 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Conversation Relevance (TCR) Dataset and Benchmarks
Nov 04, 2024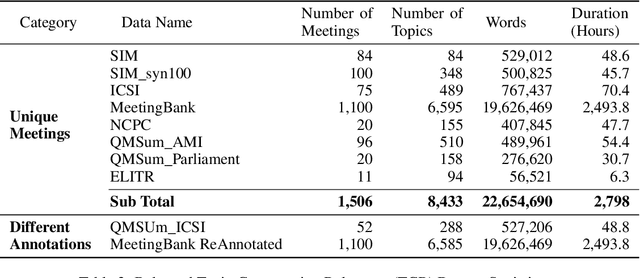

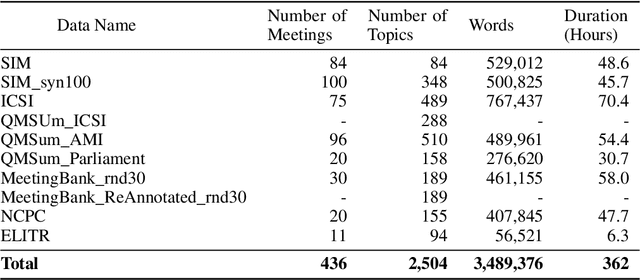
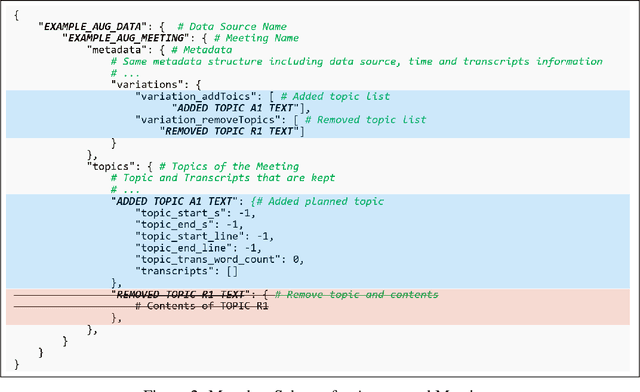
Workplace meetings are vital to organizational collaboration, yet a large percentage of meetings are rated as ineffective. To help improve meeting effectiveness by understanding if the conversation is on topic, we create a comprehensive Topic-Conversation Relevance (TCR) dataset that covers a variety of domains and meeting styles. The TCR dataset includes 1,500 unique meetings, 22 million words in transcripts, and over 15,000 meeting topics, sourced from both newly collected Speech Interruption Meeting (SIM) data and existing public datasets. Along with the text data, we also open source scripts to generate synthetic meetings or create augmented meetings from the TCR dataset to enhance data diversity. For each data source, benchmarks are created using GPT-4 to evaluate the model accuracy in understanding transcription-topic relevance.
Lumos: A Library for Diagnosing Metric Regressions in Web-Scale Applications
Jun 23, 2020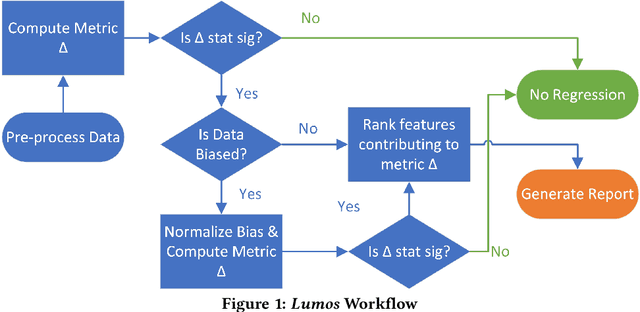
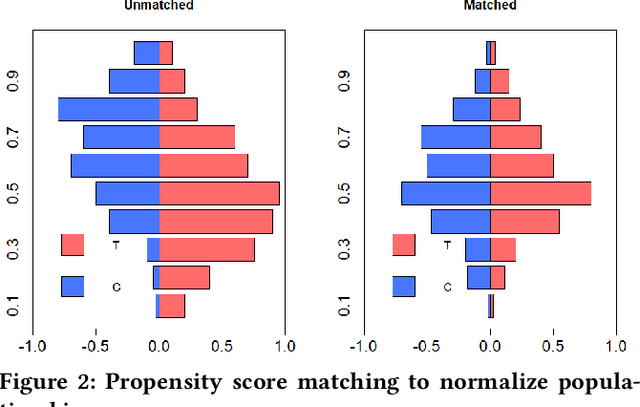
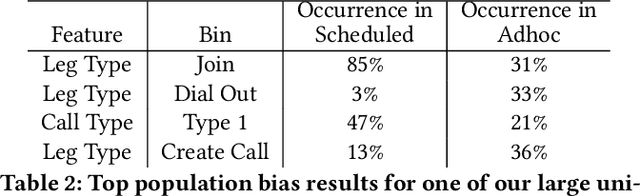
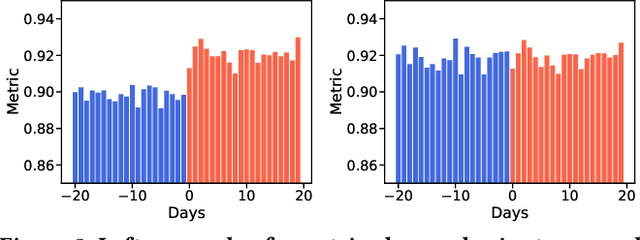
Web-scale applications can ship code on a daily to weekly cadence. These applications rely on online metrics to monitor the health of new releases. Regressions in metric values need to be detected and diagnosed as early as possible to reduce the disruption to users and product owners. Regressions in metrics can surface due to a variety of reasons: genuine product regressions, changes in user population, and bias due to telemetry loss (or processing) are among the common causes. Diagnosing the cause of these metric regressions is costly for engineering teams as they need to invest time in finding the root cause of the issue as soon as possible. We present Lumos, a Python library built using the principles of AB testing to systematically diagnose metric regressions to automate such analysis. Lumos has been deployed across the component teams in Microsoft's Real-Time Communication applications Skype and Microsoft Teams. It has enabled engineering teams to detect 100s of real changes in metrics and reject 1000s of false alarms detected by anomaly detectors. The application of Lumos has resulted in freeing up as much as 95% of the time allocated to metric-based investigations. In this work, we open source Lumos and present our results from applying it to two different components within the RTC group over millions of sessions. This general library can be coupled with any production system to manage the volume of alerting efficiently.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
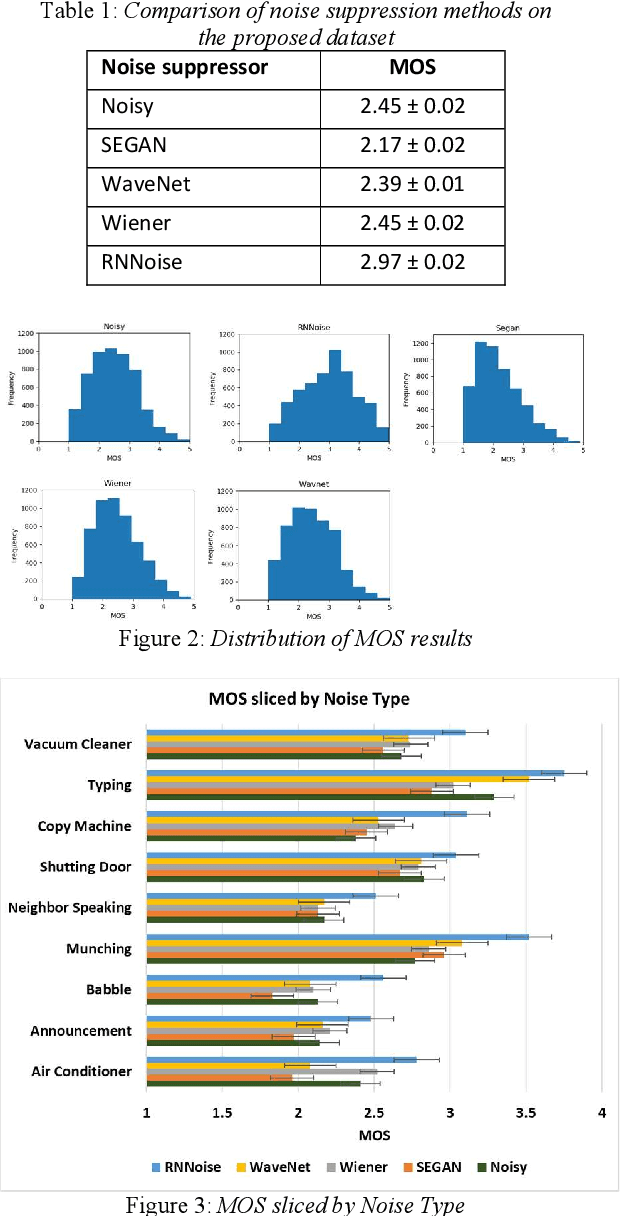
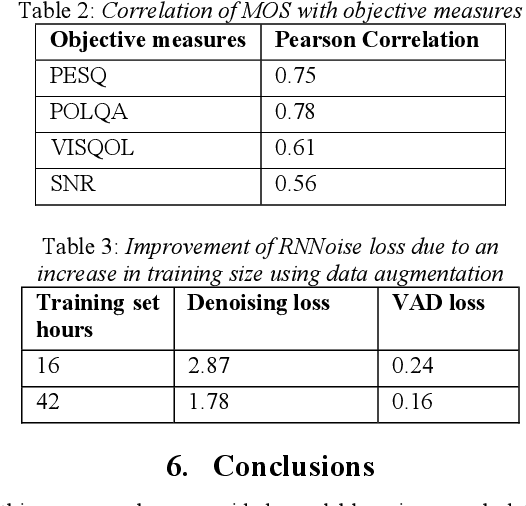
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.