 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Microphone Own Voice Detection based on Simulated Transfer Functions for Hearing Aids
Mar 03, 2026This paper presents a simulation-based approach to own voice detection (OVD) in hearing aids using a single microphone. While OVD can significantly improve user comfort and speech intelligibility, existing solutions often rely on multiple microphones or additional sensors, increasing device complexity and cost. To enable ML-based OVD without requiring costly transfer-function measurements, we propose a data augmentation strategy based on simulated acoustic transfer functions (ATFs) that expose the model to a wide range of spatial propagation conditions. A transformer-based classifier is first trained on analytically generated ATFs and then progressively fine-tuned using numerically simulated ATFs, transitioning from a rigid-sphere model to a detailed head-and-torso representation. This hierarchical adaptation enabled the model to refine its spatial understanding while maintaining generalization. Experimental results show 95.52% accuracy on simulated head-and-torso test data. Under short-duration conditions, the model maintained 90.02% accuracy with one-second utterances. On real hearing aid recordings, the model achieved 80% accuracy without fine-tuning, aided by lightweight test-time feature compensation. This highlights the model's ability to generalize from simulated to real-world conditions, demonstrating practical viability and pointing toward a promising direction for future hearing aid design.
High Quality Diffusion Distillation on a Single GPU with Relative and Absolute Position Matching
Mar 26, 2025We introduce relative and absolute position matching (RAPM), a diffusion distillation method resulting in high quality generation that can be trained efficiently on a single GPU. Recent diffusion distillation research has achieved excellent results for high-resolution text-to-image generation with methods such as phased consistency models (PCM) and improved distribution matching distillation (DMD2). However, these methods generally require many GPUs (e.g.~8-64) and significant batchsizes (e.g.~128-2048) during training, resulting in memory and compute requirements that are beyond the resources of some researchers. RAPM provides effective single-GPU diffusion distillation training with a batchsize of 1. The new method attempts to mimic the sampling trajectories of the teacher model by matching the relative and absolute positions. The design of relative positions is inspired by PCM. Two discriminators are introduced accordingly in RAPM, one for matching relative positions and the other for absolute positions. Experimental results on StableDiffusion (SD) V1.5 and SDXL indicate that RAPM with 4 timesteps produces comparable FID scores as the best method with 1 timestep under very limited computational resources.
TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
Dec 31, 2023Within recent approaches to text-to-video (T2V) generation, achieving controllability in the synthesized video is often a challenge. Typically, this issue is addressed by providing low-level per-frame guidance in the form of edge maps, depth maps, or an existing video to be altered. However, the process of obtaining such guidance can be labor-intensive. This paper focuses on enhancing controllability in video synthesis by employing straightforward bounding boxes to guide the subject in various ways, all without the need for neural network training, finetuning, optimization at inference time, or the use of pre-existing videos. Our algorithm, TrailBlazer, is constructed upon a pre-trained (T2V) model, and easy to implement. The subject is directed by a bounding box through the proposed spatial and temporal attention map editing. Moreover, we introduce the concept of keyframing, allowing the subject trajectory and overall appearance to be guided by both a moving bounding box and corresponding prompts, without the need to provide a detailed mask. The method is efficient, with negligible additional computation relative to the underlying pre-trained model. Despite the simplicity of the bounding box guidance, the resulting motion is surprisingly natural, with emergent effects including perspective and movement toward the virtual camera as the box size increases.
Exact Diffusion Inversion via Bi-directional Integration Approximation
Jul 21, 2023



Recently, different methods have been proposed to address the inconsistency issue of DDIM inversion to enable image editing, such as EDICT \cite{Wallace23EDICT} and Null-text inversion \cite{Mokady23NullTestInv}. However, the above methods introduce considerable computational overhead. In this paper, we propose a new technique, named \emph{bi-directional integration approximation} (BDIA), to perform exact diffusion inversion with neglible computational overhead. Suppose we would like to estimate the next diffusion state $\boldsymbol{z}_{i-1}$ at timestep $t_i$ with the historical information $(i,\boldsymbol{z}_i)$ and $(i+1,\boldsymbol{z}_{i+1})$. We first obtain the estimated Gaussian noise $\hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i)$, and then apply the DDIM update procedure twice for approximating the ODE integration over the next time-slot $[t_i, t_{i-1}]$ in the forward manner and the previous time-slot $[t_i, t_{t+1}]$ in the backward manner. The DDIM step for the previous time-slot is used to refine the integration approximation made earlier when computing $\boldsymbol{z}_i$. One nice property with BDIA-DDIM is that the update expression for $\boldsymbol{z}_{i-1}$ is a linear combination of $(\boldsymbol{z}_{i+1}, \boldsymbol{z}_i, \hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i))$. This allows for exact backward computation of $\boldsymbol{z}_{i+1}$ given $(\boldsymbol{z}_i, \boldsymbol{z}_{i-1})$, thus leading to exact diffusion inversion. Experiments on both image reconstruction and image editing were conducted, confirming our statement. BDIA can also be applied to improve the performance of other ODE solvers in addition to DDIM. In our work, it is found that applying BDIA to the EDM sampling procedure produces slightly better FID score over CIFAR10.
On Accelerating Diffusion-Based Sampling Process via Improved Integration Approximation
Apr 25, 2023



One popular diffusion-based sampling strategy attempts to solve the reverse ordinary differential equations (ODEs) effectively. The coefficients of the obtained ODE solvers are pre-determined by the ODE formulation, the reverse discrete timesteps, and the employed ODE methods. In this paper, we consider accelerating several popular ODE-based sampling processes by optimizing certain coefficients via improved integration approximation (IIA). At each reverse timestep, we propose to minimize a mean squared error (MSE) function with respect to certain selected coefficients. The MSE is constructed by applying the original ODE solver for a set of fine-grained timesteps which in principle provides a more accurate integration approximation in predicting the next diffusion hidden state. Given a pre-trained diffusion model, the procedure for IIA for a particular number of neural functional evaluations (NFEs) only needs to be conducted once over a batch of samples. The obtained optimal solutions for those selected coefficients via minimum MSE (MMSE) can be restored and reused later on to accelerate the sampling process. Extensive experiments on EDM and DDIM show the IIA technique leads to significant performance gain when the numbers of NFEs are small.
Lookahead Diffusion Probabilistic Models for Refining Mean Estimation
Apr 22, 2023We propose lookahead diffusion probabilistic models (LA-DPMs) to exploit the correlation in the outputs of the deep neural networks (DNNs) over subsequent timesteps in diffusion probabilistic models (DPMs) to refine the mean estimation of the conditional Gaussian distributions in the backward process. A typical DPM first obtains an estimate of the original data sample $\boldsymbol{x}$ by feeding the most recent state $\boldsymbol{z}_i$ and index $i$ into the DNN model and then computes the mean vector of the conditional Gaussian distribution for $\boldsymbol{z}_{i-1}$. We propose to calculate a more accurate estimate for $\boldsymbol{x}$ by performing extrapolation on the two estimates of $\boldsymbol{x}$ that are obtained by feeding $(\boldsymbol{z}_{i+1},i+1)$ and $(\boldsymbol{z}_{i},i)$ into the DNN model. The extrapolation can be easily integrated into the backward process of existing DPMs by introducing an additional connection over two consecutive timesteps, and fine-tuning is not required. Extensive experiments showed that plugging in the additional connection into DDPM, DDIM, DEIS, S-PNDM, and high-order DPM-Solvers leads to a significant performance gain in terms of FID score.
LMCodec: A Low Bitrate Speech Codec With Causal Transformer Models
Mar 23, 2023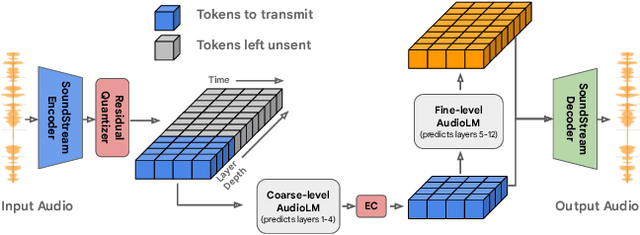
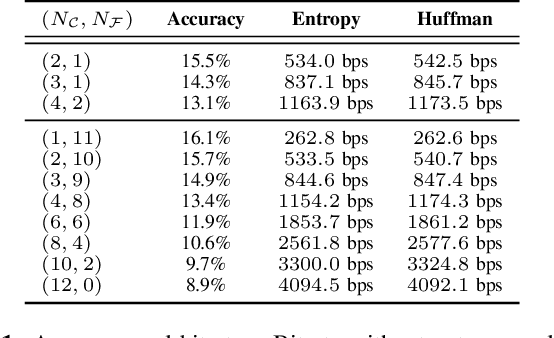
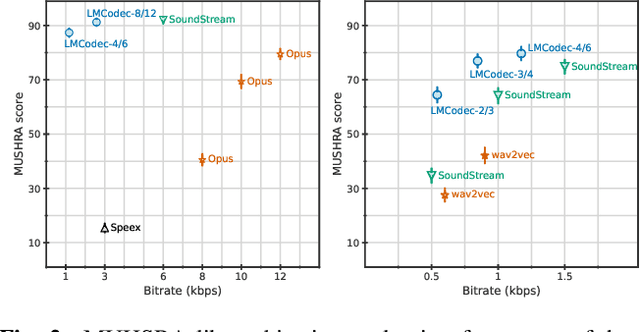
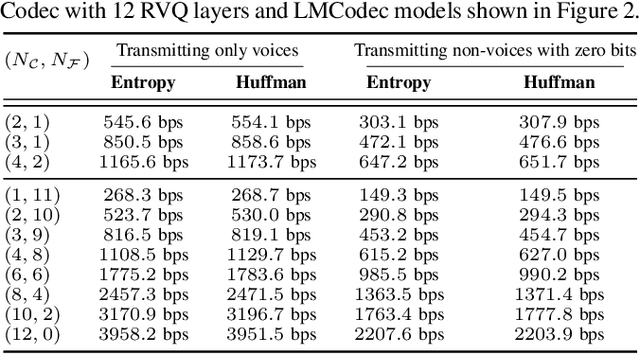
We introduce LMCodec, a causal neural speech codec that provides high quality audio at very low bitrates. The backbone of the system is a causal convolutional codec that encodes audio into a hierarchy of coarse-to-fine tokens using residual vector quantization. LMCodec trains a Transformer language model to predict the fine tokens from the coarse ones in a generative fashion, allowing for the transmission of fewer codes. A second Transformer predicts the uncertainty of the next codes given the past transmitted codes, and is used to perform conditional entropy coding. A MUSHRA subjective test was conducted and shows that the quality is comparable to reference codecs at higher bitrates. Example audio is available at https://mjenrungrot.github.io/chrome-media-audio-papers/publications/lmcodec.
Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Feb 25, 2023Text-guided diffusion models such as DALLE-2, IMAGEN, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are very high quality as well. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. Unfortunately, this capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work we take a particularly straightforward approach to providing the needed direction, by injecting ``activation'' at desired positions in the cross-attention maps corresponding to the objects under control, while attenuating the remainder of the map. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. To the best of our knowledge, our Directed Diffusion method is the first diffusion technique that provides positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
Estimation of Source and Receiver Positions, Room Geometry and Reflection Coefficients From a Single Room Impulse Response
Jan 22, 2023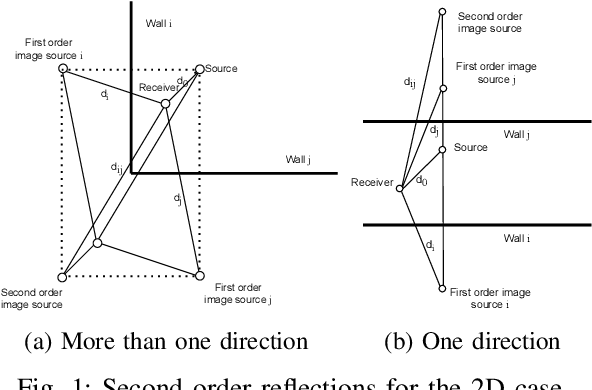
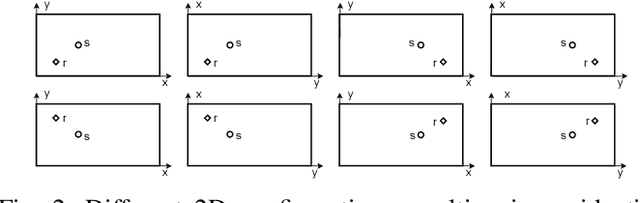
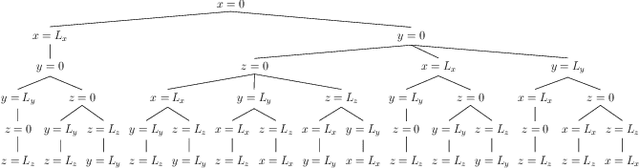
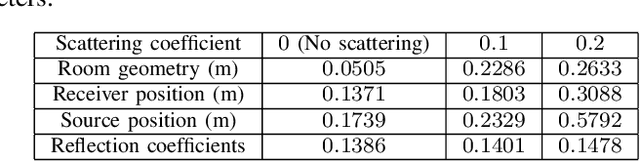
We propose an algorithm to estimate source and receiver positions, room geometry and reflection coefficients from a single room impulse response simultaneously. It is based on a symmetry analysis of the room impulse response. The proposed method utilizes the times of arrivals of the direct path, first order reflections and second order reflections. The proposed method is robust to erroneous pulses and non-specular reflections. It can be applied to any room with parallel walls as long as the required arrival times of reflections are available. In contrast to the state-of-art method, we do not restrict the location of source and receiver.
Ultra-Low-Bitrate Speech Coding with Pretrained Transformers
Jul 05, 2022
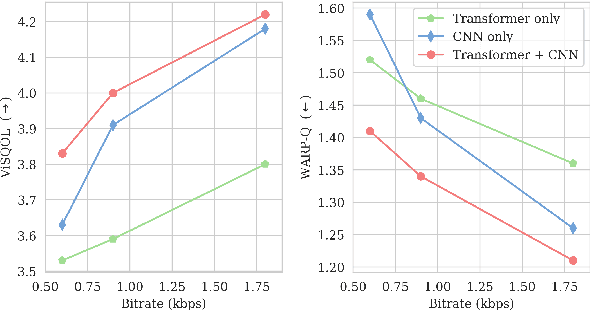
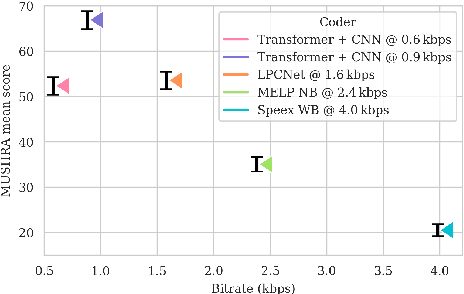
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.