 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023
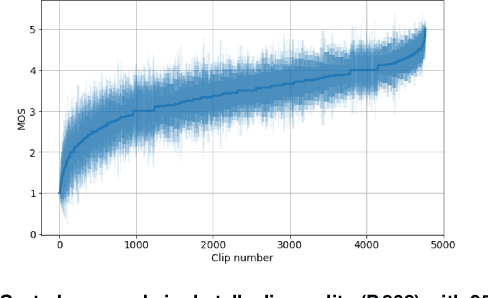

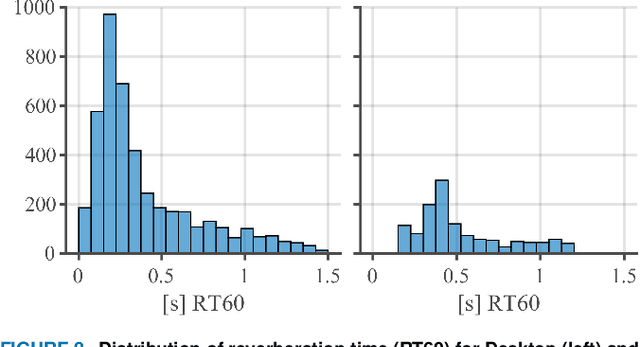
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
DeepVQE: Real Time Deep Voice Quality Enhancement for Joint Acoustic Echo Cancellation, Noise Suppression and Dereverberation
Jun 05, 2023


Acoustic echo cancellation (AEC), noise suppression (NS) and dereverberation (DR) are an integral part of modern full-duplex communication systems. As the demand for teleconferencing systems increases, addressing these tasks is required for an effective and efficient online meeting experience. Most prior research proposes solutions for these tasks separately, combining them with digital signal processing (DSP) based components, resulting in complex pipelines that are often impractical to deploy in real-world applications. This paper proposes a real-time cross-attention deep model, named DeepVQE, based on residual convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to simultaneously address AEC, NS, and DR. We conduct several ablation studies to analyze the contributions of different components of our model to the overall performance. DeepVQE achieves state-of-the-art performance on non-personalized tracks from the ICASSP 2023 Acoustic Echo Cancellation Challenge and ICASSP 2023 Deep Noise Suppression Challenge test sets, showing that a single model can handle multiple tasks with excellent performance. Moreover, the model runs in real-time and has been successfully tested for the Microsoft Teams platform.
Real-Time Joint Personalized Speech Enhancement and Acoustic Echo Cancellation with E3Net
Nov 04, 2022


Personalized speech enhancement (PSE), a process of estimating a clean target speech signal in real time by leveraging a speaker embedding vector of the target talker, has garnered much attention from the research community due to the recent surge of online meetings across the globe. For practical full duplex communication, PSE models require an acoustic echo cancellation (AEC) capability. In this work, we employ a recently proposed causal end-to-end enhancement network (E3Net) and modify it to obtain a joint PSE-AEC model. We dedicate the early layers to the AEC task while encouraging later layers for personalization by adding a bypass connection from the early layers to the mask prediction layer. This allows us to employ a multi-task learning framework for joint PSE and AEC training. We provide extensive evaluation test scenarios with both simulated and real-world recordings. The results show that our joint model comes close to the expert models for each task and performs significantly better for the combined PSE-AEC scenario.
ICASSP 2022 Acoustic Echo Cancellation Challenge
Feb 27, 2022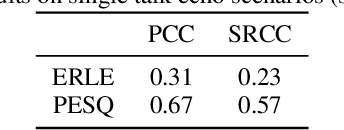
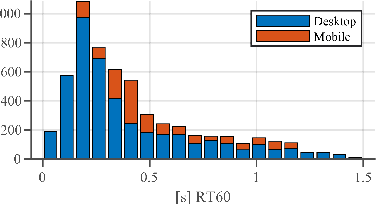
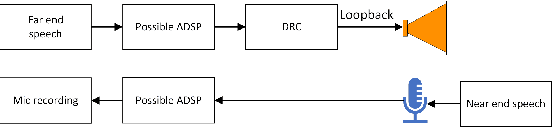

The ICASSP 2022 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and still a top issue in audio communication. This is the third AEC challenge and it is enhanced by including mobile scenarios, adding speech recognition rate in the challenge goal metrics, and making the default sample rate 48 kHz. In this challenge, we open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We also open source an online subjective test framework and provide an online objective metric service for researchers to quickly test their results. The winners of this challenge are selected based on the average Mean Opinion Score achieved across all different single talk and double talk scenarios, and the speech recognition word acceptance rate.