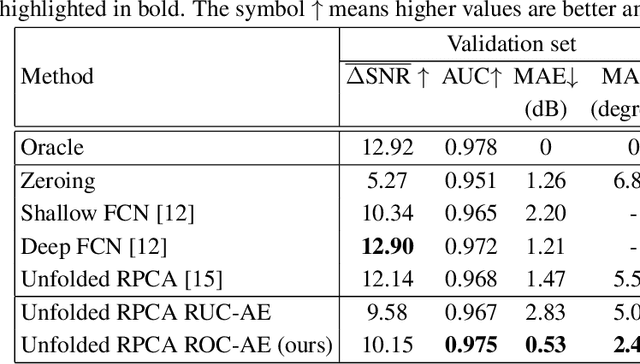


Deep learning methods for automotive radar interference mitigation can succesfully estimate the amplitude of targets, but fail to recover the phase of the respective targets. In this paper, we propose an efficient and effective technique based on unfolded robust Principal Component Analysis (RPCA) that is able to estimate both amplitude and phase in the presence of interference. Our contribution consists in introducing residual overcomplete auto-encoder (ROC-AE) blocks into the recurrent architecture of unfolded RPCA, which results in a deeper model that significantly outperforms unfolded RPCA as well as other deep learning models.
Estimating Magnitude and Phase of Automotive Radar Signals under Multiple Interference Sources with Fully Convolutional Networks
Aug 11, 2020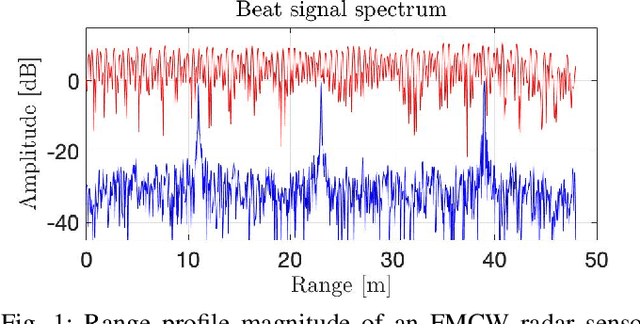
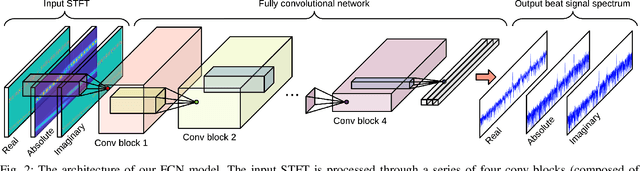
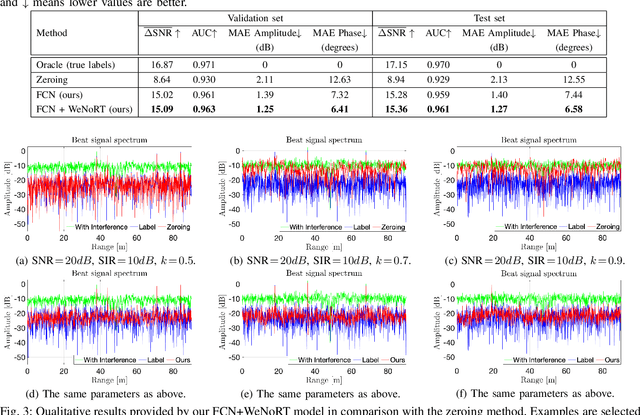
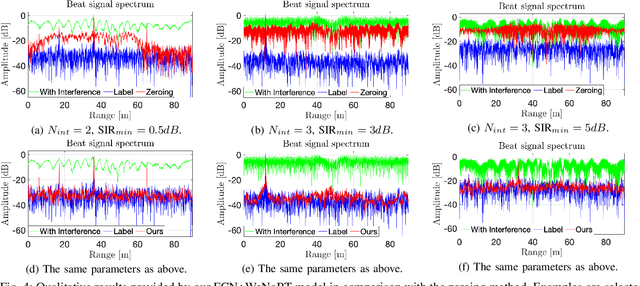
Radar sensors are gradually becoming a wide-spread equipment for road vehicles, playing a crucial role in autonomous driving and road safety. The broad adoption of radar sensors increases the chance of interference among sensors from different vehicles, generating corrupted range profiles and range-Doppler maps. In order to extract distance and velocity of multiple targets from range-Doppler maps, the interference affecting each range profile needs to be mitigated. In this paper, we propose a fully convolutional neural network for automotive radar interference mitigation. In order to train our network in a real-world scenario, we introduce a new data set of realistic automotive radar signals with multiple targets and multiple interferers. To our knowledge, this is the first work to mitigate interference from multiple sources. Furthermore, we introduce a new training regime that eliminates noisy weights, showing superior results compared to the widely-used dropout. While some previous works successfully estimated the magnitude of automotive radar signals, we are the first to propose a deep learning model that can accurately estimate the phase. For instance, our novel approach reduces the phase estimation error with respect to the commonly-adopted zeroing technique by half, from 12.55 degrees to 6.58 degrees. Considering the lack of databases for automotive radar interference mitigation, we release as open source our large-scale data set that closely replicates the real-world automotive scenario for multiple interference cases, allowing others to objectively compare their future work in this domain. Our data set is available for download at: http://github.com/ristea/arim-v2.
Are you wearing a mask? Improving mask detection from speech using augmentation by cycle-consistent GANs
Jun 17, 2020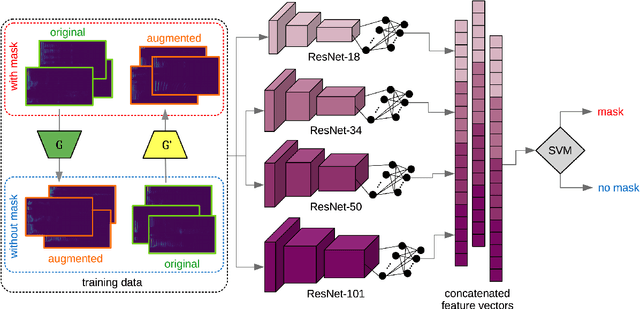
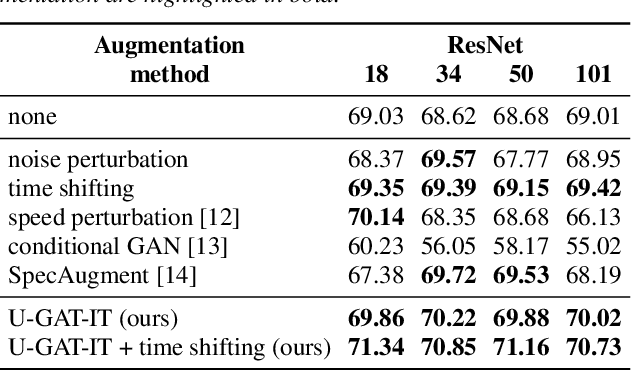
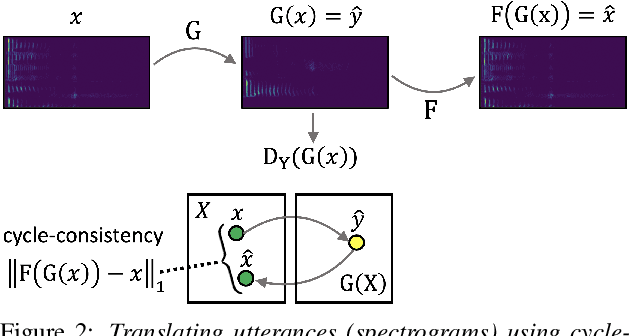

The task of detecting whether a person wears a face mask from speech is useful in modelling speech in forensic investigations, communication between surgeons or people protecting themselves against infectious diseases such as COVID-19. In this paper, we propose a novel data augmentation approach for mask detection from speech. Our approach is based on (i) training Generative Adversarial Networks (GANs) with cycle-consistency loss to translate unpaired utterances between two classes (with mask and without mask), and on (ii) generating new training utterances using the cycle-consistent GANs, assigning opposite labels to each translated utterance. Original and translated utterances are converted into spectrograms which are provided as input to a set of ResNet neural networks with various depths. The networks are combined into an ensemble through a Support Vector Machines (SVM) classifier. With this system, we participated in the Mask Sub-Challenge (MSC) of the INTERSPEECH 2020 Computational Paralinguistics Challenge, surpassing the baseline proposed by the organizers by 2.8%. Our data augmentation technique provided a performance boost of 0.9% on the private test set. Furthermore, we show that our data augmentation approach yields better results than other baseline and state-of-the-art augmentation methods.