 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Sep 14, 2022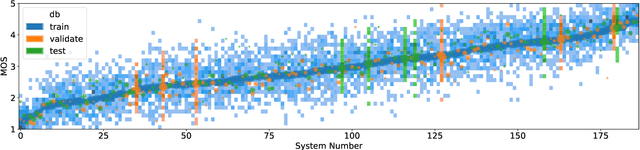
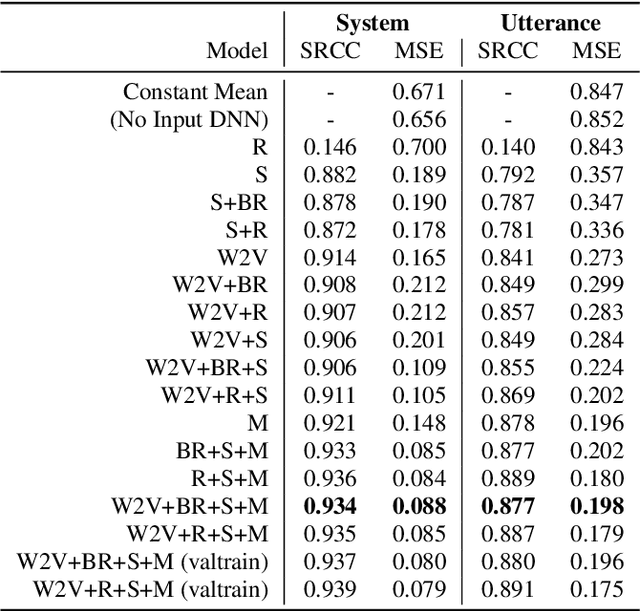
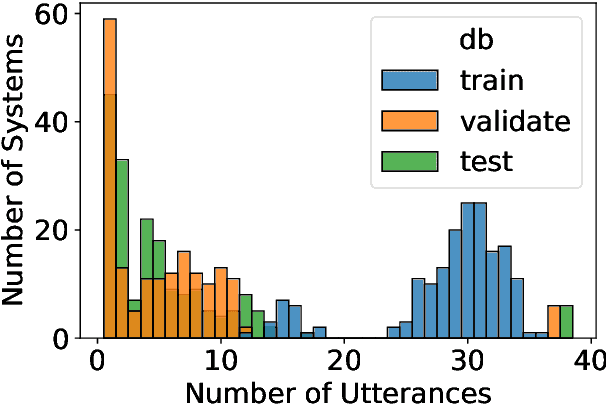
Non-reference speech quality models are important for a growing number of applications. The VoiceMOS 2022 challenge provided a dataset of synthetic voice conversion and text-to-speech samples with subjective labels. This study looks at the amount of variance that can be explained in subjective ratings of speech quality from metadata and the distribution imbalances of the dataset. Speech quality models were constructed using wav2vec 2.0 with additional metadata features that included rater groups and system identifiers and obtained competitive metrics including a Spearman rank correlation coefficient (SRCC) of 0.934 and MSE of 0.088 at the system-level, and 0.877 and 0.198 at the utterance-level. Using data and metadata that the test restricted or blinded further improved the metrics. A metadata analysis showed that the system-level metrics do not represent the model's system-level prediction as a result of the wide variation in the number of utterances used for each system on the validation and test datasets. We conclude that, in general, conditions should have enough utterances in the test set to bound the sample mean error, and be relatively balanced in utterance count between systems, otherwise the utterance-level metrics may be more reliable and interpretable.
DNSMOS P.835: A Non-Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors
Oct 08, 2021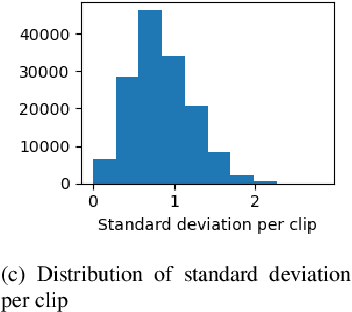
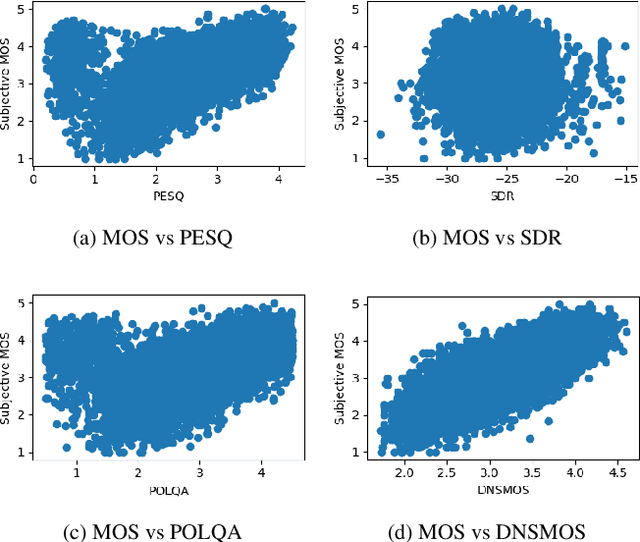
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. We have recently developed a non-intrusive speech quality metric called Deep Noise Suppression Mean Opinion Score (DNSMOS) using the scores from ITU-T Rec. P.808 subjective evaluation. The P.808 scores reflect the overall quality of the audio clip. ITU-T Rec. P.835 subjective evaluation framework gives the standalone quality scores of speech and background noise in addition to the overall quality. In this work, we train an objective metric based on P.835 human ratings that outputs 3 scores: i) speech quality (SIG), ii) background noise quality (BAK), and iii) the overall quality (OVRL) of the audio. The developed metric is highly correlated with human ratings, with a Pearson's Correlation Coefficient (PCC)=0.94 for SIG and PCC=0.98 for BAK and OVRL. This is the first non-intrusive P.835 predictor we are aware of. DNSMOS P.835 is made publicly available as an Azure service.
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.
DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality metric to evaluate Noise Suppressors
Oct 28, 2020Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. The conventional and widely used metrics require a reference clean speech signal, which is unavailable in real recordings. The no-reference approaches correlate poorly with human ratings and are not widely adopted in the research community. One of the biggest use cases of these perceptual objective metrics is to evaluate noise suppression algorithms. This paper introduces a multi-stage self-teaching based perceptual objective metric that is designed to evaluate noise suppressors. The proposed method generalizes well in challenging test conditions with a high correlation to human ratings.
Supervised Classifiers for Audio Impairments with Noisy Labels
Jul 03, 2019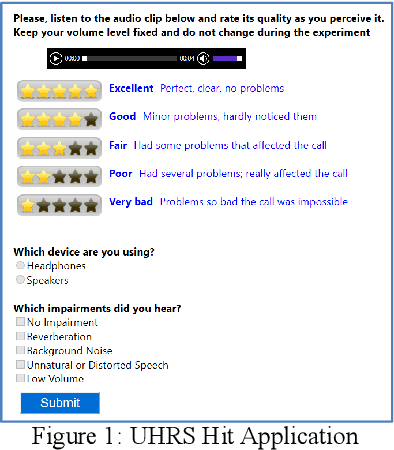
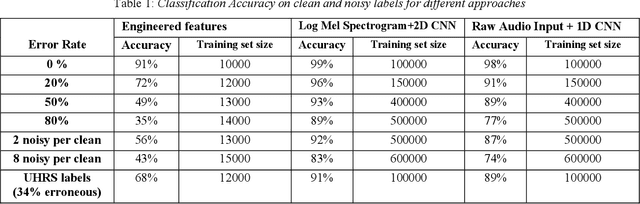
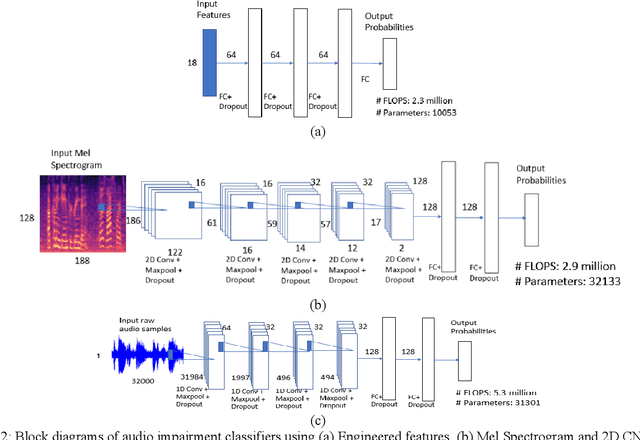
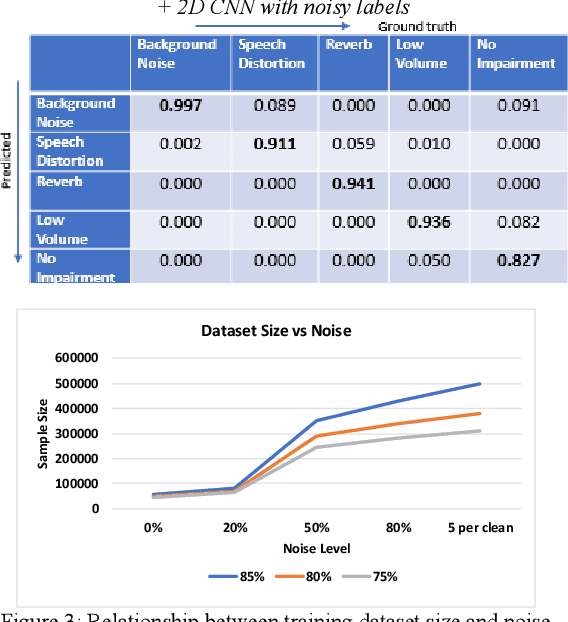
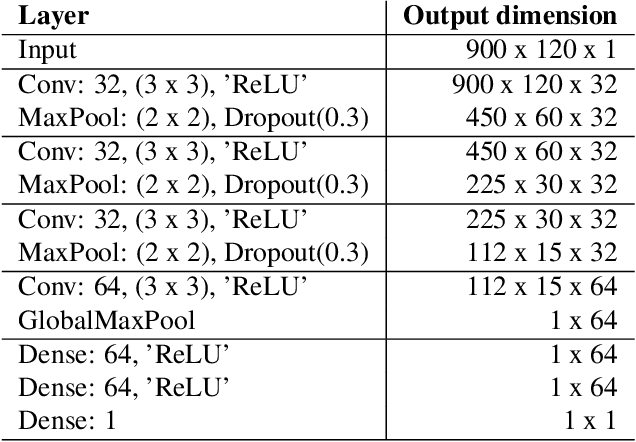
Voice-over-Internet-Protocol (VoIP) calls are prone to various speech impairments due to environmental and network conditions resulting in bad user experience. A reliable audio impairment classifier helps to identify the cause for bad audio quality. The user feedback after the call can act as the ground truth labels for training a supervised classifier on a large audio dataset. However, the labels are noisy as most of the users lack the expertise to precisely articulate the impairment in the perceived speech. In this paper, we analyze the effects of massive noise in labels in training dense networks and Convolutional Neural Networks (CNN) using engineered features, spectrograms and raw audio samples as inputs. We demonstrate that CNN can generalize better on the training data with a large number of noisy labels and gives remarkably higher test performance. The classifiers were trained both on randomly generated label noise and the label noise introduced by human errors. We also show that training with noisy labels requires a significant increase in the training dataset size, which is in proportion to the amount of noise in the labels.