 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Conversation Relevance (TCR) Dataset and Benchmarks
Nov 04, 2024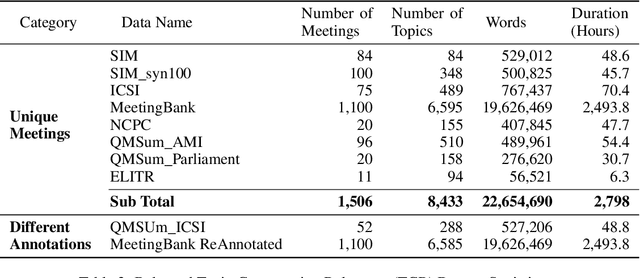

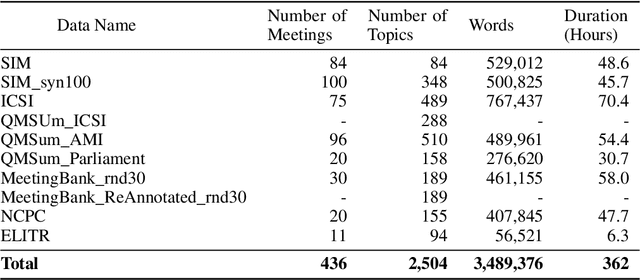
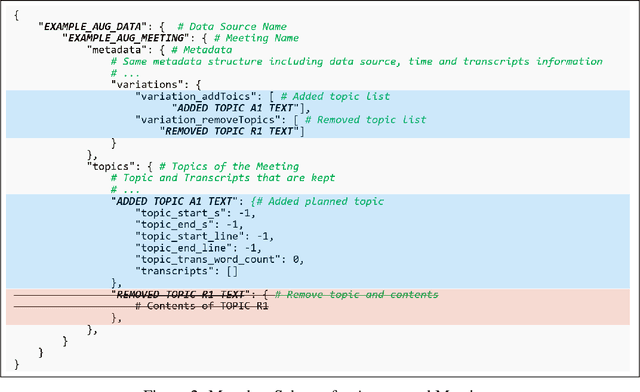
Workplace meetings are vital to organizational collaboration, yet a large percentage of meetings are rated as ineffective. To help improve meeting effectiveness by understanding if the conversation is on topic, we create a comprehensive Topic-Conversation Relevance (TCR) dataset that covers a variety of domains and meeting styles. The TCR dataset includes 1,500 unique meetings, 22 million words in transcripts, and over 15,000 meeting topics, sourced from both newly collected Speech Interruption Meeting (SIM) data and existing public datasets. Along with the text data, we also open source scripts to generate synthetic meetings or create augmented meetings from the TCR dataset to enhance data diversity. For each data source, benchmarks are created using GPT-4 to evaluate the model accuracy in understanding transcription-topic relevance.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020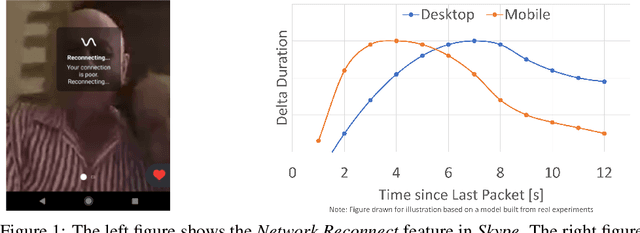


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Machine Learning at Microsoft with ML .NET
May 15, 2019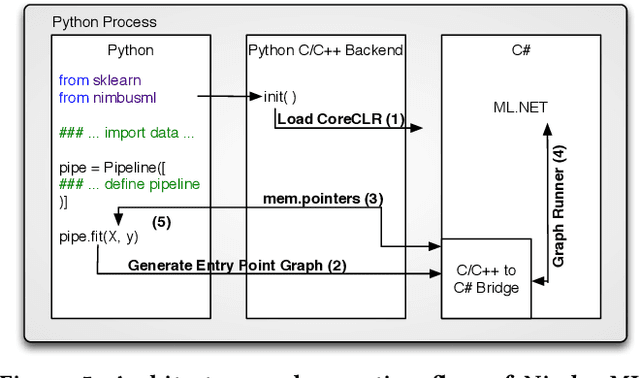
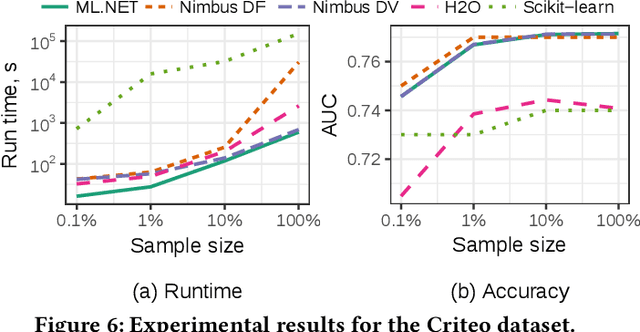
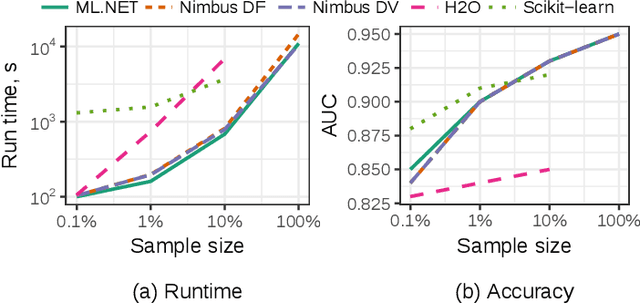
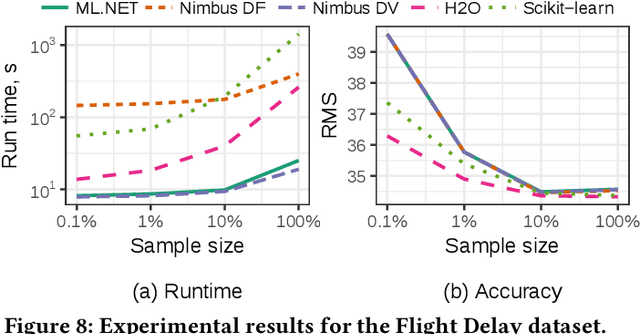
Machine Learning is transitioning from an art and science into a technology available to every developer. In the near future, every application on every platform will incorporate trained models to encode data-based decisions that would be impossible for developers to author. This presents a significant engineering challenge, since currently data science and modeling are largely decoupled from standard software development processes. This separation makes incorporating machine learning capabilities inside applications unnecessarily costly and difficult, and furthermore discourage developers from embracing ML in first place. In this paper we present ML .NET, a framework developed at Microsoft over the last decade in response to the challenge of making it easy to ship machine learning models in large software applications. We present its architecture, and illuminate the application demands that shaped it. Specifically, we introduce DataView, the core data abstraction of ML .NET which allows it to capture full predictive pipelines efficiently and consistently across training and inference lifecycles. We close the paper with a surprisingly favorable performance study of ML .NET compared to more recent entrants, and a discussion of some lessons learned.