 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMCodec: A Low Bitrate Speech Codec With Causal Transformer Models
Mar 23, 2023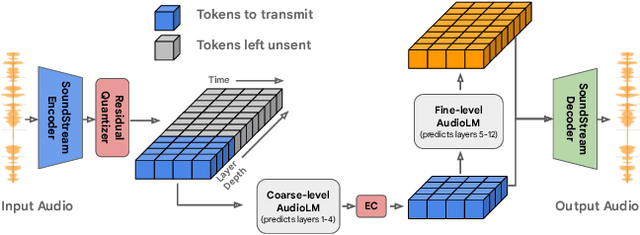
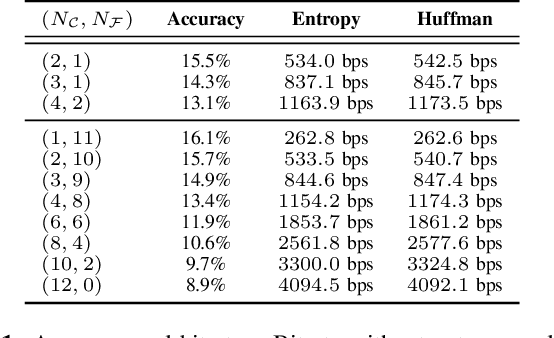
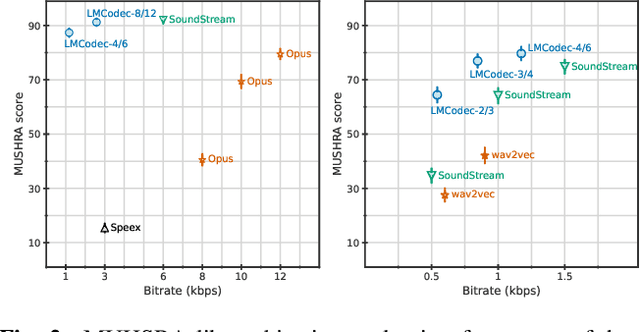
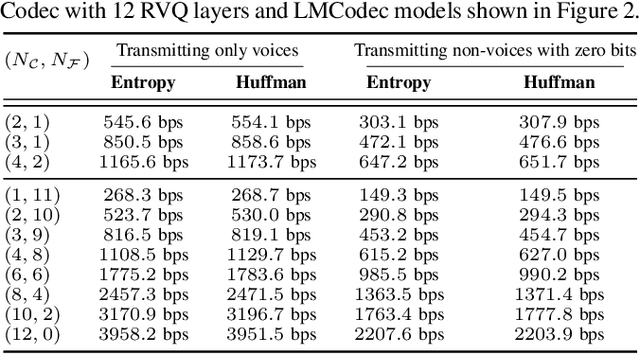
We introduce LMCodec, a causal neural speech codec that provides high quality audio at very low bitrates. The backbone of the system is a causal convolutional codec that encodes audio into a hierarchy of coarse-to-fine tokens using residual vector quantization. LMCodec trains a Transformer language model to predict the fine tokens from the coarse ones in a generative fashion, allowing for the transmission of fewer codes. A second Transformer predicts the uncertainty of the next codes given the past transmitted codes, and is used to perform conditional entropy coding. A MUSHRA subjective test was conducted and shows that the quality is comparable to reference codecs at higher bitrates. Example audio is available at https://mjenrungrot.github.io/chrome-media-audio-papers/publications/lmcodec.
The Cone of Silence: Speech Separation by Localization
Oct 12, 2020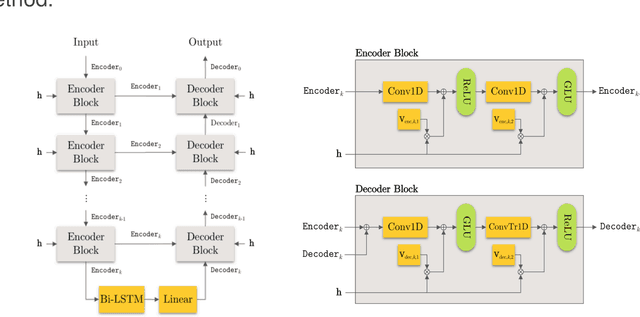
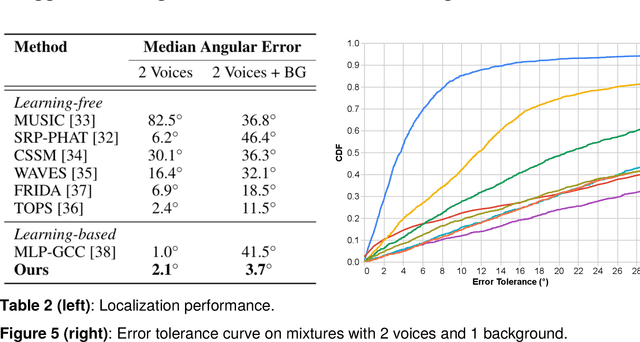
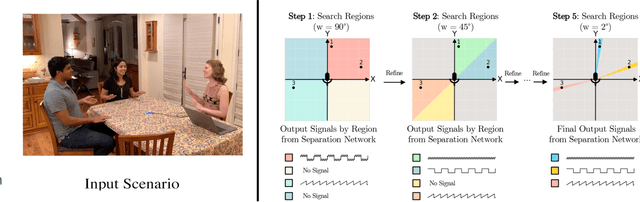
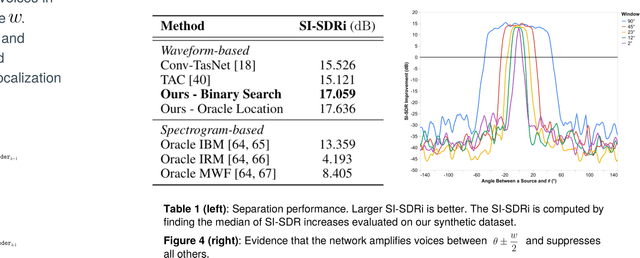
Given a multi-microphone recording of an unknown number of speakers talking concurrently, we simultaneously localize the sources and separate the individual speakers. At the core of our method is a deep network, in the waveform domain, which isolates sources within an angular region $\theta \pm w/2$, given an angle of interest $\theta$ and angular window size $w$. By exponentially decreasing $w$, we can perform a binary search to localize and separate all sources in logarithmic time. Our algorithm allows for an arbitrary number of potentially moving speakers at test time, including more speakers than seen during training. Experiments demonstrate state-of-the-art performance for both source separation and source localization, particularly in high levels of background noise.