 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Conversation Relevance (TCR) Dataset and Benchmarks
Nov 04, 2024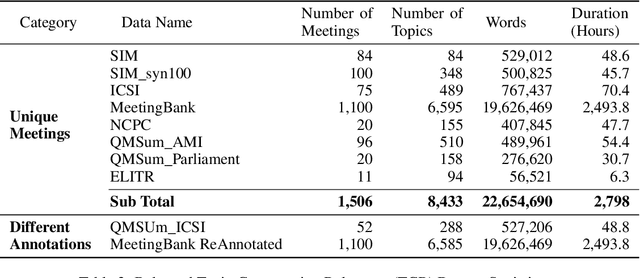

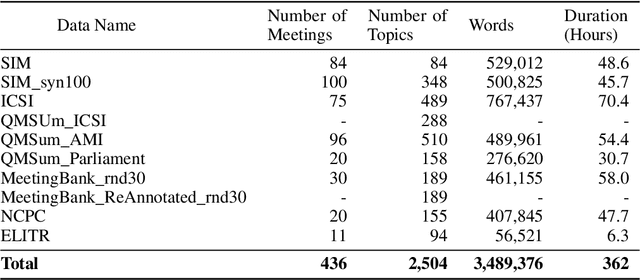
Workplace meetings are vital to organizational collaboration, yet a large percentage of meetings are rated as ineffective. To help improve meeting effectiveness by understanding if the conversation is on topic, we create a comprehensive Topic-Conversation Relevance (TCR) dataset that covers a variety of domains and meeting styles. The TCR dataset includes 1,500 unique meetings, 22 million words in transcripts, and over 15,000 meeting topics, sourced from both newly collected Speech Interruption Meeting (SIM) data and existing public datasets. Along with the text data, we also open source scripts to generate synthetic meetings or create augmented meetings from the TCR dataset to enhance data diversity. For each data source, benchmarks are created using GPT-4 to evaluate the model accuracy in understanding transcription-topic relevance.
Improving Meeting Inclusiveness using Speech Interruption Analysis
Apr 05, 2023

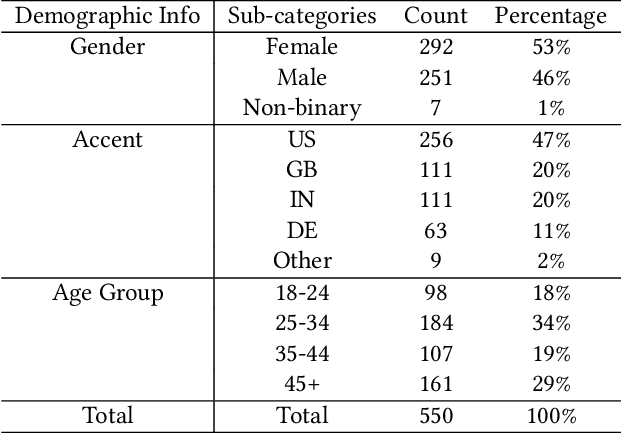
Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022



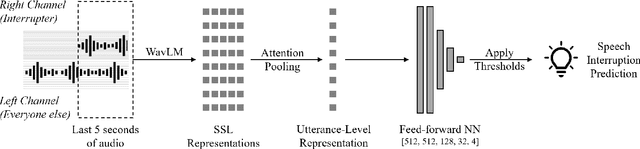
Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020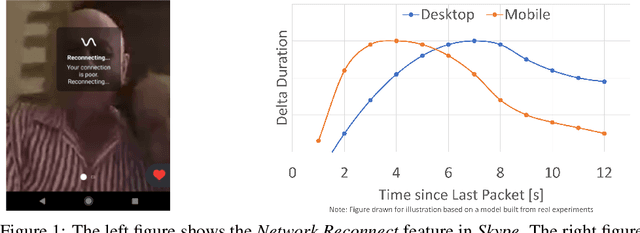


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments