 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Classifiers for Audio Impairments with Noisy Labels
Paper and Code
Jul 03, 2019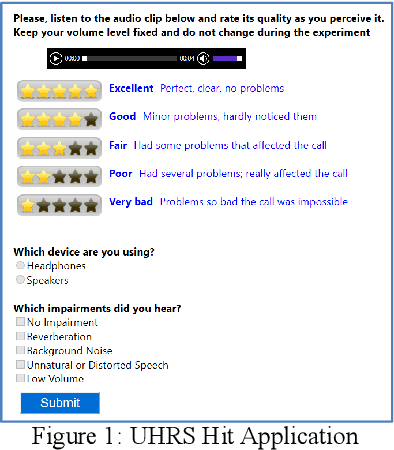
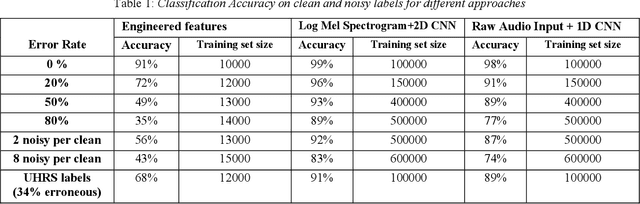
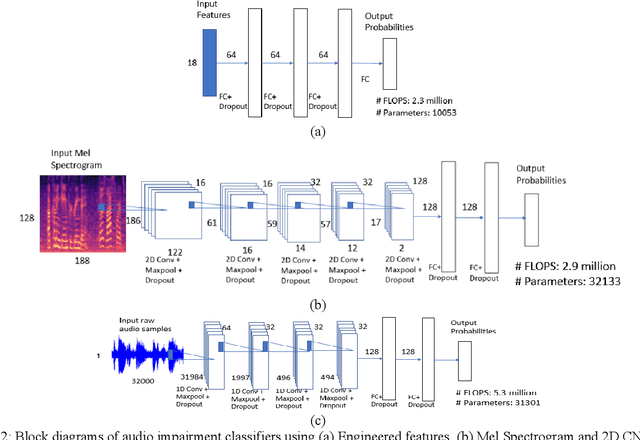
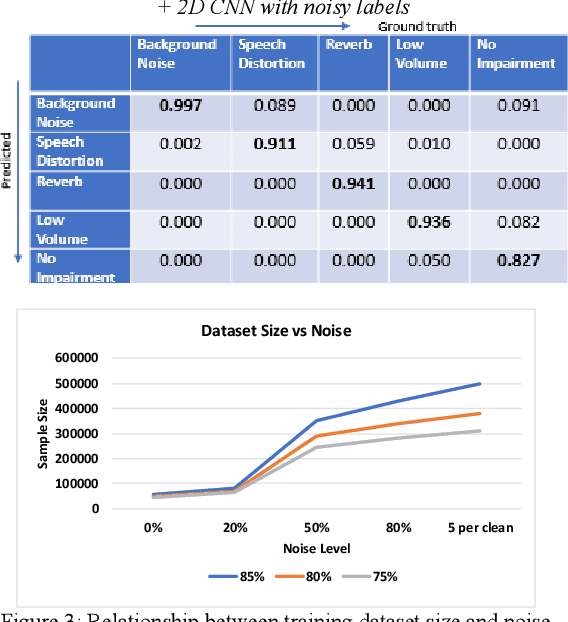
Voice-over-Internet-Protocol (VoIP) calls are prone to various speech impairments due to environmental and network conditions resulting in bad user experience. A reliable audio impairment classifier helps to identify the cause for bad audio quality. The user feedback after the call can act as the ground truth labels for training a supervised classifier on a large audio dataset. However, the labels are noisy as most of the users lack the expertise to precisely articulate the impairment in the perceived speech. In this paper, we analyze the effects of massive noise in labels in training dense networks and Convolutional Neural Networks (CNN) using engineered features, spectrograms and raw audio samples as inputs. We demonstrate that CNN can generalize better on the training data with a large number of noisy labels and gives remarkably higher test performance. The classifiers were trained both on randomly generated label noise and the label noise introduced by human errors. We also show that training with noisy labels requires a significant increase in the training dataset size, which is in proportion to the amount of noise in the labels.