 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Paper and Code
Sep 14, 2022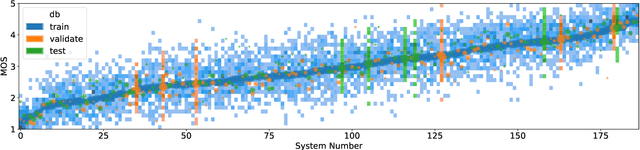
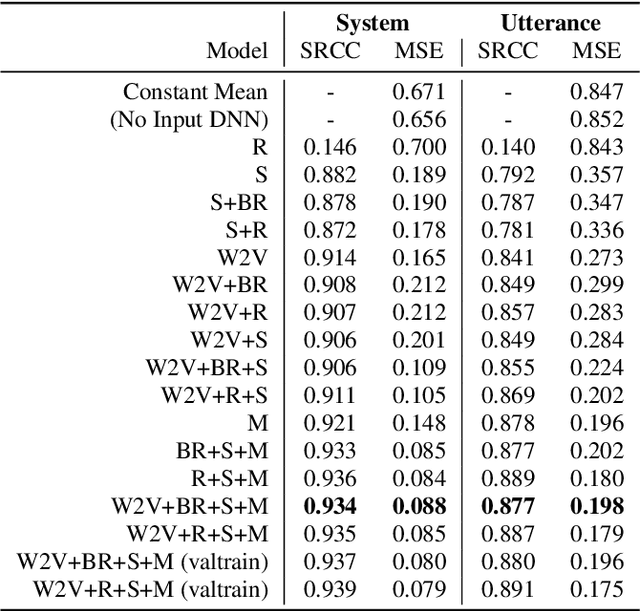
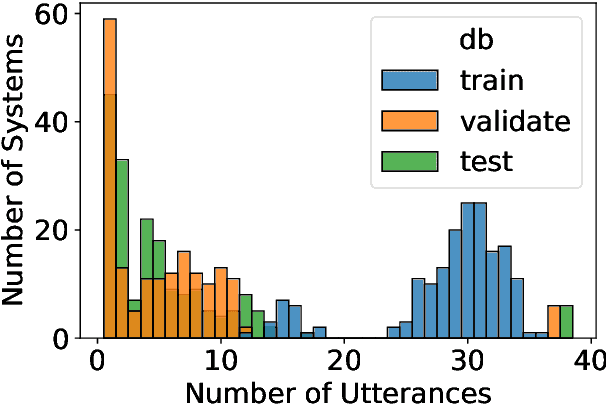
Non-reference speech quality models are important for a growing number of applications. The VoiceMOS 2022 challenge provided a dataset of synthetic voice conversion and text-to-speech samples with subjective labels. This study looks at the amount of variance that can be explained in subjective ratings of speech quality from metadata and the distribution imbalances of the dataset. Speech quality models were constructed using wav2vec 2.0 with additional metadata features that included rater groups and system identifiers and obtained competitive metrics including a Spearman rank correlation coefficient (SRCC) of 0.934 and MSE of 0.088 at the system-level, and 0.877 and 0.198 at the utterance-level. Using data and metadata that the test restricted or blinded further improved the metrics. A metadata analysis showed that the system-level metrics do not represent the model's system-level prediction as a result of the wide variation in the number of utterances used for each system on the validation and test datasets. We conclude that, in general, conditions should have enough utterances in the test set to bound the sample mean error, and be relatively balanced in utterance count between systems, otherwise the utterance-level metrics may be more reliable and interpretable.