 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards sub-millisecond latency real-time speech enhancement models on hearables
Sep 26, 2024

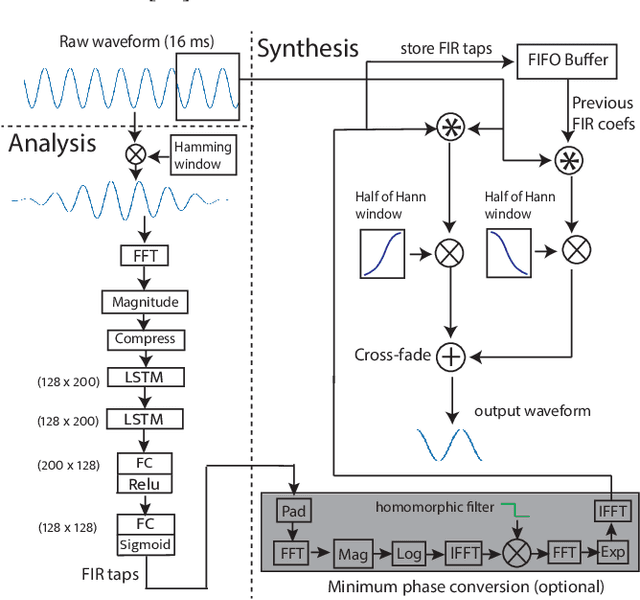
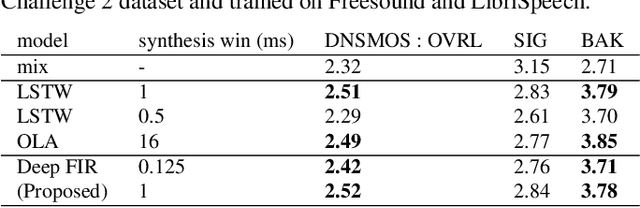
Low latency models are critical for real-time speech enhancement applications, such as hearing aids and hearables. However, the sub-millisecond latency space for resource-constrained hearables remains underexplored. We demonstrate speech enhancement using a computationally efficient minimum-phase FIR filter, enabling sample-by-sample processing to achieve mean algorithmic latency of 0.32 ms to 1.25 ms. With a single microphone, we observe a mean SI-SDRi of 4.1 dB. The approach shows generalization with a DNSMOS increase of 0.2 on unseen audio recordings. We use a lightweight LSTM-based model of 644k parameters to generate FIR taps. We benchmark that our system can run on low-power DSP with 388 MIPS and mean end-to-end latency of 3.35 ms. We provide a comparison with baseline low-latency spectral masking techniques. We hope this work will enable a better understanding of latency and can be used to improve the comfort and usability of hearables.